『 MySQL篇 』:MySQL表的聚合与联合查询
Posted 署前街的少年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了『 MySQL篇 』:MySQL表的聚合与联合查询相关的知识,希望对你有一定的参考价值。
| 基础篇 | MySQL系列专栏(持续更新中 …) |
|---|---|
| 1 | 『 MySQL篇 』:库操作、数据类型 |
| 2 | 『 MySQL篇 』:MySQL表的CURD操作 |
| 3 | 『 MySQL篇 』:MySQL表的相关约束 |
| 4 | 『 mysql篇 』:MySQL表的聚合与联合查询 |
目录
一. 聚合查询
1.1 聚合函数
一般情况下,我们需要的聚合数据(总和,平均数,最大最小值等)并不总是存储在表中。 但是,可以通过执行存储数据的计算来获取它。
MySQL提供了许多聚合函数,包括AVG,COUNT,SUM,MIN,MAX等。除COUNT函数外,其它聚合函数在执行计算时会忽略NULL值 , 同时 , 聚合函数不允许嵌套使用 .
| 函数 | 说明 |
|---|---|
| count(列名或表达式) | 返回查询到的数据的个数 |
| sum(列名或表达式) | 返回查询到的数据的和, (不是数字没有意义) |
| avg(列名或表达式) | 返回查询到的数据的平均值 |
| max(列名或表达式) | 返回查询到的数据的最大值 |
| min(列名或表达式) | 返回查询到的数据的最小值 |
以上的聚合函数可以在列名和表达式之前加上
distinct, 先对查询到的数据进行去重, 再进行计算
下面,我们将创建一组示例数据,对以上的聚合函数进行演示,
--- 创建学生成绩表
mysql> create table exam(
-> id int primary key comment '学号',
-> name varchar(20) comment '学生姓名',
-> email varchar(50) not null comment '电子邮箱',
-> chinese decimal(4,1) comment '语文成绩',
-> english decimal(4,1) comment '英语成绩',
-> math decimal(4,1) comment'数学成绩'
-> );
Query OK, 0 rows affected (0.02 sec)
--- 插入学生成绩数据
mysql> insert into exam values(202301,'张华','123452@163.com',69,112,110),
-> (202302,'李三','1452563@163.com',115.5,120,89),
-> (202303,'宋七','36215465@qq.com',110,113,66),
-> (202304,'王五','15547522@163.com',89,65,78),
-> (202305,'赵四','15623355@163.com',90,112,130),
-> (202306,'李八','18625222@163.com',null,null,null);
Query OK, 6 rows affected (0.01 sec)
Records: 6 Duplicates: 0 Warnings: 0
---学生成绩表结构
mysql> desc exam;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
| email | varchar(50) | NO | | NULL | |
| chinese | decimal(4,1) | YES | | NULL | |
| english | decimal(4,1) | YES | | NULL | |
| math | decimal(4,1) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
6 rows in set (0.00 sec)
--- 数据详表
mysql> select * from exam;
+--------+------+------------------+---------+---------+-------+
| id | name | email | chinese | english | math |
+--------+------+------------------+---------+---------+-------+
| 202301 | 张华 | 123452@163.com | 69.0 | 112.0 | 110.0 |
| 202302 | 李三 | 1452563@163.com | 115.5 | 120.0 | 89.0 |
| 202303 | 宋七 | 36215465@qq.com | 110.0 | 113.0 | 66.0 |
| 202304 | 王五 | 15547522@163.com | 89.0 | 65.0 | 78.0 |
| 202305 | 赵四 | 15623355@163.com | 90.0 | 112.0 | 130.0 |
| 202306 | 李八 | 18625222@163.com | NULL | NULL | NULL |
+--------+------+------------------+---------+---------+-------+
6 rows in set (0.01 sec)
count()函数
使用 count()函数 可以返回数据表中的行数 , 允许对表中所有符合特定条件的所有行进行计数 .
#计算表中的总行数
mysql> select count(*) from exam;
+----------+
| count(*) |
+----------+
| 6 |
+----------+
1 row in set (0.01 sec
#计算表中chinese中的总行数
mysql> select count(math) from exam;
+-------------+
| count(math) |
+-------------+
| 5 |
+-------------+
1 row in set (0.00 sec)
#计算表中english列的总行数,并去重
mysql> select count(distinct english) from exam;
+-------------------------+
| count(distinct english) |
+-------------------------+
| 4 |
+-------------------------+
1 row in set (0.01 sec)
COUNT(*)函数计算包含NULL和非NULL值的行,即:所有行 , 而count (列名) 进行计算时 , 不会将值为NULL的行计算在内, 即所有的非空行 . count(distinct 列名) 则会返回不包含空值的唯一行数 .
结合where语句进行使用
#查询exam表当中, 英语成绩为112的人数
mysql> select count(english) from exam where english = 112;
+----------------+
| count(english) |
+----------------+
| 2 |
+----------------+
1 row in set (0.00 sec)
sum()函数
SUM()函数返回一组值的总和,SUM()函数忽略NULL值。如果找不到匹配行,则SUM()函数返回NULL值。
#计算数学成绩的总和, 并命名为emath
mysql> select sum(math) as emath from exam;
+-------+
| emath |
+-------+
| 473.0 |
+-------+
1 row in set (0.00 sec)
#计算英语成绩低于120分的成绩总和
mysql> select sum(english) from exam where english < 120;
+--------------+
| sum(english) |
+--------------+
| 402.0 |
+--------------+
1 row in set (0.00 sec)
avg()函数
AVG()函数计算一组值的平均值。 它计算过程中是忽略NULL值的 , 使用 avg() 函数可以的到 一组数据的平均值 .
# 计算所有同学的语文成绩的平均值
mysql> select avg(chinese) from exam;
+--------------+
| avg(chinese) |
+--------------+
| 94.70000 |
+--------------+
1 row in set (0.03 sec)
#计算总分的平均分
mysql> select avg(math+chinese+english) as 总均分 from exam;
+-----------+
| 总均分 |
+-----------+
| 293.70000 |
+-----------+
1 row in set (0.00 sec)
MAX()函数
MAX()函数返回一组值中的最大值。MAX()函数在许多查询中非常方便,例如查找最大数量,最昂贵的产品以及客户的最大付款数等 .
# 查询总分最高的同学总分
mysql> select max(math+english+chinese) as 总成绩 from exam;
+--------+
| 总成绩 |
+--------+
| 332.0 |
+--------+
1 row in set (0.00 sec)
#查询单科英语成绩的最高分的姓名
mysql> select max(english) from exam;
+--------------+
| max(english) |
+--------------+
| 120.0 |
+--------------+
1 row in set (0.00 sec)
不使用
max()函数的情况 , 也可以使用order by对数据集进行降序,并使用limit字句对结果集进行降序排序
mysql> select (chinese+math+english) as total from exam order by total desc limit 1;
+-------+
| total |
+-------+
| 332.0 |
+-------+
1 row in set (0.00 sec)
如果要找到总成绩最高的同学的全部信息 , 需要使用子查询进行
# 查询总成绩最高的同学信息
mysql> select *
-> from exam
-> where chinese+math+english = (select max(chinese+math+english)
-> from exam
-> );
+--------+------+------------------+---------+---------+-------+
| id | name | email | chinese | english | math |
+--------+------+------------------+---------+---------+-------+
| 202305 | 赵四 | 15623355@163.com | 90.0 | 112.0 | 130.0 |
+--------+------+------------------+---------+---------+-------+
1 row in set (0.00 sec)
Min()函数
Min()函数用于返回一组值当中的最小值 , 通常用于 查询一组数据当中最小的值 , 如 最小单价, 最小分数 等 , 和 max() 函数的用法类似 。
# 查询最小的总分
mysql> select min(math + english + chinese) as total from exam;
+-------+
| total |
+-------+
| 232.0 |
+-------+
1 row in set (0.00 sec)
#查询最小总分的全部信息
mysql> select * from exam
where chinese+english+math = (select min(math + english + chinese) as total from exam);
+--------+------+------------------+---------+---------+------+
| id | name | email | chinese | english | math |
+--------+------+------------------+---------+---------+------+
| 202304 | 王五 | 15547522@163.com | 89.0 | 65.0 | 78.0 |
+--------+------+------------------+---------+---------+------+
1 row in set (0.00 sec)
MySQL 当中除了一些常用的聚合函数外 , 还包括一些字符串函数 , 日期时间函数 , 控制流函数等 , 下面再列举一些比较常见的其他函数 .
IFNULL函数
IFNULL函数 是MySQL控制流函数之一,它接受两个参数 , 如果不是 NULL ,则返回第一个参数,否则IFNULL函数 返回第二个参数
IFNULL(expression_1,expression_2);
如果expression_1不为NULL,则IFNULL函数返回expression_1; 否则返回expression_2的结果。
示例表如下所示:
#查找某位同学的联系方式 (如果电话为空,使用邮箱)
mysql> select name,ifnull(phone,email) as 联系方式 from exam;
+------+------------------+
| name | 联系方式 |
+------+------------------+
| 张华 | 13225631456 |
| 李三 | 15698475235 |
| 宋七 | 15236486952 |
| 王五 | 15547522@163.com |
| 赵四 | 13562698745 |
| 李八 | 18625222@163.com |
+------+------------------+
6 rows in set (0.00 sec)
#其中,王五和李八的电话为空,则使用其电子邮箱作为其联系方式。
- 日期、时间函数
| now()函数 | 返回当前日期和时间。 |
|---|---|
| month()函数 | 返回一个表示指定日期的月份的整数。 |
| year()函数 | 返回日期值的年份部分。 |
| dayname()函数 | 获取指定日期的工作日的名称。 |
| round(数据,n) 函数 | 表示返回的数据保留n位小数 |
mysql> select year('2018-01-01');
+--------------------+
| year('2018-01-01') |
+--------------------+
| 2018 |
+--------------------+
1 row in set
mysql> select dayname('2018-01-01') dayname;
+---------+
| dayname |
+---------+
| Monday |
+---------+
1 row in set
1.2 GROUP BY子句
GROUP BY子句通过列或表达式的值将一组行分组为一个小分组的汇总行记录。GROUP BY子句为每个分组返回一行。换句话说,它减少了结果集中的行数,当GROUP BY子句与聚合函数相结合时, 可以返回每个分组的单个值。
#示例职工表
mysql> create table emp(
-> id int primary key auto_increment,
-> name varchar(20) not null,
-> role varchar(20) not null,
-> salary numeric(11,2)
-> );
Query OK, 0 rows affected (0.05 sec)
mysql> insert into emp(name, role, salary) values
-> ('张三','科员', 2000.54),
-> ('宋七','副厅', 8996.99),
-> ('赵四','科员', 1800.11),
-> ('李八','科长', 4540.5),
-> ('宋九','科员', 2356.33);
Query OK, 5 rows affected (0.01 sec)
Records: 5 Duplicates: 0 Warnings: 0
mysql> select * from emp;
+----+------+------+---------+
| id | name | role | salary |
+----+------+------+---------+
| 1 | 张三 | 科员 | 2000.54 |
| 2 | 宋七 | 副厅 | 8996.99 |
| 3 | 赵四 | 科员 | 1800.11 |
| 4 | 李八 | 科长 | 4540.50 |
| 5 | 宋九 | 科员 | 2356.33 |
+----+------+------+---------+
5 rows in set (0.00 sec)
对职工表进行分组查询 , 查询已知数据当中每个职位的最低和最高工资
mysql> select role,max(salary),min(salary) from emp group by role;
+------+-------------+-------------+
| role | max(salary) | min(salary) |
+------+-------------+-------------+
| 副厅 | 8996.99 | 8996.99 |
| 科员 | 2356.33 | 1800.11 |
| 科长 | 4540.50 | 4540.50 |
+------+-------------+-------------+
3 rows in set (0.00 sec)
1.3 HAVING子句
GROUP BY子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要使用HAVING子句
再次对上述的职工表进行操作,找出最高工资大于4000的职工职位角色和工资
mysql> select role,max(salary) from emp group by role having max(salary) > 4000;
+------+-------------+
| role | max(salary) |
+------+-------------+
| 副厅 | 8996.99 |
| 科长 | 4540.50 |
+------+-------------+
2 rows in set (0.00 sec)
条件筛选可以使用where, order by, limit等来实现,也可以不使用
HAVING子句和where语句的使用区别
- 分组之前指定条件, 也就是先筛选再分组, 使用
where关键字. - 分组之后指定条件, 也就是先分组再筛选, 使用
group by关键字
where和group by语法上要注意区分, where语句紧跟在表名后, 而having跟在group by后 .
示例:查询工资小于5000的职工中,各职工角色的平均工资(保留两位小数)
mysql> select role,round(avg(salary)) from emp where salary < 5000 group by role;
+------+--------------------+
| role | round(avg(salary)) |
+------+--------------------+
| 科员 | 2052 |
| 科长 | 4541 |
+------+--------------------+
2 rows in set (0.01 sec)
二 . 多表关系
- 概述
项目开发当中,在进行数据库的表结构设计时,会根据业务需求和业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着某种联系 , 基本上分为三种: 一对多/多对多/一对一.
- 一对多(多对一)
案例 : 班级与学生的关系
关系 : 一个班级拥有多个学生 , 一个学生属于一个班级
实现 : 在多的 一方(学生) 建立外键, 指向另一方的主键

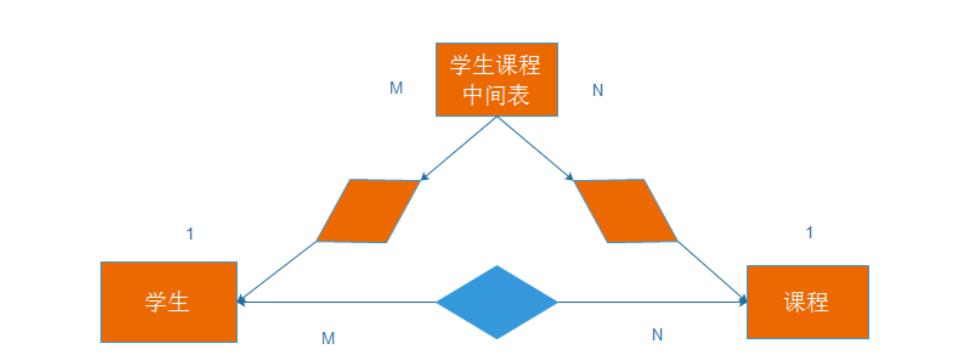
- 多对多
案例 : 学生与课程的关系
关系 :一名学生可以选修多门课程 , 一门课程也可以供多个学生来选择 .
实现 : 建立第三张中间表, 中间表中至少包含两个外键,分别关联两表的主键
- 一对一
案例 : 用户与用户详情之间的关系
关系 : 多用于单表拆分 , 将一张表的基础字段放在一张表当中 , 其他详情字段放在另一张表当中,以提升操作效率
实现 : 在任意一方加入外键,关联另一方的主键 , 并设置外键是唯一的

三、联合查询
实际开发当中往往要使用多个表的的数据,所以需要多表联合查询 , 多表联合查询时是对多张表的数据取笛卡尔积 , 然后对联合表中筛选出需要的数据
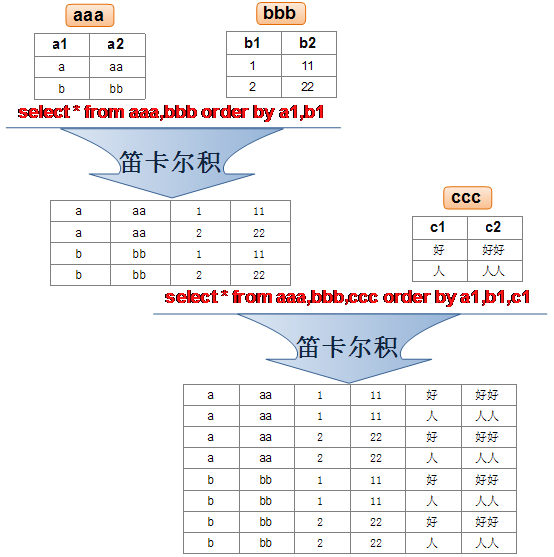
对n条记录的表A和m条记录的表B进行笛卡尔积,一共会产生n*m条记录, 当两张表的数据量很大的时候, 这个操作就非常危险了 , 需要慎重使用
mysql> select * from class;
+----------+------------+
| id | name |
+----------+------------+
| 1 | 计科1班 |
| 2 | 计科2班 |
+----------+------------+
2 rows in set (0.00 sec)
mysql> select * from student;
+------+--------+----------+
| id | name | class_id |
+------+--------+----------+
| 1 | 张三 | 1 |
| 2 | 李四 | 1 |
| 3 | 王五 | 2 |
| 4 | 赵六 | 2 |
+------+--------+----------+
#两个表进行笛卡尔集之后可以得到结果
mysql> select * from student, class;
+------+--------+----------+----------+------------+
| id | name | class_id | id | name |
+------+-------以上是关于『 MySQL篇 』:MySQL表的聚合与联合查询的主要内容,如果未能解决你的问题,请参考以下文章