Spark集群安装部署(基于Standalone模式)
Posted 巇橙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark集群安装部署(基于Standalone模式)相关的知识,希望对你有一定的参考价值。
spark集群安装部署(基于Standalone模式)
〇、部署环境
- Linux操作系统:Centos_6.7版本
- Hadoop:2.7.4版本(安装参考链接:https://blog.csdn.net/qq_52884581/article/details/127101352 )
- JDK:1.8版本
- Spark:3.2.3版本
一、下载Spark安装包
由于官网的下载速度太慢,因而推荐清华镜像下载,链接如下:
https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.2.3/

二、上传安装包至虚拟机
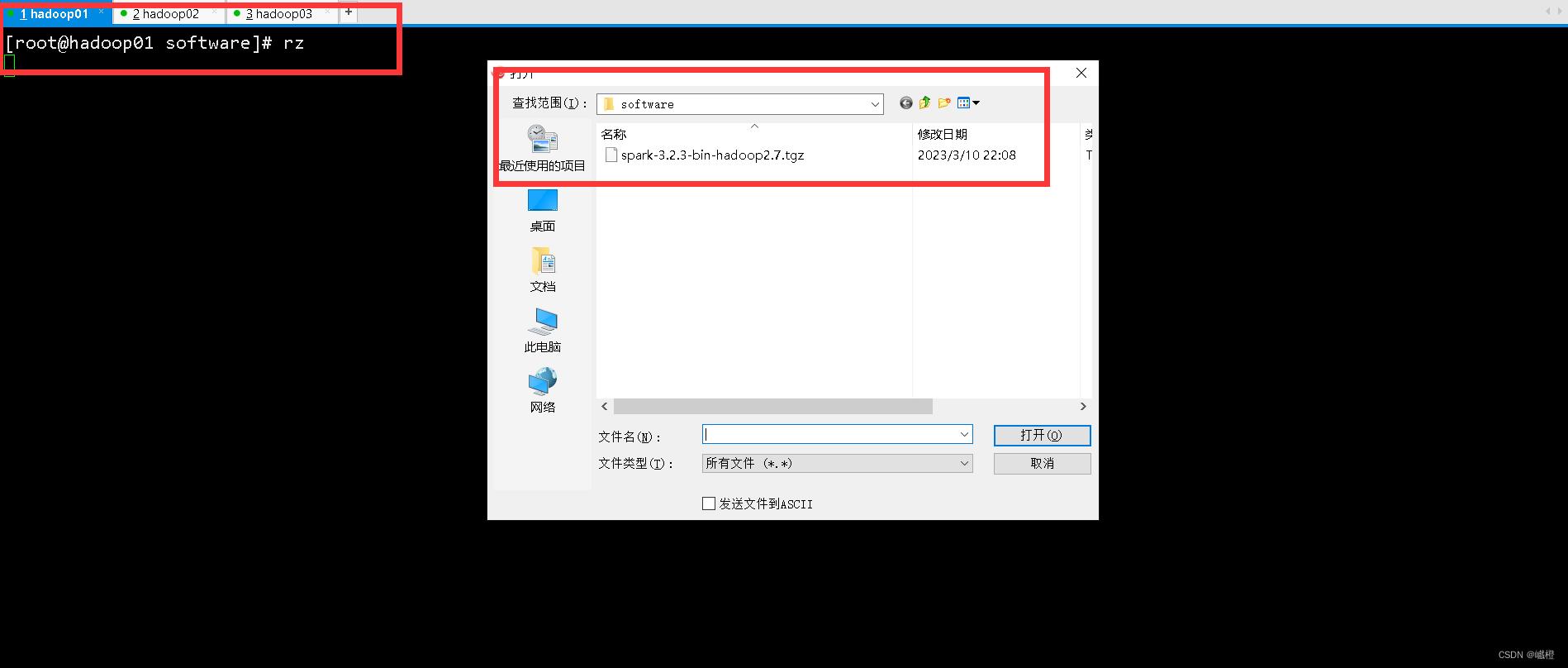
因为下载是在宿主机上进行下载,因而需要将下载的安装包上传到虚拟机上,如图在hadoop01节点中执行rz操作:
三、解压安装包
将安装包解压至路径/export/servers,具体目录明细在hadoop安装教程中有所介绍:
tar -zxvf spark-3.2.3-bin-hadoop2.7.tgz -C /export/servers
解压之后方便后面进行操作,对文件更名为spark:
mv spark-3.2.3-bin-hadoop2.7 spark
四、修改配置文件
1、配置spark-env.sh
进入spark的conf目录下,复制一份spark-env.sh.template模板,命名为spark-env.sh:
cp spark-env.sh.template spark-env.sh
使用vi编辑文件,在文件末端添加如下内容:
export JAVA_HOME=/export/servers/jdk1.8.0-161
export SPARK_MASTER_HOST=hadoop01
export SPARK_MASTER_PORT=7077
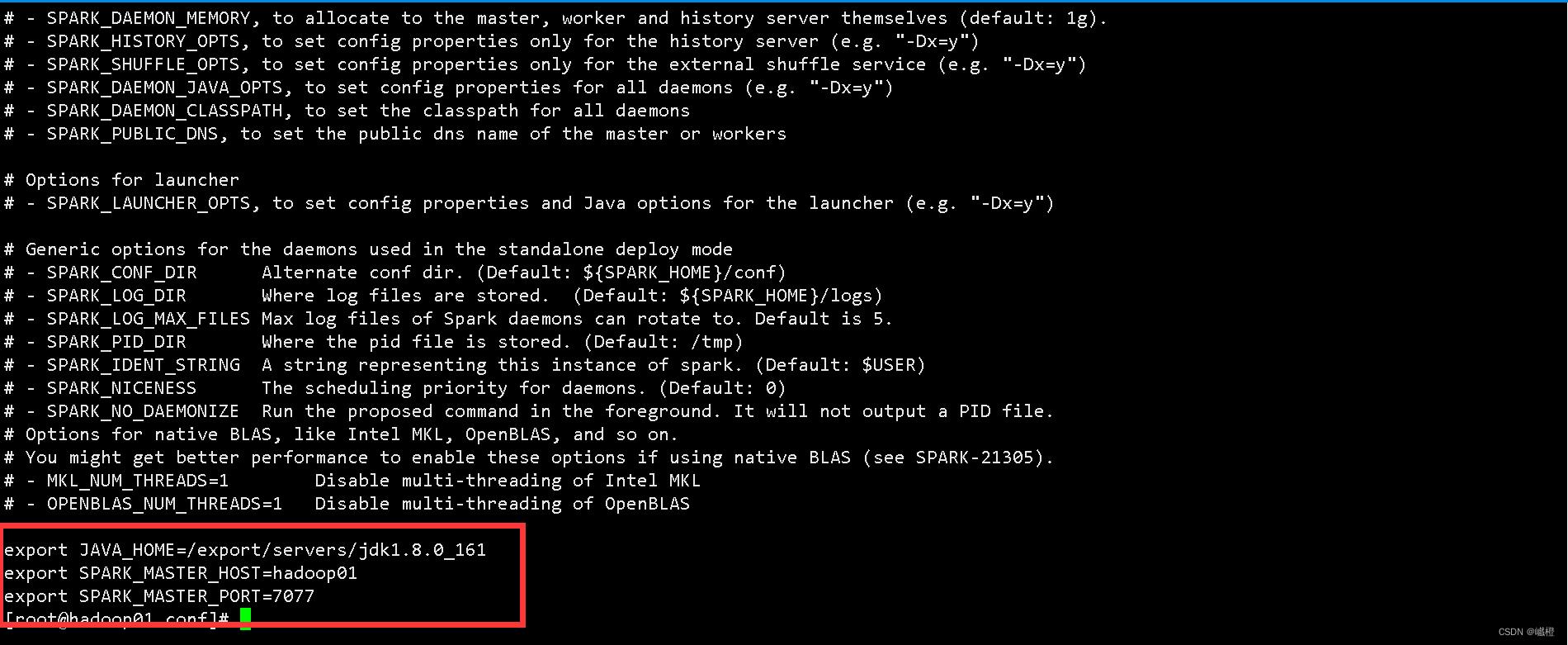
输入完成之后使用wq保存。
注:参数为jdk的环境变量(可根据自身情况修改)、Master节点的IP地址(在hadoop部署中提到了配置/etc/hosts文件)和Master的端口映射
2、配置workers
进入spark的conf目录下,复制一份workers.template模板,命名为workers:
cp workers.template workers
使用vi编辑文件,在文件末端添加如下内容:
hadoop02
hadoop03
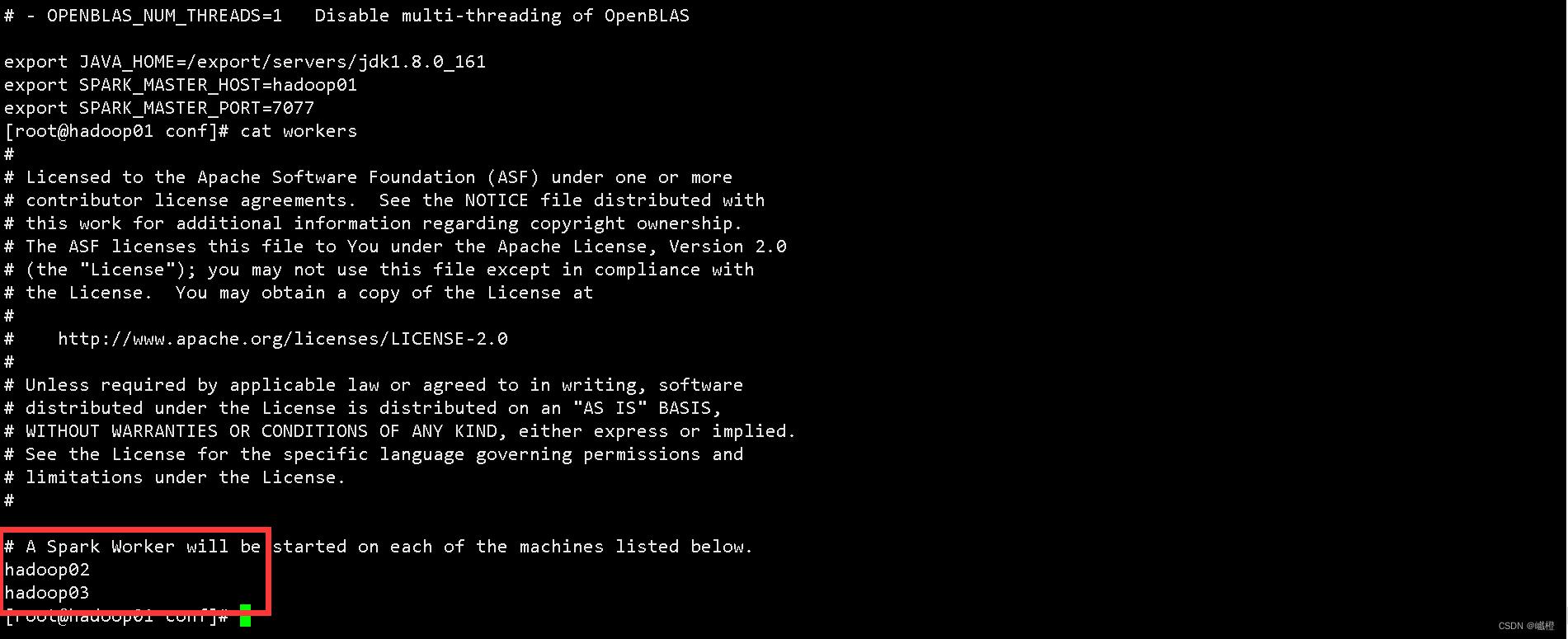
输入完成之后使用wq保存。
五、分发文件
执行代码:
scp -r /export/servers/spark/ hadoop02:/export/servers/
scp -r /export/servers/spark/ hadoop03:/export/servers/
六、启动spark集群
因为spark的启动方式的脚本名称与hadoop一致,因而需要到spark的目录下执行:
sbin/start-all.sh

使用jps查看进程:


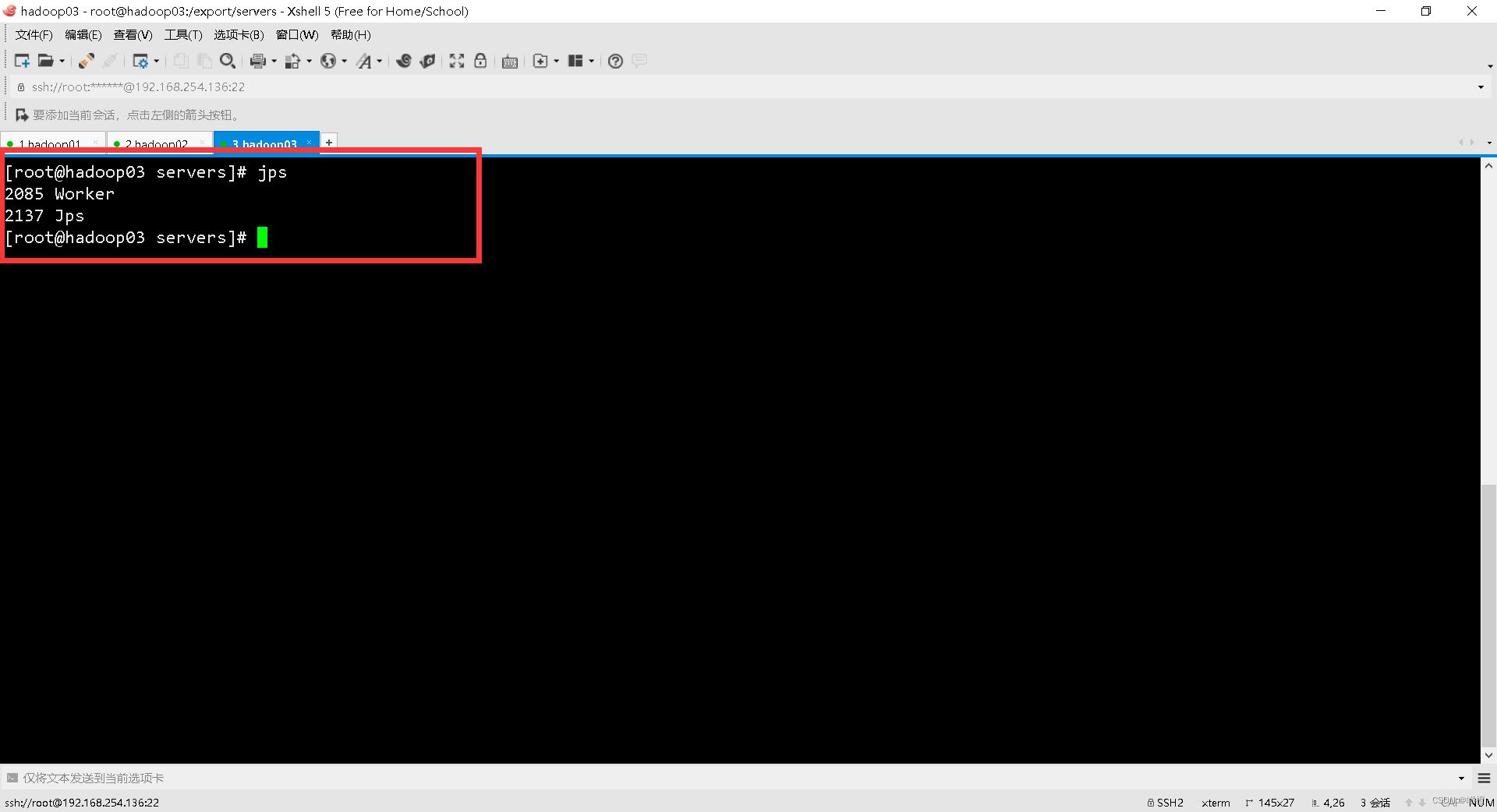
至此,spark配置结束。
以上是关于Spark集群安装部署(基于Standalone模式)的主要内容,如果未能解决你的问题,请参考以下文章