云原生数据湖元数据管理在滴普科技的实践
Posted 咬定青松
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生数据湖元数据管理在滴普科技的实践相关的知识,希望对你有一定的参考价值。
元数据在数据湖上的重要性不言而喻,借用阿里云官方社区的一张图:
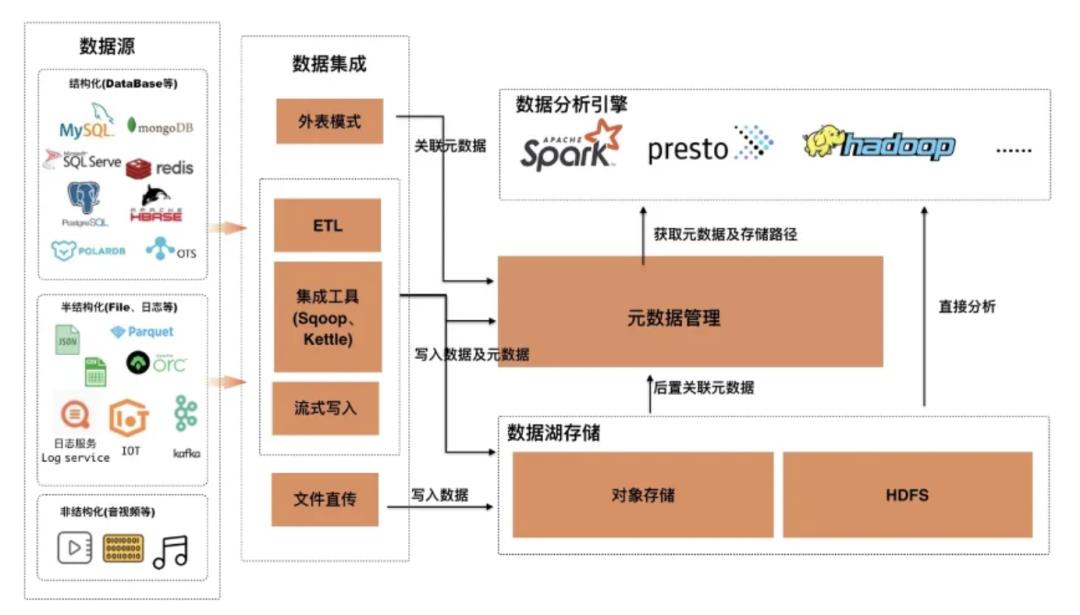
这幅图描绘了数据湖分析平台的总体构架,它主要包括五个模块:
数据源:原始数据存储模块,包括结构化数据(Database等)、半结构化(File、日志等)、非结构化(音视频等)
数据集成:为了将数据统一到数据湖存储及管理,目前数据集成主要分为三种形态。第一种为直接通过外表的方式关联元数据;第二种为基于ETL、集成工具、流式写入模式,这种方式直接处理数据能够感知Schema,在写入数据的过程中同时创建元数据;第三种为文件直接上传数据湖存储,需要事后异步构建元数据
数据湖存储:目前业界主要使用对象存储以及自建HDFS集群
元数据管理:元数据管理,作为连接数据集成、存储和分析引擎的总线
数据分析引擎:目前有丰富的分析引擎,比如Spark、Hadoop、Presto等,他们通常通过对接元数据来获得数据的Schema及路径;同时比如Spark也支持直接分析存储路径,在分析过程中进行元数据的推断
从图中我们可以看到元数据管理是数据湖分析平台架构的总线,面向数据生态要支持丰富的数据集成工具对接,面向数据湖存储要进行完善的数据管理,面向分析引擎要能够提供可靠的元数据服务。这是一种典型的面向数据湖的应用平台,其他应用场景与此类似,在构建此类应用时,往往会面临以下困难和挑战:
如何构建元数据的统一管理视图?
如何支持多计算引擎?
如何构建多租户和权限管理?
下面介绍一些厂商的具体实践案例。
01
阿里云云原生数据湖分析
阿里云云原生数据湖分析(简称DLA)采取计算与存储完全分离的架构,支持数据库(RDS\\PolarDB\\NoSQL)与消息实时归档建仓,提供弹性的Spark与Presto,满足在线交互式查询、流处理、批处理、机器学习等诉求。阿里云 DLA Meta兼容Hive Metastore,基于HMS的数据模型,重写了其服务层实现,数据源对接支持云上15+种数据数据源(OSS、HDFS、DB、DW)的统一视图,提供开放的元数据访问服务,支持OpenAPI、Client和JDBC访问协议:
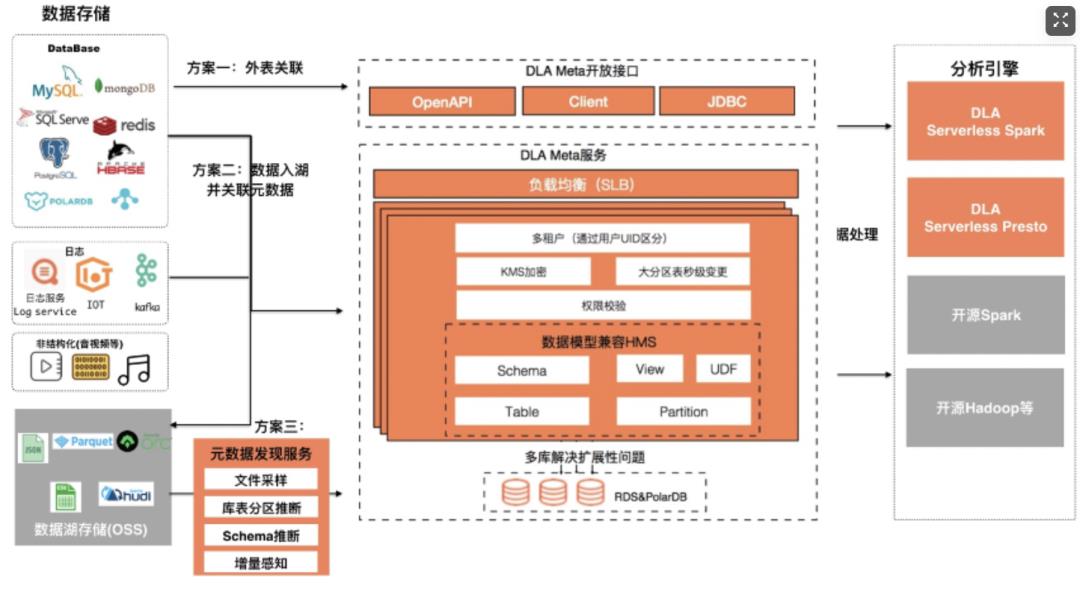
为了实现多租户功能,DLA Meta把每张库的元数据和阿里云的UID 进行关联,而表的元数据又是和库的元信息关联的。当用户请求元数据的时候,除了需要传进库名和表名,还需要将请求的阿里云UID 带进来,再结合上述关联关系就可以拿到相应用户的元数据。每个元数据的API 都有一个UID 参数,比如getTable 获取某个用户的表信息,整个流程如下:
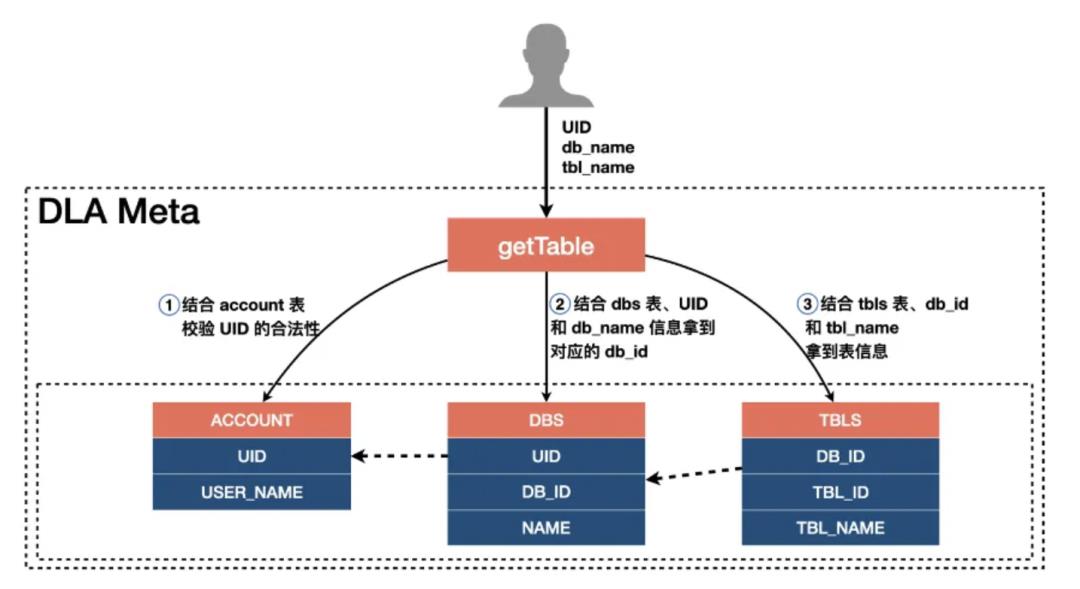
DLA Meta 中所有对外的元数据API 都是有权限校验的,比如Create Database 是需要有全局的Create 或All 权限的。只有权限校验通过才可以进行下一步的操作。目前DLA Meta 权限控制粒度是做到表级别的,可以对用户授予表级别的权限;当然,列粒度、分区粒度的权限我们也是可以做到的,目前还在规划中。【https://zhuanlan.zhihu.com/p/361510515】
02
腾讯云数据湖计算

腾讯云数据湖计算产品(简称DLC)由三大基本要素组成:
数据湖存储:提供海量异构数据的存储能力,具备低成本、高可用、可弹性伸缩。DLC基于腾讯云对象存储COS作为主要数据湖存储,搭配Alluxio进行数据编排和分层缓存,同时也支持云上EMR HDFS扩展存储;
数据湖计算:以Serverless无服务的形式提供高效敏捷的计算分析。DLC支持基于Presto实现即席分析,基于Spark实现数据ETL批处理、基于腾讯SuperSQL实现联邦跨源分析;
统一元数据:提供云上统一的在线数据目录和离线数据治理能力,主要有四个部分构成:
元模型定义:是对元数据的抽象描述,定义了Hive元模型和通用元模型;
元数据采集:支持基于PULL定时拉取和PUSH主动上报的两种方式采集元数据,并对原始元数据进行加工处理;
元数据存储:根据不同元数据的数据结构和用途,选择存放在不同类型的数据库中,目前使用了关系型数据库、索引数据库、图数据库;
元数据应用:分为在线数据目录和离线数据治理两类功能模块,在线数据目录可为数据湖的计算引擎提供Schema管理功能,而离线数据治理可为数据湖提供资产管理能力。
在整个架构图中,由黑色箭头的元数据流向可以看出,统一元数据是整个数据湖的基石和枢纽,发挥着承上启下的关联作用,承上对接数据湖计算引擎,启下对接数据湖存储,可通过元数据采集从异构数据源进行Schema数据结构爬取。DLC支持结构化数据,如腾讯云上EMR HIve,CDB、CDW等数据库,同时也支持半结构化数据,如Json文本、Log日志等。数据的Schema信息又可以为入湖构建提供基本的元数据资料。元数据中的Schema管理和数据治理,提升和保证了数据湖的数据质量,避免陷入数据沼泽,同时统一元数据可以整合不同的业务场景提供统一的数据管理视图,打通各业务的数据孤岛。
腾讯统一元数据功能分为在线数据目录管理和离线数据治理两块:
在线目录:提供元数据Schema管理能力,可类比Hive Metastore或AWS Glue 组件,对接计算引擎提供元数据信息。数据模型定义了两类:Hive数据模型和通用数据模型。Hive数据模型参考原生Hive的数据结构设计,通过定义DB、表、UDF Function、字段、分区、存储描述,使得在线目录功能尽可能与SQL-on-Hadoop的计算引擎无缝对接;而通用模型通过定义DB、表、字段,可适配基本的数据治理能力。
离线治理:提供丰富的元数据管理应用,包括数据地图、数据字典、数据检索、表/字段级别血缘、类目管理、标签管理、生命周期管理等功能。
除在线和离线核心功能外,多租户管理实现混合云场景的通用租户设计,使得统一元数据可适配不同场景。DLC抽象出元数据租户和业务租户两个层级维度的租户级别,来架构元数据的基本能力和满足不同的业务需求,如联邦多Catalog管理,多业务的元数据打通。
元数据租户是系统中的小租户粒度,可涵盖完备的元数据Schema信息,不同元数据租户是相互独立隔离的。一个元数据租户可类比为一个Hive Metastore,元数据租户与数据库DB是一对多的关系。一个腾讯云账号下对应多个元数据租户,可以适配多Catalog管理场景。
为便于计算引擎和外部服务的接口调用,同个腾讯云账号下,可定义不重名的元数据命名空间作为别名来使用,与元数据租户一一对应。元数据租户是抽象逻辑概念,可支持不同的元数据类型,如Hive、mysql等。
业务租户的设计初衷是为了解耦通用元数据与具体业务的强关联关系,使得底层元数据租户与具体的业务是无关的,由业务租户承担具体业务场景的关联与维护。数据源一般由业务使用方提供的,因此设计为与业务租户相关,一个业务租户可对应多个数据源。【https://z.itpub.net/article/detail/0AA18ADDAE153A29A37BA4EEECEC4DF9】
03
小米流批一体计算平台
小米流批一体计算平台基于Flink计算平台和Netflix Metacat元数据管理构建。Metacat向下对接多种异构数据源,如Hive、RDS、KUDU等,向上对接不同的计算引擎,如Flink、Spark、Presto和Hive。
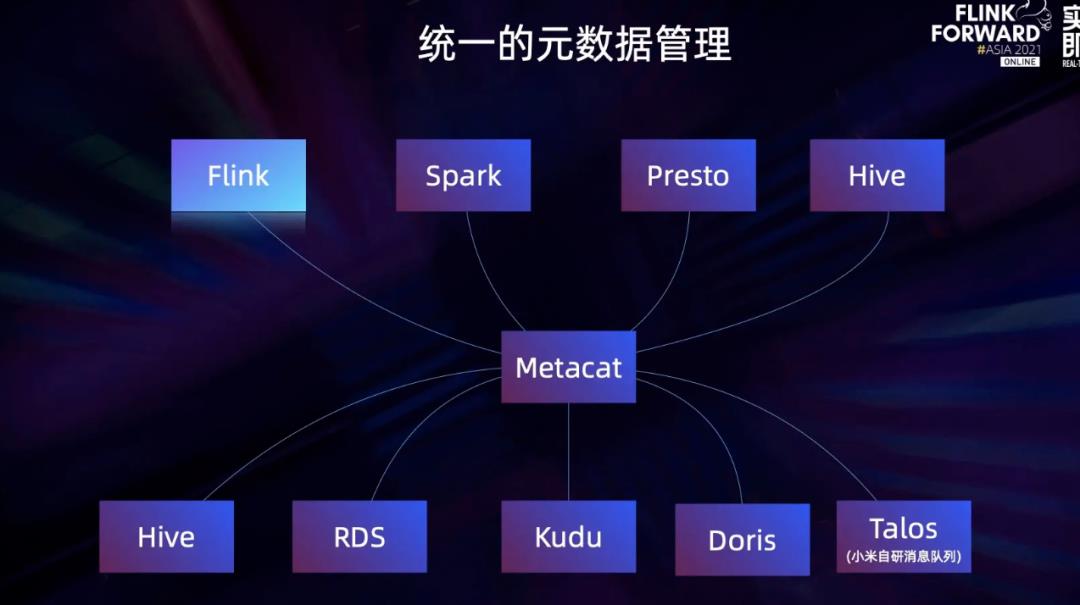
但从公开资料来看,小米流批一体平台主要基于Flink来实现流批一体。基于 Metacat,内部的所有系统都被统一划分成三级结构,与 FlinkSQL 的三级结构相对应。
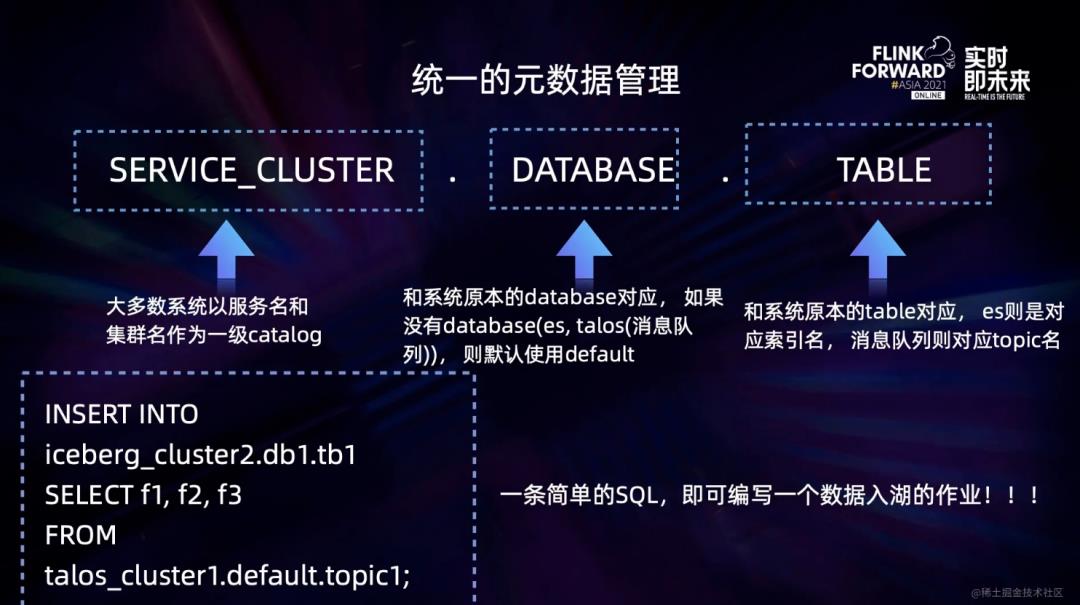
第一级 Catalog,主要由服务名和集群名拼接而成。
第二级 Database,它与大部分系统的 Database 保持一致。没有 Database 的系统默认使用 default 来代替。
第三级 Table,也与系统的 Table 保持一致,比如消息队列的 topic 名, Elasticsearch 的索引名。
在构建好统一的元数据管理之后,只需要写一条 DML 语句即可完成一个实时将消息队列数据入湖作业的开发。
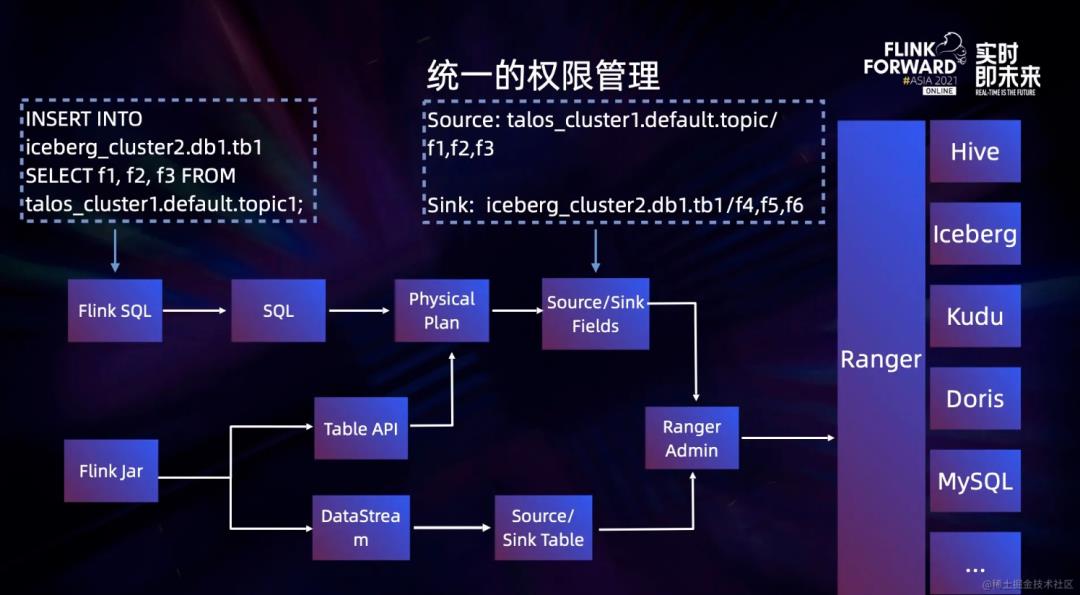
权限管理方面,小米基于Ranger来实现细粒度权限控制,Ranger本身支持不同存储系统的统一权限,因此向上提供了统一的权限控制接口,但Flink不支持跟Ranger的对接,小米在SQL解析后,针对需要访问的库和表来进行权限验证。同时为 Flink Jar 用户提供了统一的工具类,同时也对接了 Flink Catalog,因此也做到了 Jar 包作业的权限校验。
04
滴普科技湖仓一体计算平台
滴普科技湖仓一体计算平台基于云原生体系构建,除底层HDFS、Kafka等与存储强相关的组件外,其余组件或服务都部署在Kubernetes。作为湖仓底座,湖仓一体计算平台提供一站式数据集成、数据开发和数据查询分析应用功能,支撑上层数据开发平台和数据应用平台。
湖仓一体计算平台分为三部分:
统一存储:基于Iceberg和HUDI数据湖技术,支持分布式文件存储和对象存储,包括HDFS和S3、OSS、OBS等。
统一元数据:基于Metacat将平台支持的多种异构数据源提供统一的元数据管理操作接口
统一计算:上层计算引擎通过Metacat跟底层数据源交互,由于Metacat屏蔽了不同数据源的接口访问差异,间接统一了计算引擎对数据源的访问
下图是以统一元数据为视角的在湖仓一体计算平台架构:
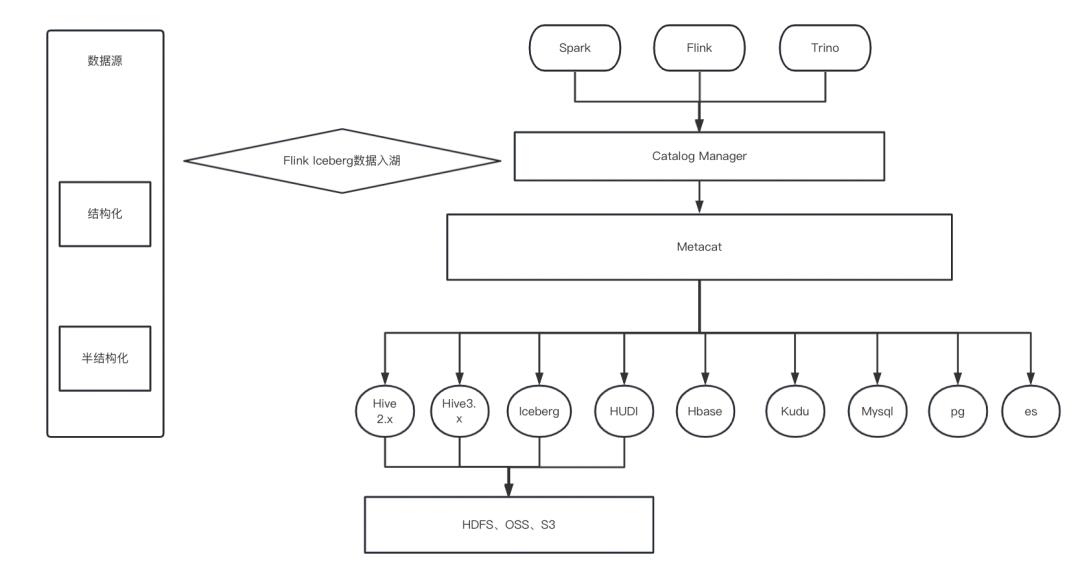
图中Catalog Manager作为Metacat客户端,通过RESTFul API同Metacat交互,比如访问请求的序列化与反序列化、获取Metacat Catalog列表并按照业务规则重组、适配实现计算引擎Catalog管理接口并注册给计算引擎等。
之所以选择Metacat作为我们元数据管理平台的基础, 主要是它实现的目标同我们的需求以及实现过程中遇到问题的高度一致:
提供元数据系统的联合视图
用于数据集元数据的统一 API
支持业务和用户元数据存储
下图展示了统一元数据在SQL编辑器场景中的应用:
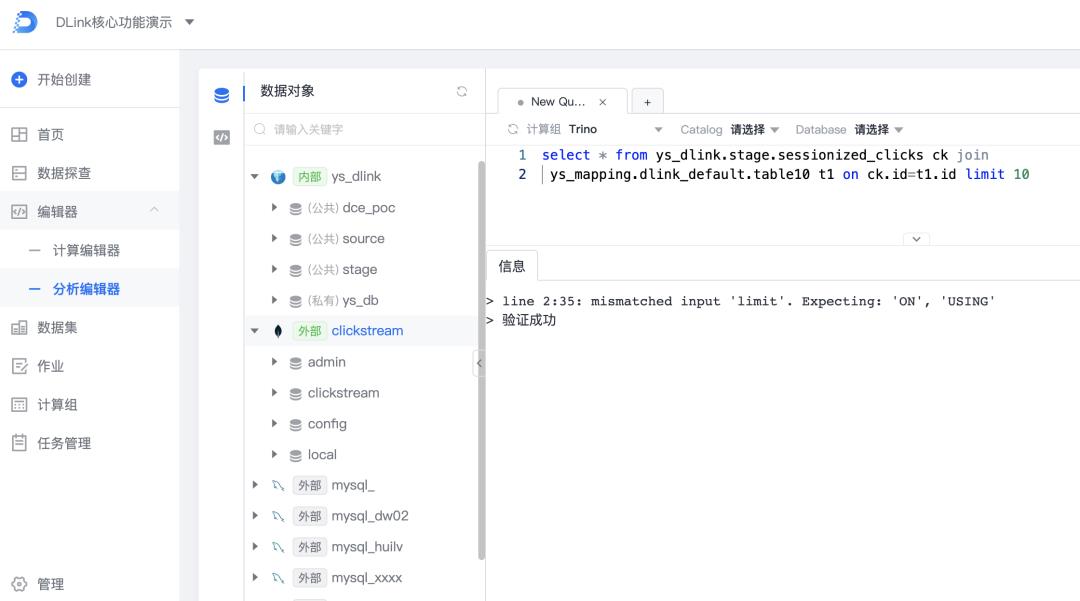
图中,所有注册到Metacat中的数据源的元数据都可以在左侧列表中展示,包括数据库、数据表、字段信息等。这些信息为Flink、Spark和Trino等共享。在编辑器区,可以实现跨Catalog(跨数据湖)的联邦计算或查询,SQL作业则提交到Kubernetes部署的计算集群上。
Metacat本身不存储数据源的元数据,只存储跟数据源相关的业务元数据和用户自定义元数据。从系统功能高层视角,可以将Metacat的特性归为以下几类:
数据抽象和互操作性:通过引入通用的抽象层,提供统一的访问API,不同的引擎可以交互访问这些数据集。为便于与 Spark、Flink和 Trino等 集成,提供支持 Hive 的 Thrift 接口。
存储业务和用户自定义的元数据:统一元存储只存储技术元数据,实际上,还会有部分业务元数据和用户自定义元数据,例如 RDS 数据源)、配置信息、度量指标(Hive/S3 分区和表)以及数据表的 TTL(生存时间)等。它们是一种自由格式的元数据,可由用户根据自己的用途进行定义。
数据发现:作为数据的消费者,我们应该能够轻松发现和浏览各种数据集。为提升查询效率和能力,需要将Schema元数据和业务及用户定义的元数据发布到 Elasticsearch,以便进行全文搜索。SQL 编辑器因此能够实现 SQL 语句的自动建议和自动完成功能。将数据集组织为Catalog有助于消费者浏览信息,根据不同的主题使用标签对数据进行分类。我们还使用标签来识别表格,进行数据生命周期管理。
数据变更审计和通知:作为数据存储的中央网关,统一元数据能够捕获所有元数据变更和数据更新,通过构建基于事件驱动的系统架构,将元数据变更通知发布到消息系统,不仅有助于上下游系统解耦,还有助于下游系统响应的及时性。
Schema和元数据的版本控制:用于提供数据表的历史记录。例如,跟踪特定列的元数据变更,或查看表的大小随时间变化的趋势。能够查看过去某个时刻元数据的信息对于审计、调试以及重新处理和回滚来说都非常有用。
Hive Metastore 优化:由 RDS 支持的 Hive Metastore 在高负载下表现不佳。我们已经注意到,在使用元数据存储 API 写入和读取分区方面存在很多问题。为此,我们不再使用这些 API。我们对 Hive 连接器(在读写分区时,该连接器直接与 RDS 通信)进行了改进。之前,添加数千个分区的 Hive Metastore 调用通常会超时,在重新实现后,这不再是个问题。
下图是Metacat的系统架构图:

上图中展现的重点特性说明如下:
为了避免元数据获取不及时以及数据不一致等问题,我们没有采用元数据定时抓取的集中式存储方式,而是采用实时读取的方式来获取数据源的元数据。
为了能获取数据源元数据的实时变更日志以及支持订阅、搜索等能力,我们将元数据变更记录发送到下游Kafka和ElasticSearch。
为便于上层应用方便的获取元数据,Metacat提供了标准的RESTful API和Thrift RPC接口。
Metacat不仅支持HMS3.x还支持HMS2.x等不同版本的接口,能够屏蔽底层不同版本的差异。
Metacat内置了HMS3.x,但是对HMS本身做了定制开发,以支持动态切换存储引擎的能力。因为Hive Metastore Server配置项是静态的,无法支持动态添加配置,我们通过修改内部逻辑,在保留原有使用方式不变的情况下能够做到才Catalog级别同时支持多种外部存储(如MinIO、HDFS、S3等)。
通过开发HMS Proxy,用户能够通过仅仅修改HMS连接地址就可以访问HMS3.x的非默认Catalog,这个功能对多Catalog存储尤为有用。
在多租户支持能力上,Metacat通过<Catalog,Databse,Table>这样标准的元数据组织方式来管理元数据,Catalog代表一种数据源实例,如一个Hive Metastore服务实例(通过IP和端口标定)、一个Mysql数据库运行实例(通过IP和端口标定)等。租户跟Catalog是一对多的关联关系,每个租户只能看到关联的Catalog元数据信息。
湖仓一体平台本身内置Hive Metastore,计算引擎创建的元数据都持久化到Hive Metastore,比如通过Flink SQL创建的mapping表、Iceberg(HUDI)表。平台本身内置Hive Metastore基于HMS3.x版本开发,由于HMS3.x本身支持多Catalog,用户可能将元数据创建在非默认的Catalog下面,因此Metacat还需要维护该HMS实例Catalog同HMS内部Catalog的映射关系,这样同样一个HMS实例可以在Metacat上注册创建多个Catalog实例,区别是HMS内部映射的Catalog不同。
实际上,租户和Catalog映射关系提供了Catalog级别的权限控制,另一种更细粒度的权限控制是基于Ranger。我们基于Ranger配置用户、Catalog、库、表和字段等不同粒度的鉴权规则,不同计算引擎再通过Ranger API进行权限验证,Trino本身支持Ranger,可以通过部署插件支持,Flink本身不支持Ranger,我们在Flink SQL解析中获取到访问的资源类型再通过调用Ranger API来实现鉴权。
05
未来规划
内置HMS性能优化
从业界实践来看,比如阿里云、腾讯是大幅度修改或者重写了HMS协议,比如阿里云在存储模型上增加了租户信息,在上层服务实现上也用了最新的开发技术栈来替代HMS原有的实现方式,这点同腾讯是一样的。滴普科技没有大幅度修改HMS源码,但基于HMS3.1.2增加了CATALOG_PARAMS表,以支持动态加载Catalog实现多存储能力。在HMS的部署上,我们还增加了自动化部署能力,以支持基于Kubernetes的开发流程。多租户能力实现则跳出HMS本身,在数据源上层(metacat)来实现,从而减少开发和维护的代价。但是HMS本身的性能问题仍需要关注。另外,数据湖技术比如Iceberg的较新的SQL语法需要在HMS4.x中才支持,后续需要将HMS3.x新增的功能合并到HMS4.x,并将服务升级到HMS4.x。
Metacat完善与开源
Metacat提供了很好的数据源元数据管理的抽象能力,但是因为项目多年未更新,不仅技术栈较为陈旧,而且很多功能设计不合理或欠缺,基本属于半成品,我们几乎是更新并重写了项目才满足我们的功能需要。未来,我们计划增加对HUDI的支持能力,以及更多数据源类型的支持,并将项目回馈到社区。
HMS Proxy开源
HMS Proxy在Metacat之上,实现了通过开源的Hive client(包括Flink、Spark、Trino),仅仅配置thrift 地址就能够访问Metacat任意Catalog的元数据,且不存在版本兼容问题。另外,它也实现了跨Catalog的联邦查询能力,该能力在湖仓一体联邦查询场景上尤为重要。
以上是关于云原生数据湖元数据管理在滴普科技的实践的主要内容,如果未能解决你的问题,请参考以下文章