视觉版ChatGPT来了!吸收AI画画全技能,MSRA全华人团队打造,微软16年老将领衔...
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视觉版ChatGPT来了!吸收AI画画全技能,MSRA全华人团队打造,微软16年老将领衔...相关的知识,希望对你有一定的参考价值。
明敏 发自 凹非寺
量子位 | 公众号 QbitAI
ChatGPT会画画了!

问它:能生成一张猫片给我吗?
立刻连文带图全有了。
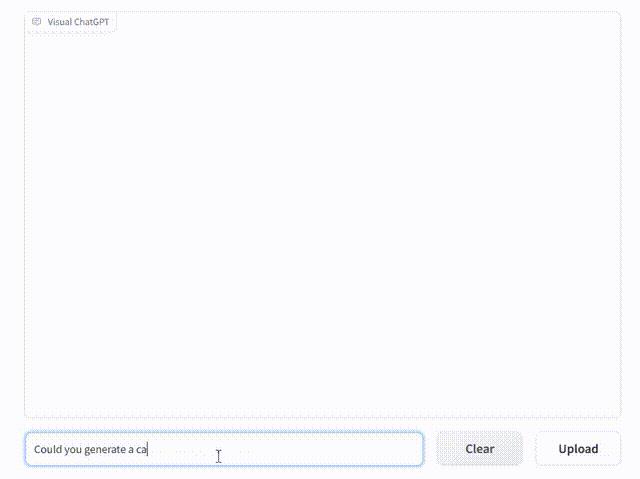
还能根据新的文字指令调整图片:把猫换成狗。
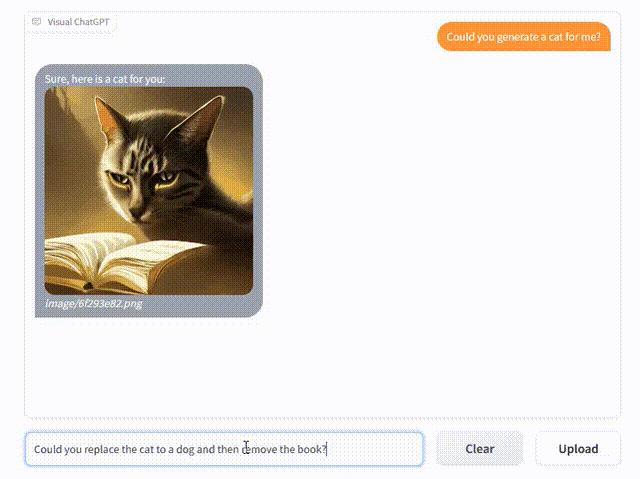
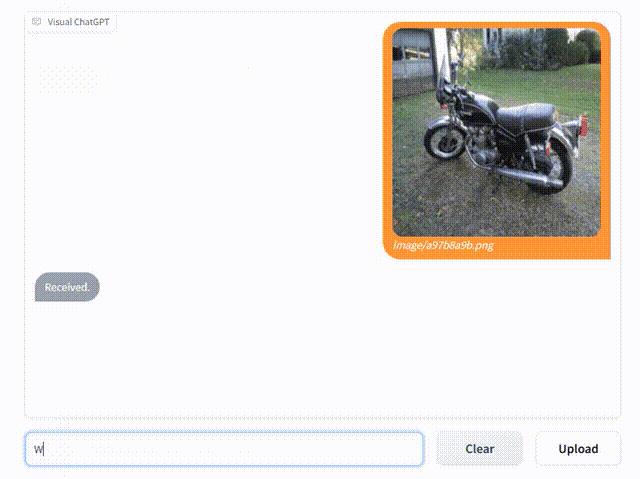
同时也看得懂图、有理解能力。
比如发一张图给它,然后问摩托是什么颜色?它能回答出是黑色。
如上,就是由MSRA资深研究人员们提出的视觉版ChatGPT(Visual ChatGPT)。
通过给ChatGPT结合多种视觉模型,并利用一个提示管理器(Prompt Manager),他们成功让ChatGPT可以处理各种视觉任务。
这项工作一发出来就火了,GitHub揽星已超过1.5k。
简单总结一下,就是把GPT和Dall-E合并的感觉~
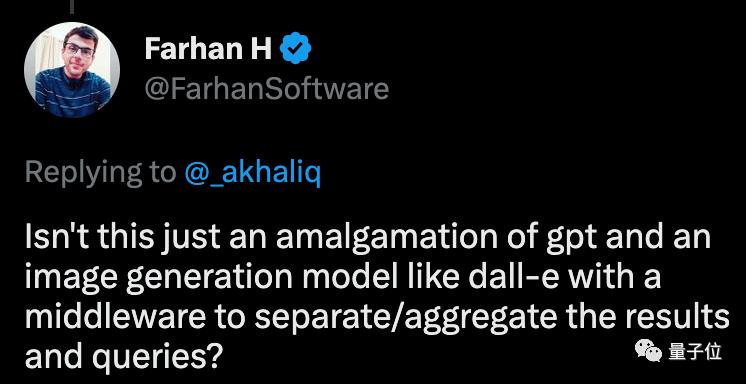
又懂文字又会画图……有人就说:
这不是终极meme图制造机?
诀窍在于提示工程?
Visual ChatGPT,其实就是让ChatGPT可以处理多模态信息。
但是从头训练一个多模态模型,工作量非常大。
研究人员想到可以在ChatGPT的基础上,结合一些视觉模型。
而想要达到这一目的,关键需要一个中间站。
由此他们提出了提示管理器(Prompt Manager)的概念。

它的作用主要有3方面:
第一、明确告诉ChatGPT,每个视觉模型的作用,并指定好输入输出格式。
第二、转换不同的视觉信息,如将PNG图像、深度图像、掩码矩阵等转换为语言格式,方便ChatGPT理解。
第三、处理视觉模型的历史生成结果,以及不同模型的调用优先级、规避冲突等,让ChatGPT能够以迭代的方式接收视觉模型的生成内容,直到输出用户满意的结果。
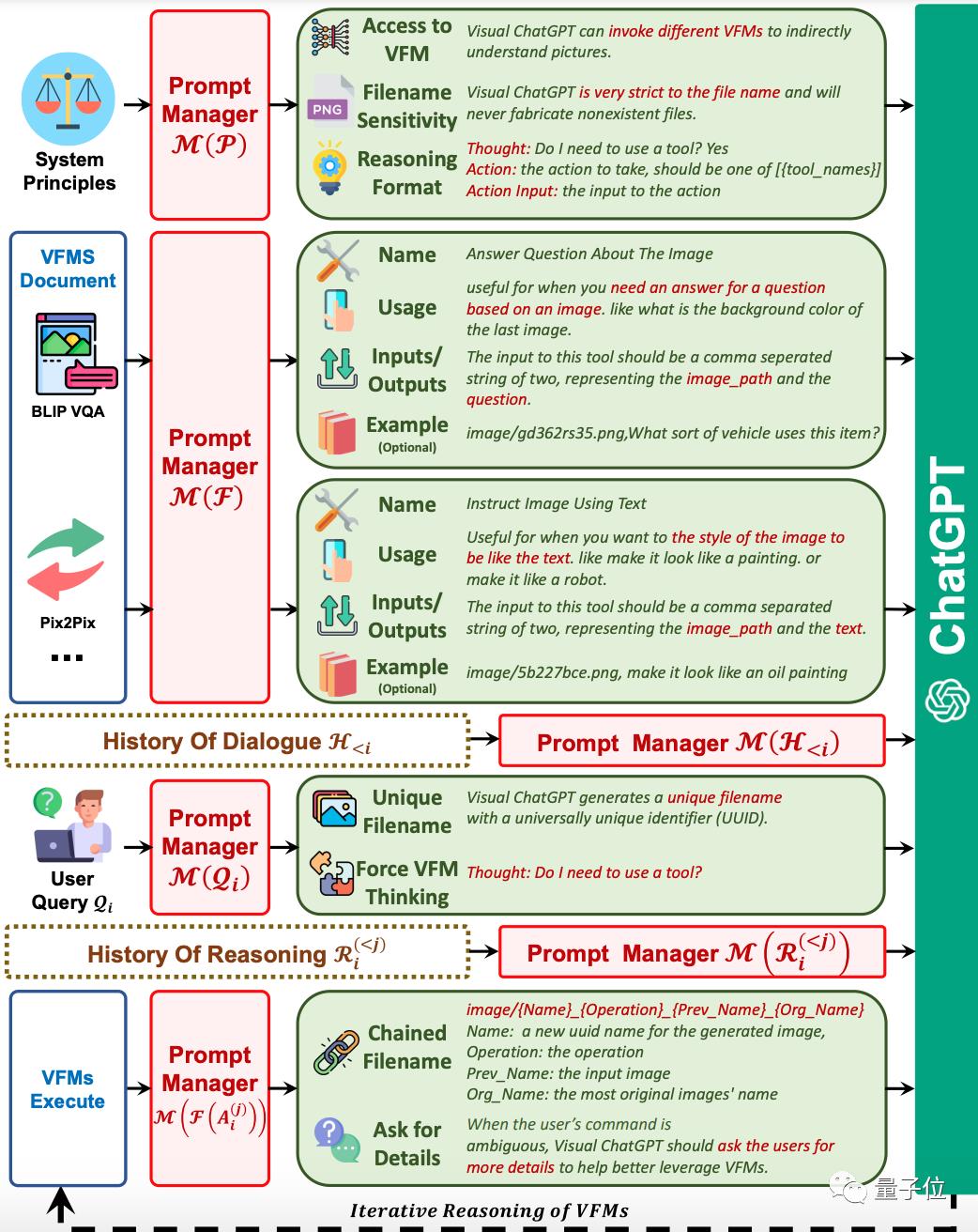
这样一来,Visual ChatGPT的工作流大概长这样:

假如用户输入了一张图,模型会先将内容发送给提示管理器,然后转换成语言给ChatGPT判断,当它发现这个问题不需要调用视觉模型,就会直接给出输出(第一个回答)。
第二个问题时,ChatGPT分析问题内容需要使用视觉模型,就会让视觉模型开始执行,然后一直迭代,直到ChatGPT判断不再需要调用视觉模型时,才会输出结果。
论文介绍,Visual ChatGPT中包含了22个不同的视觉模型。包括Stable Diffusion、BLIP、pix2pix等。
为了验证Visual ChatGPT的能力,他们还进行了大量零次试验(zero-shot experiments)。
结果如开头所示,Visual ChatGPT具备很强的图像理解能力。
可以一直按照人的需求不断生成、修改图片。

当然,研究人员也提到了这项工作目前还存在一些局限性。
比如生成结果的质量,主要取决于视觉模型的性能。
以及使用大量的提示工程,会一定程度上影响生成结果的速度。而且还可能同时调用多个模型,也会影响实时性。
最后,在输入图片的隐私安全上,还需要做进一步升级保护。
MSRA老将出马
本项研究成果来自微软亚洲研究院的团队。
通讯作者是段楠。

他是MSRA首席研究员,自然语言计算组研究经理,中国科学技术大学兼职博导,天津大学兼职教授,CCF杰出会员。
主要从事自然语言处理、代码智能、多模态智能、机器推理等研究。
2012年加入MSRA,任职已超10年。
第一作者Chenfei Wu,同样是一位资深研究人员了。
据领英资料显示,他于2020年加入微软,任职3年,目前是高级研究员。(下图有误)

论文地址:
https://arxiv.org/abs/2303.04671
参考链接:
https://twitter.com/_akhaliq/status/1633642479869198337
— 完 —
「中国AIGC产业峰会」启动
邀您共襄盛举
「中国AIGC产业峰会」即将在今年3月举办,峰会将邀请AIGC产业相关领域的专家学者,共同探讨生成新世界的过去、现在和未来。
峰会上还将发布《中国AIGC产业全景报告暨AIGC 50》,全面立体描绘我国当前AIGC产业的竞争力图谱。点击链接或下方图片查看大会详情:
被ChatGPT带飞的AIGC如何在中国落地?量子位邀你共同参与中国AIGC产业峰会

点这里👇关注我,记得标星哦~
以上是关于视觉版ChatGPT来了!吸收AI画画全技能,MSRA全华人团队打造,微软16年老将领衔...的主要内容,如果未能解决你的问题,请参考以下文章
阿里版ChatGPT已进入测试!中文聊天截图曝光,达摩院出品
阿里版ChatGPT已进入测试!中文聊天截图曝光,达摩院出品