yolov5模型训练流程
Posted kuokay
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了yolov5模型训练流程相关的知识,希望对你有一定的参考价值。
yolov5简介
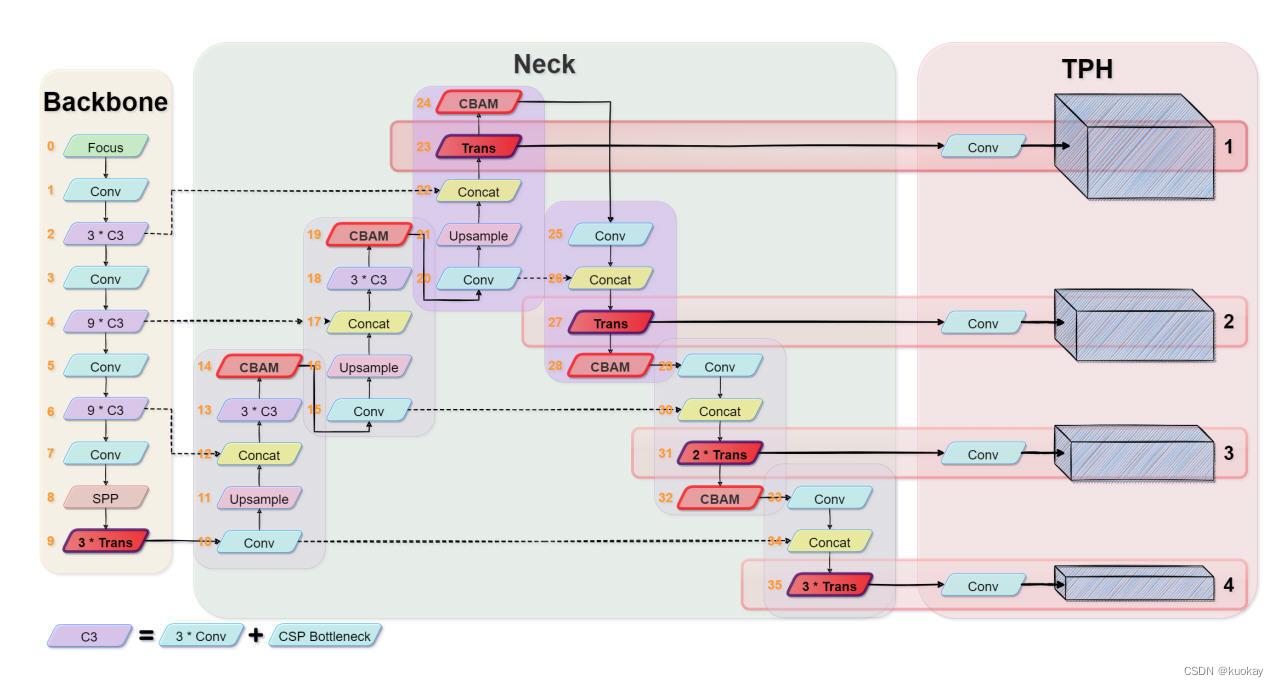
YOLOv5(You Only Look Once)是由 UitralyticsLLC公司发布的一种单阶段目标检测算
法,YOLOv5 相比YOLOv4 而言,在检测平均精度降低不多的基础上,具有均值权重文件更小,训练时间和推理速度更短的特点。YOLOv5 的网络结构分为输入端、BackboneNeck、Head 四个部分。
输入端主要包括 Mosaic 数据增强、图片尺寸处理以及自适应锚框计算三部分。Mosaic数据增强将四张图片进行组合,达到丰富图片背景的效果;图片尺寸处理对不同长宽的原始图像自适应的添加最少的黑边,统一缩放为标准尺寸;自适应锚框计算在初始锚框的基础上,将输出预测框与真实框进行比对,计算差距后再反向更新,不断迭代参数来获取最合适的锚框值。
Backbone 主要包含了 BottleneckCSP和 Focus 模块。BottleneckCSP 模块在增
强整个卷积神经网络学习性能的同时大幅减少了计算量;Focus 模块对图片进行切片操作,将输入通道扩充为原来的 4 倍,并经过一次卷积得到下采样特征图,在实现下采样的同时减少了计算量并提升了速度,具体操作如下图 所示。
Neck 中采用了 FPN 与 PAN 结合的结构,将常规的 FPN 层与自底向上的特征金字塔进行结合,将所提取的语义特征与位置特征进行融合,同时将主干层与检测层进行特征融合,使模型获取更加丰富的特征信息。
Head 输出一个向量,该向量具有目标对象的类别概率、对象得分和该对象边界框的位置。检测网络由三层检测层组成,不同尺寸的特征图用于检测不同尺寸的目标对象。每个检测层输出相应的向量,最后生成原图像中目标的预测边界框和类别并进行标记。
训练流程
模型下载
进入github官网,压缩包下载或git clone下载
git clone https://github.com/ultralytics/yolov5
文件说明

- data主要放置相关训练数据的配置文件(读取、解析等);
- models放置各模型的参数配置文件;
- weights则放置预训练模型的权重文件;
- inference放置预测/推理阶段的测试图片;
- runs则放置训练过程中保留下来的一些数据;
- train.py 模型训练文件
- test.py 模型测试文件
- detect.py 模型推理文件
依赖安装
进入yolov5项目文件夹,安装模块

cd yolov5-master
pip install -r requirement.txt
准备数据集(这里采用自己准备的数据)
数据标注
第一种手工标注
模型标注有很多软件,这里采用labelImg软件进行标注
-
软件下载
pip install PyQt5 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install pyqt5-tools -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install labelImg -i https://pypi.tuna.tsinghua.edu.cn/simple/ -
打开labelImg
在你所下载的环境中,输入:labelImg #注意大小写
打开后如下图
-
使用软件标注
界面说明

使用流程: opendir(打开文件)------------》选择yolo标注格式-----------》打标签-------》保存打标签:
点击Create RectBo -> 拖拽鼠标框选目标 -> 给上标签 -> 点击ok。注:若要删除目标,右键目标区域,delete即可

第二种半自动标注
将部分打完标签的数据利用YOLOV5模型进行训练,利用训练好的权重进行未标注图像的自动打标签功能,标注错误或漏标的框可以在LabelImg中手动调整。
流程:
- 使用yolov5官方权重进行推理得到box的坐标,如果你需要标注的类别在coco80个类里面(或者根据自己数据集用少量数据训练出来还不错的权重)
- 将box坐标和类别提取出来新建重写xml文件;
- 使用labelimg进行微调。
参考:https://blog.csdn.net/qq_39056987/article/details/111030600
参考:https://blog.csdn.net/qq_38246065/article/details/126934697
数据集划分
训练自己的yolov5检测模型的时候,数据集需要划分为训练集和验证集。如果数据格式是xml的,需要转为txt格式(yolov5格式)
-
创建文件夹(可跟据自己的项目调整)
其中Annotations文件夹中是标注文件,JPEGLmages中是图片文件


-
在VOC2007创建ImageSets文件夹,以及split_train_val.py脚本进行数据划分
import os import random trainval_percent = 0.9 # 训练集和验证集一共占所有数据的90% train_percent = 0.9 # 训练集占训练集和验证集的90% xmlfilepath = 'JPEGImages' txtsavepath = 'ImageSets' total_xml = os.listdir(xmlfilepath) num = len(total_xml) list = range(num) tv = int(num * trainval_percent) tr = int(tv * train_percent) trainval = random.sample(list, tv) #从所有list中返回tv个数量的项目 train = random.sample(trainval, tr) if not os.path.exists('ImageSets/'): os.makedirs('ImageSets/') ftrainval = open('ImageSets/trainval.txt', 'w') ftest = open('ImageSets/test.txt', 'w') ftrain = open('ImageSets/train.txt', 'w') fval = open('ImageSets/val.txt', 'w') for i in list: name = total_xml[i][:-4] + '\\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close() ftrain.close() fval.close() ftest.close()执行脚本后在ImageSets文件夹下会出现四个文件

-
用来将所有的xml文件all_xml转为txt文件并存放到all_labels文件夹,并生成训练所需架构,在VOC2007目录下建立voc_label.py脚本文件。
# -*- coding=utf-8 -*- import xml.etree.ElementTree as ET import pickle import os import shutil from os import listdir, getcwd from os.path import join sets = ['train', 'val', 'test'] # 如果不需要test就不写 classes = ['car', 'supercar'] # 修改成自己数据集的类别 def convert(size, box): dw = 1. / size[0] dh = 1. / size[1] x = (box[0] + box[1]) / 2.0 y = (box[2] + box[3]) / 2.0 w = box[1] - box[0] h = box[3] - box[2] x = x * dw w = w * dw y = y * dh h = h * dh return (x, y, w, h) def convert_annotation(image_id): in_file = open('all_xml/%s.xml' % (image_id),encoding='utf-8') out_file = open('Annotations/%s.txt' % (image_id), 'w') tree = ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): difficult = obj.find('difficult').text cls = obj.find('name').text if cls not in classes or int(difficult) == 1: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w, h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\\n') wd = getcwd() print(wd) for image_set in sets: if not os.path.exists('Annotations/'): os.makedirs('Annotations/') image_ids = open('ImageSets/%s.txt' % (image_set),encoding='utf-8').read().strip().split() image_list_file = open('images_%s.txt' % (image_set), 'w',encoding='utf-8') labels_list_file=open('labels_%s.txt'%(image_set),'w',encoding='utf-8') for image_id in image_ids: image_list_file.write('%s.jpg\\n' % (image_id)) labels_list_file.write('%s.txt\\n'%(image_id)) # convert_annotation(image_id) #如果标签已经是txt格式,将此行注释掉,所有的txt存放到Annotations文件夹。 image_list_file.close() labels_list_file.close() def copy_file(new_path,path_txt,search_path):#参数1:存放新文件的位置 参数2:为上一步建立好的train,val训练数据的路径txt文件 参数3:为搜索的文件位置 if not os.path.exists(new_path): os.makedirs(new_path) with open(path_txt, 'r') as lines: filenames_to_copy = set(line.rstrip() for line in lines) # print('filenames_to_copy:',filenames_to_copy) # print(len(filenames_to_copy)) for root, _, filenames in os.walk(search_path): # print('root',root) # print(_) # print(filenames) for filename in filenames: if filename in filenames_to_copy: shutil.copy(os.path.join(root, filename), new_path) #按照划分好的训练文件的路径搜索目标,并将其复制到yolo格式下的新路径 copy_file('./images/train/','./images_train.txt','./JPEGImages') copy_file('./images/val/','./images_val.txt','./JPEGImages') copy_file('./images/test/','./images_test.txt','./JPEGImages') copy_file('./labels/train/','./labels_train.txt','./Annotations') copy_file('./labels/val/','./labels_val.txt','./Annotations') copy_file('./labels/test/','./labels_test.txt','./Annotations')执行后会出现图片和文本目录,如下

到处就数据集就创建完成了
模型训练
放入训练数据
在yolov5目录下新建一个目录,把之前划分的图片和文本拷贝之此目录下
下载预训练模型
预训练模型地址:https://github.com/ultralytics/yolov5/releases
选择你所需要的模型下载即可,这里我选择yolov5s.pt下载。
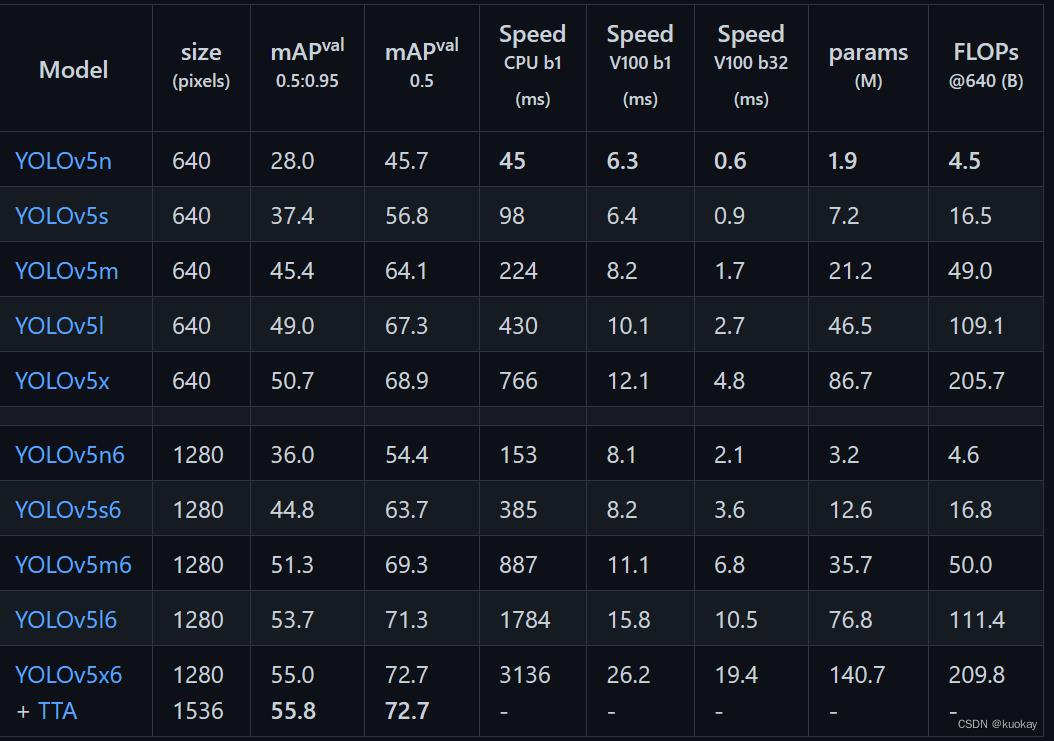
各个模型参数对比
下载好后将文件放到yolov5文件夹下
修改配置文件
修改数据配置文件
修改data目录下的相应的yaml文件。找到目录下的voc.yaml文件,将该文件复制一份,将复制的文件重命名,最好和项目相关,这样方便后面操作。我这里修改为car.yaml。
修改模型配置文件
由于该项目使用的是yolov5s.pt这个预训练权重,所以要使用models目录下的yolov5s.yaml文件中的相应参数(因为不同的预训练权重对应着不同的网络层数,所以用错预训练权重会报错)。同上修改data目录下的yaml文件一样,我们最好将yolov5s.yaml文件复制一份,然后将其重命名,我将其重命名为car.yaml。

训练自己的模型启用tensorbord查看参数
- 找到yolov5文件夹下的train.py文件,进行修改

然后找到主函数的入口,如下所示。
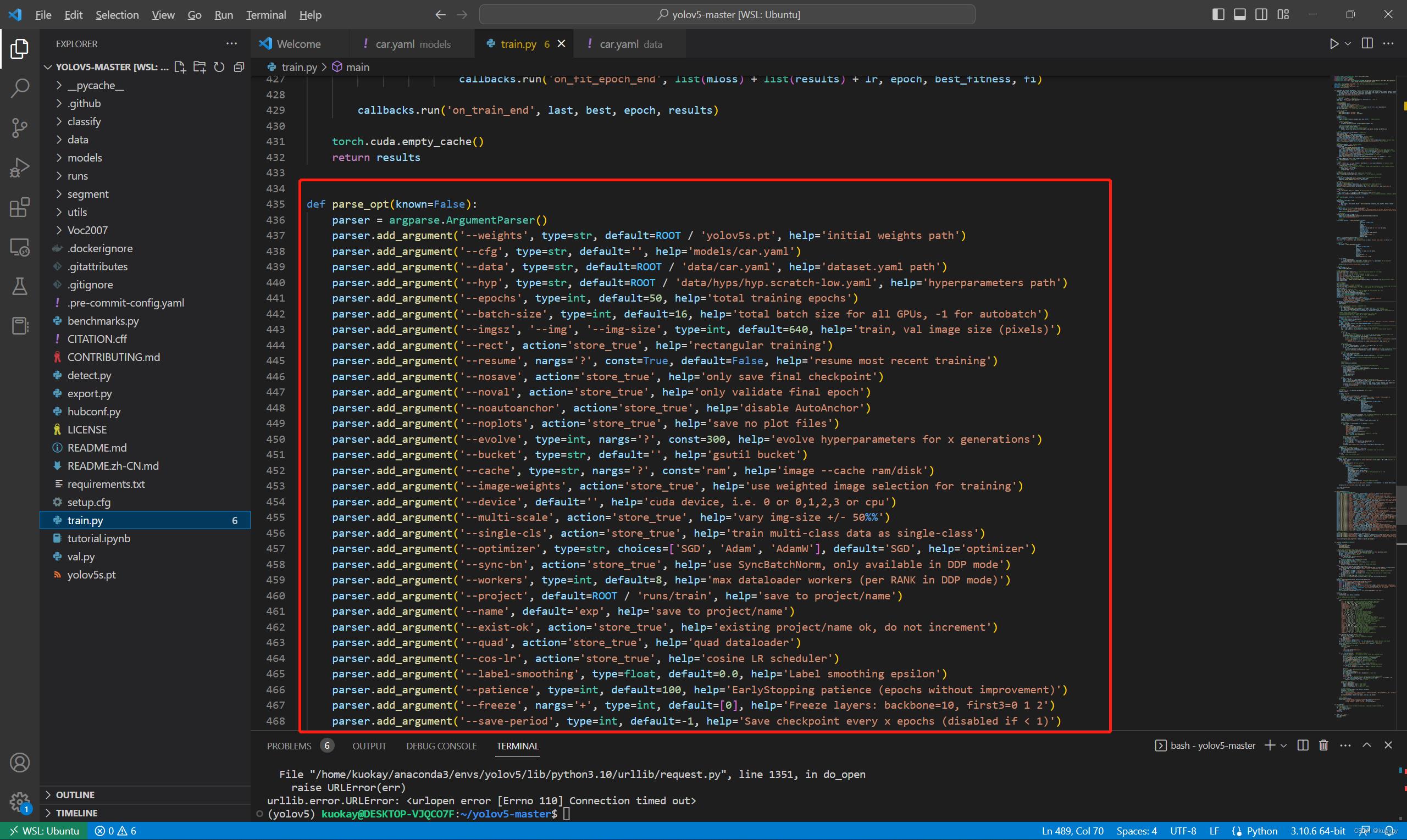
训练自己的模型需要修改如下几个参数就可以训练了。首先将weights权重的路径填写到对应的参数里面,然后将修好好的models模型的yolov5s.yaml文件路径填写到相应的参数里面,最后将data数据的hat.yaml文件路径填写到相对于的参数里面。

修改训练轮数和批次

模型参数解析

至此,就可以运行train.py函数训练自己的模型了。
启用tensorbord查看参数
yolov5里面有写好的tensorbord函数,可以运行命令就可以调用tensorbord,然后查看tensorbord了。首先打开pycharm的命令控制终端,输入如下命令,就会出现一个网址地址,将那行网址复制下来到浏览器打开就可以看到训练的过程了
tensorboard --logdir=runs/train

访问链接, 如下图所示
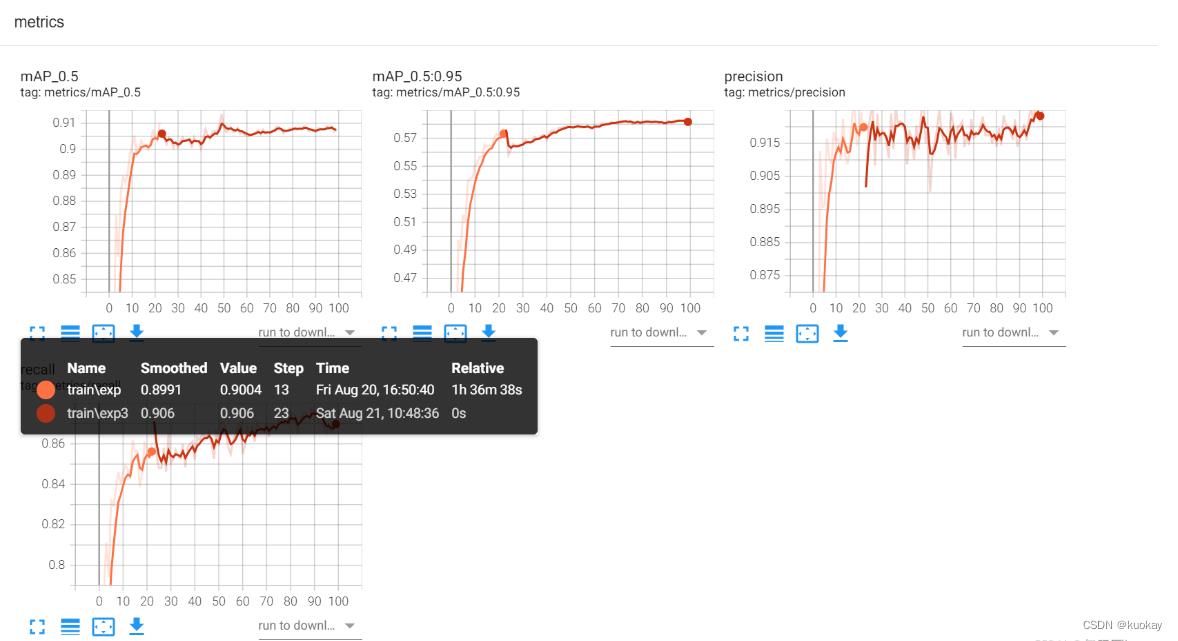
如果模型已经训练好了,但是我们还想用tensorbord查看此模型的训练过程,就需要输入如下的命令。就可以看到模型的训练结果了。
tensorboard --logdir=runs
以上是关于yolov5模型训练流程的主要内容,如果未能解决你的问题,请参考以下文章