Hadoop生态系统-zookeeper
Posted weixin_D2289182161
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop生态系统-zookeeper相关的知识,希望对你有一定的参考价值。
Zookeeper3.5.7:协调器
目录导航
入门
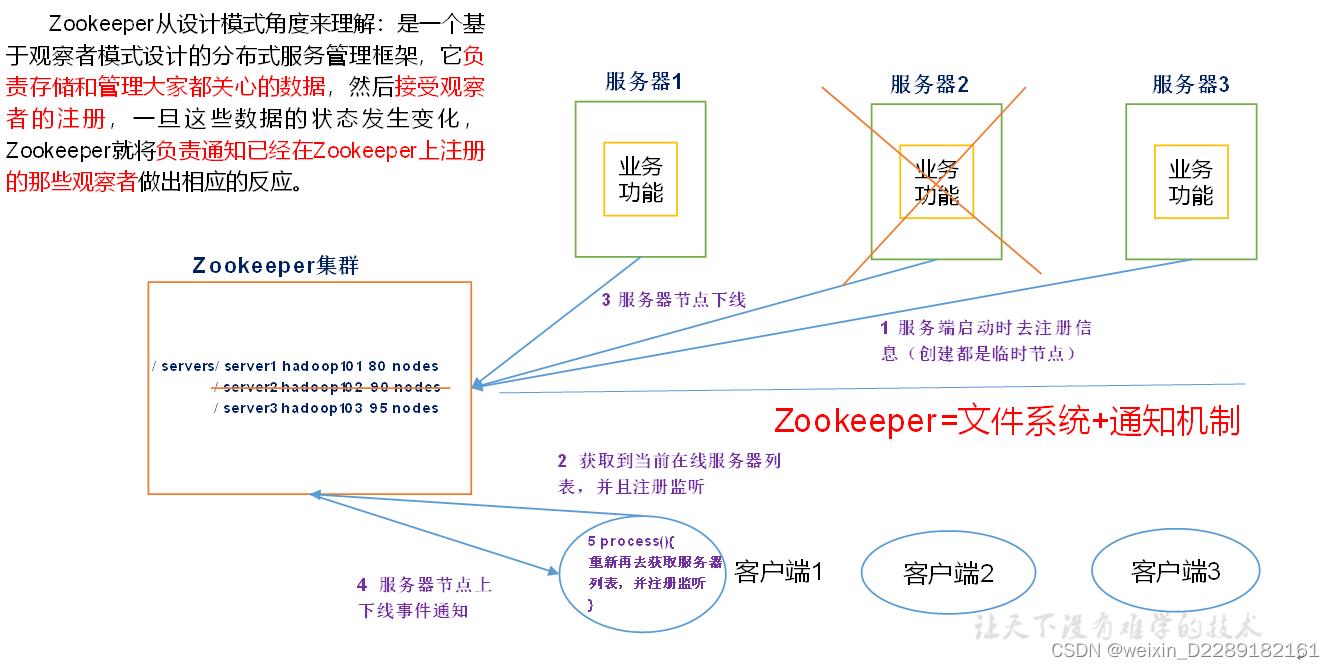
- 概述:为分布式应用提供协调服务的分布式开源项目。(基于观察者设计模式的分布式管理框架)Zookeeper=文件系统+通知机制
- 工作机制
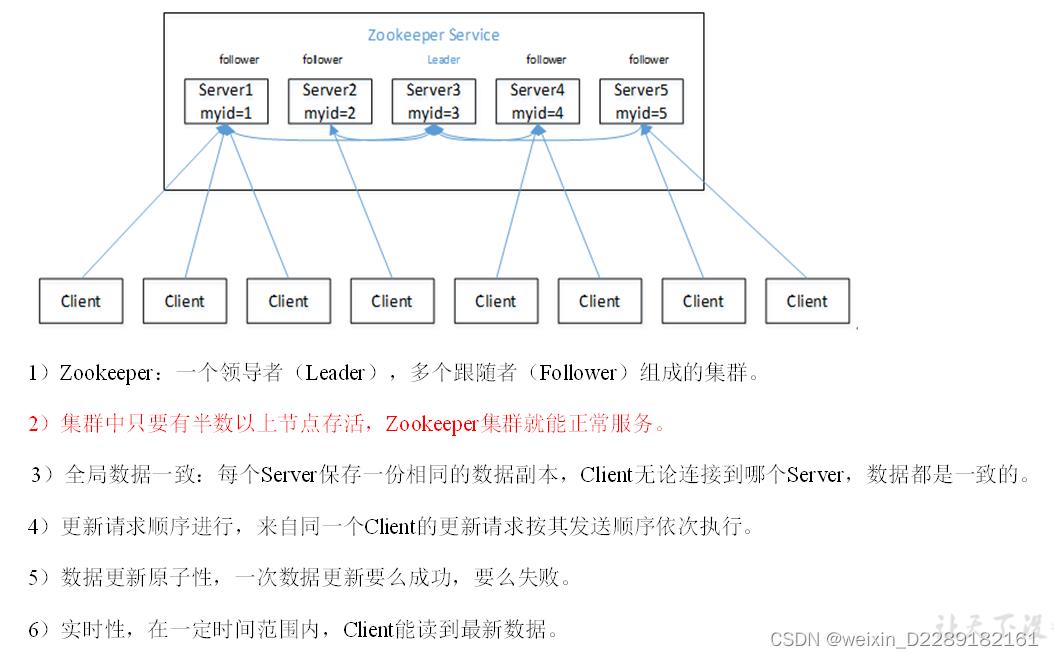
- 特点
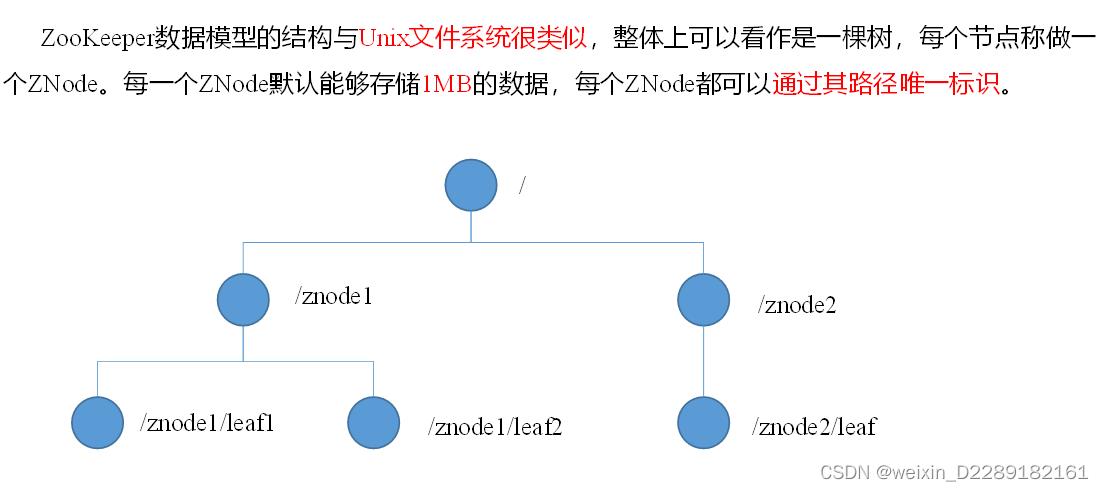
- 数据结构:类似Linux系统结构,是一个树状图,但是这里没有文件这个概念,结点中直接存储内容。数据直接写入到ZNode
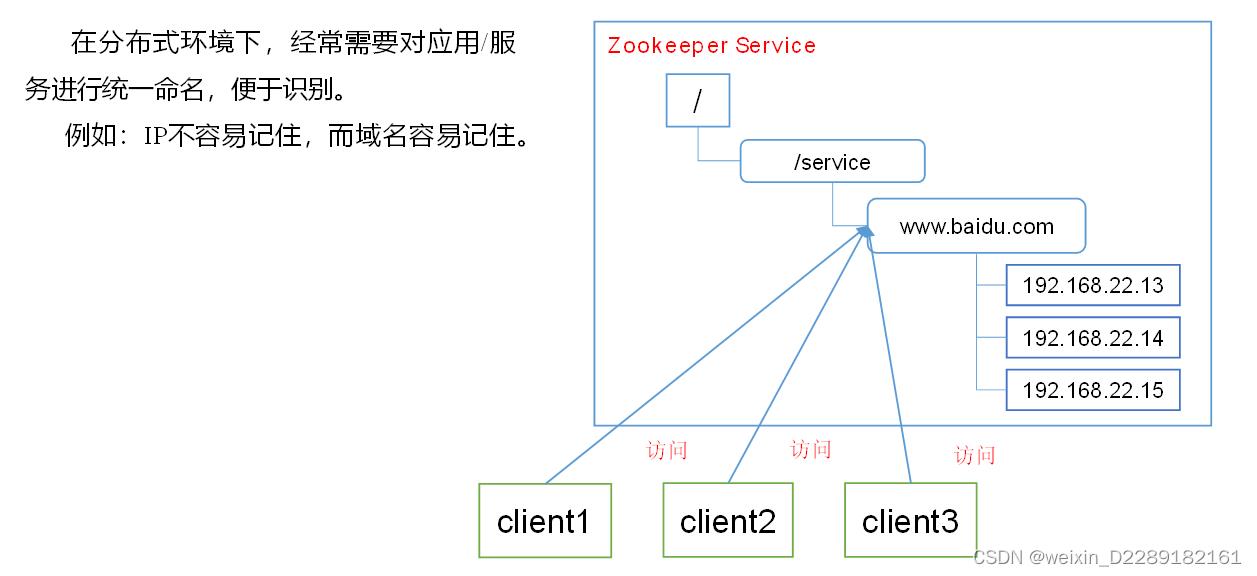
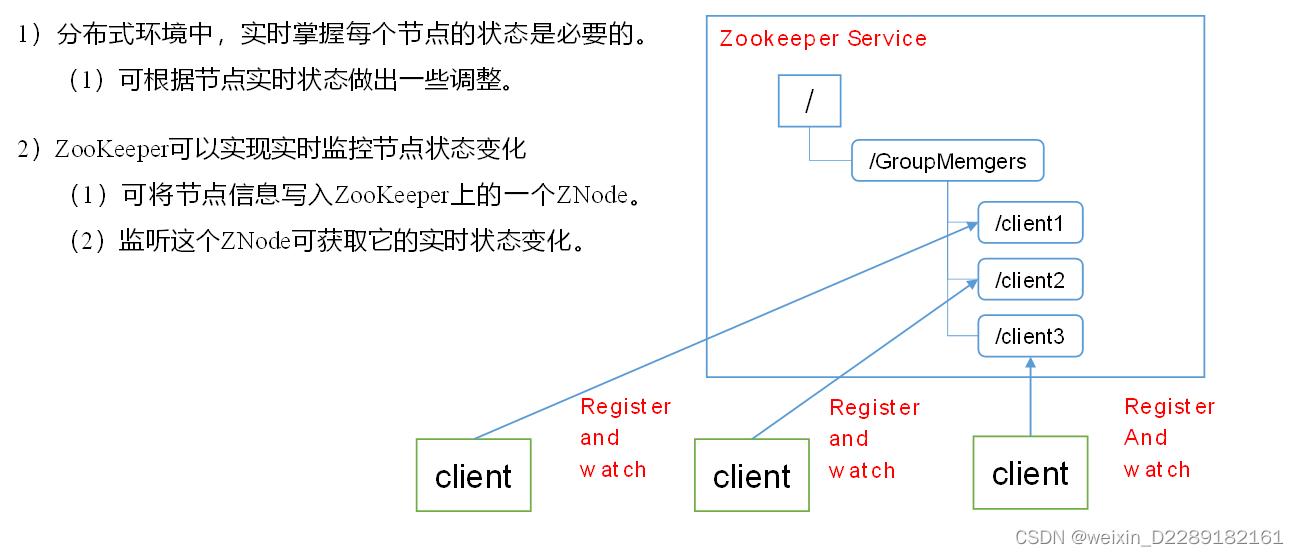
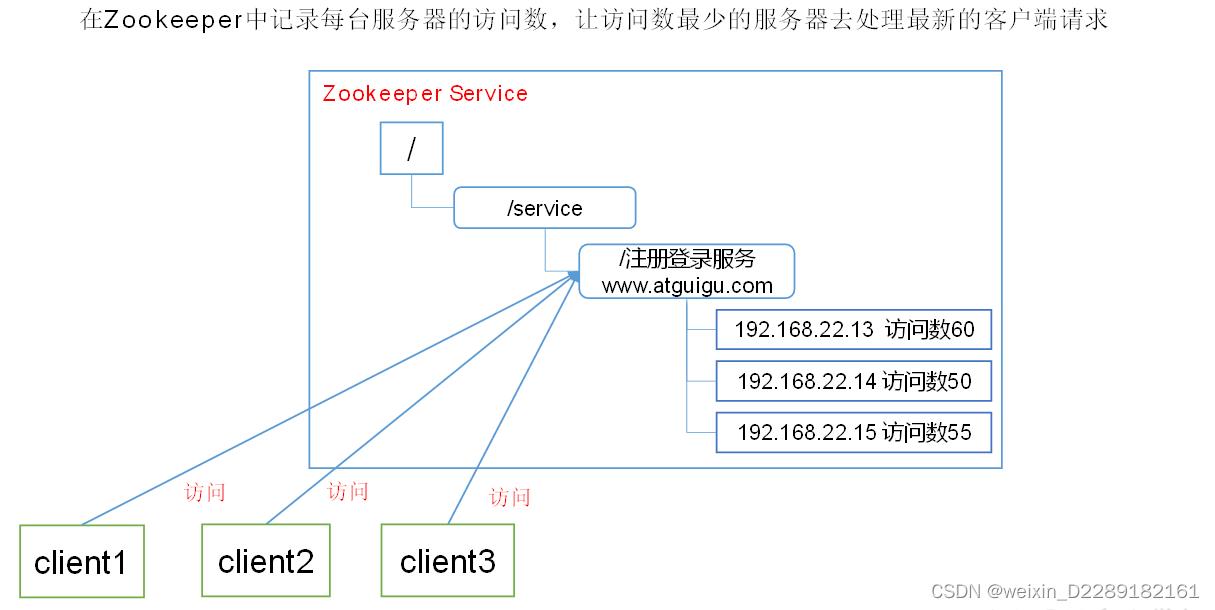
- 应用场景:提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等


- 下载地址:zookeeper官网: link
实操
本地模式安装部署
安装步骤
-
配置环境变量:选做,以后使用脚本群起,脚本里都是绝对路径,因此就不配了
-
1.将软件包上传到Linux的/opt/software下,并解压

-
2.改名(选做)
-
3.改配置文件名
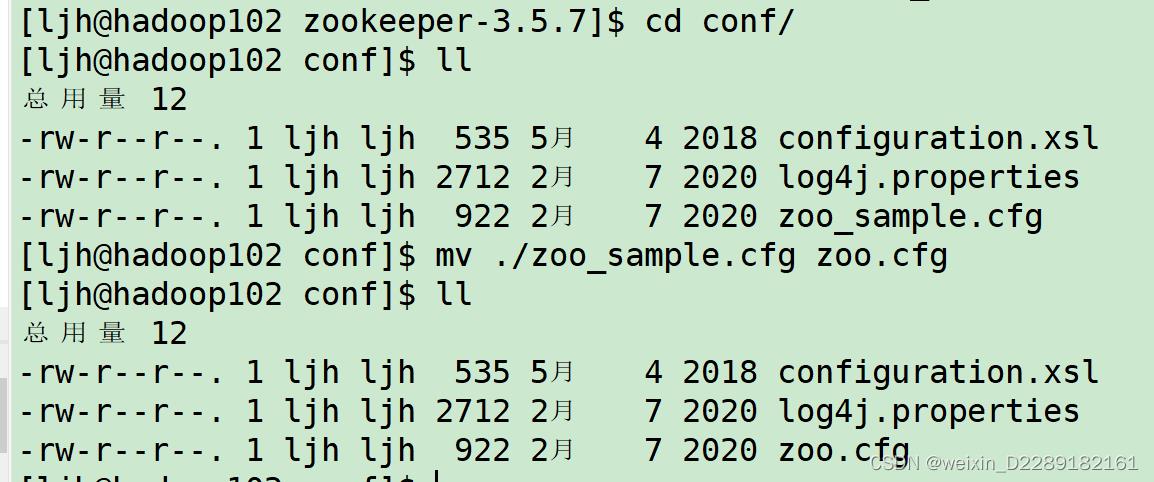
-
4.在ZK的安装目录下创建一个新的目录,作为zk数据的持久化目录。配置到zoo.cfg文件
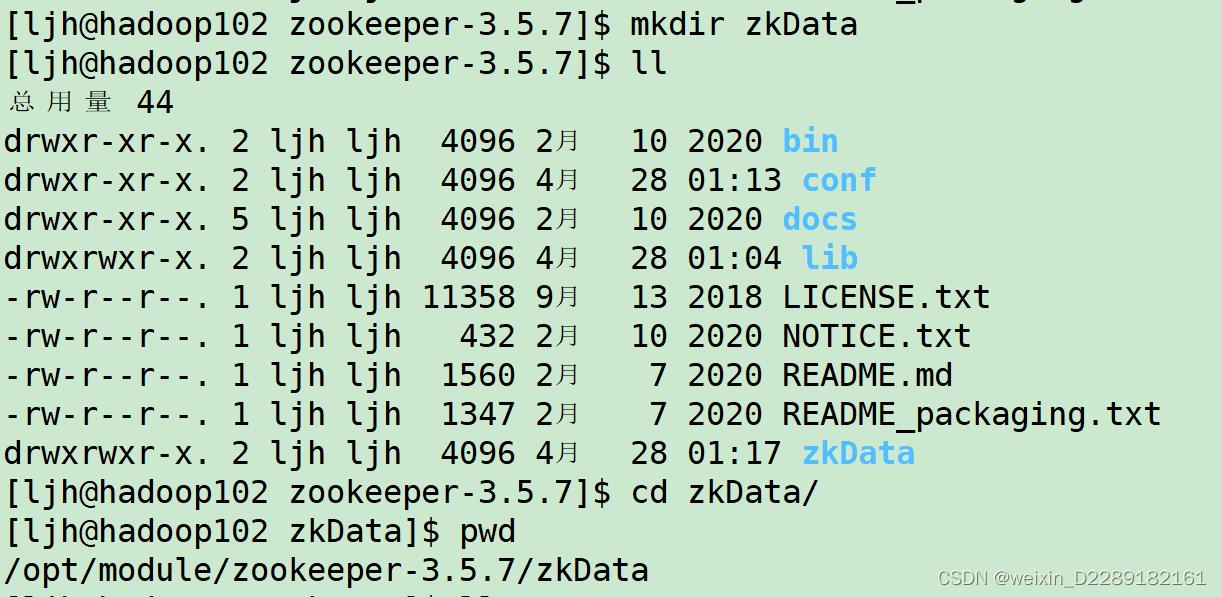

单点模式的简单操作
-
1.启动zk服务端
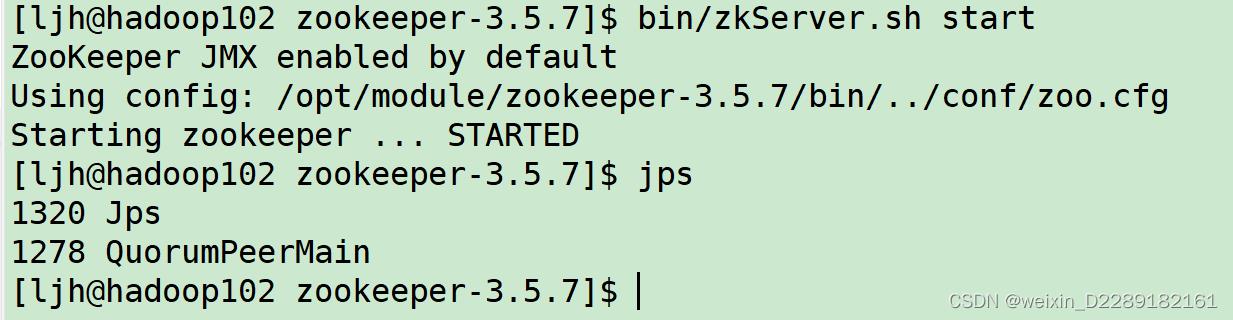
-
2.启动zk客户端。zk默认的端口号:2181。quit即可退出客户端




-
3.关闭服务端
zoo.cfg配置文件解读

分布式安装部署
准备:配置zoo.cfg和编号。并分发改掉myid
-
1.配置zoo.cfg

Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server
2888:lender和flower交换信息端口
3888:当leader挂了后选举leader的通信端口 -
2.给hadoop102编号2

-
3.分发并改myid

实操:群起脚本
-
1.创建脚本文件并赋予运行权限
-
2.编写脚本
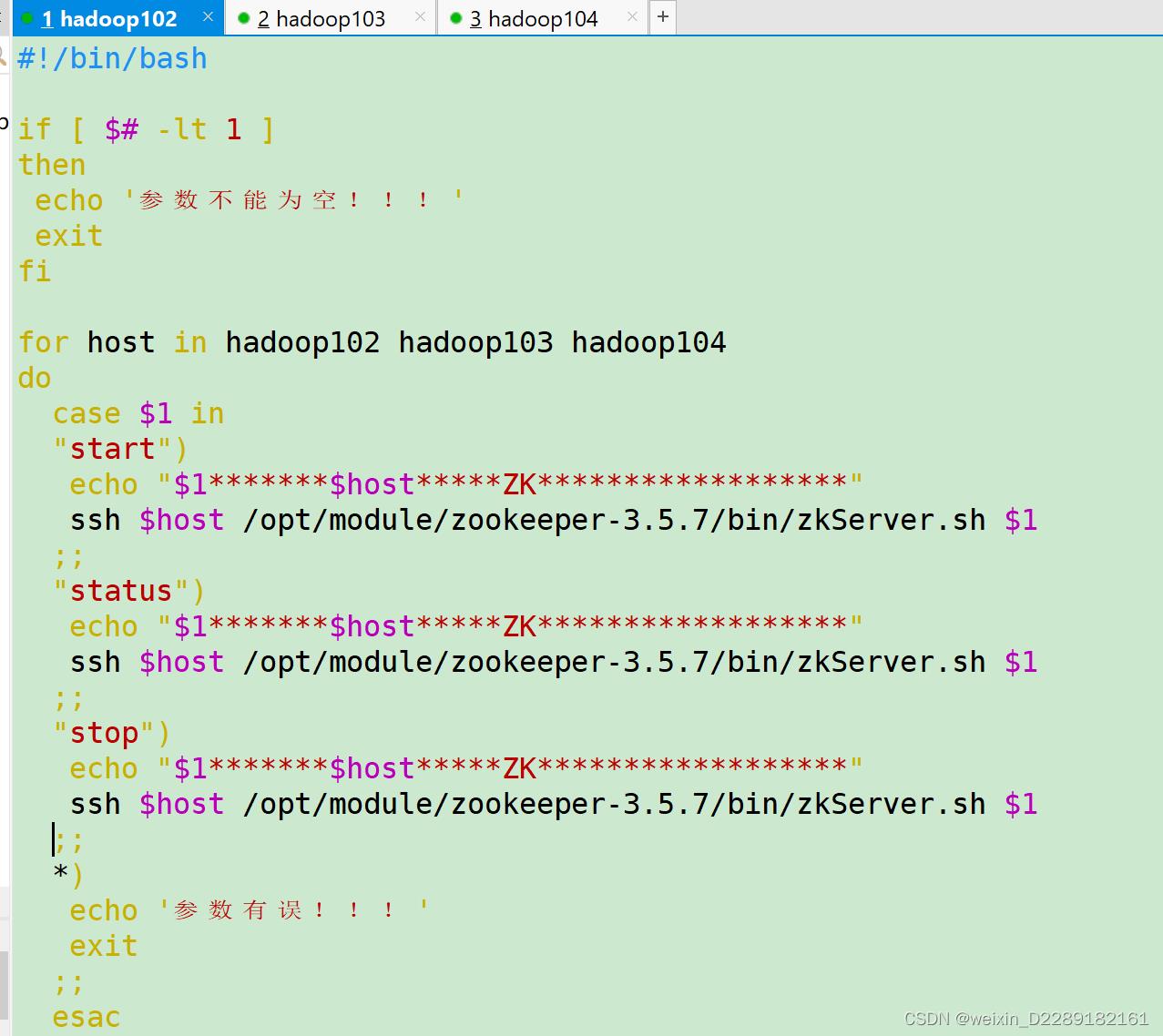
-
3.运行脚本
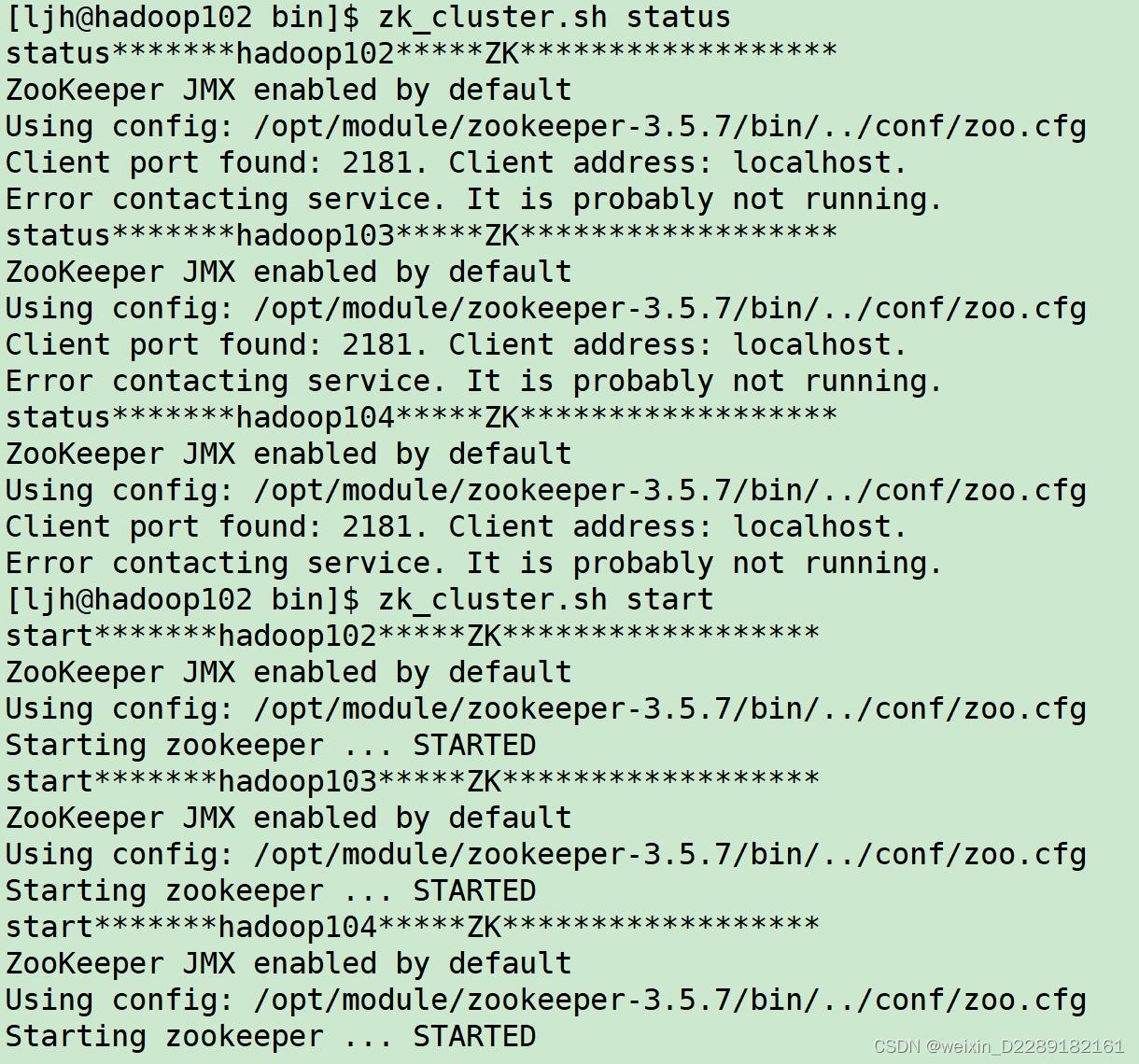


客户端操命令行操作
-
启动zk服务,并在客户端操作zk
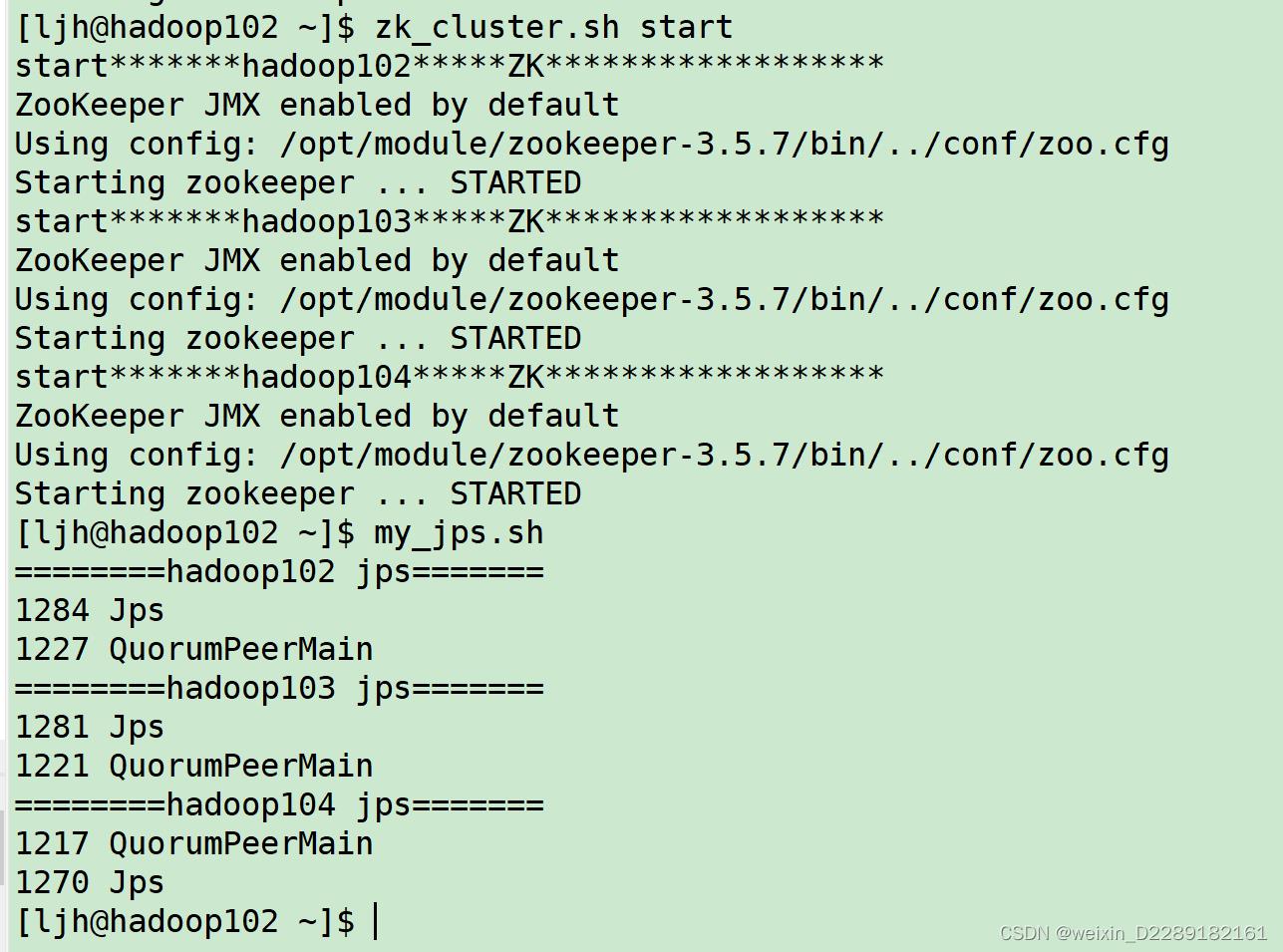
-
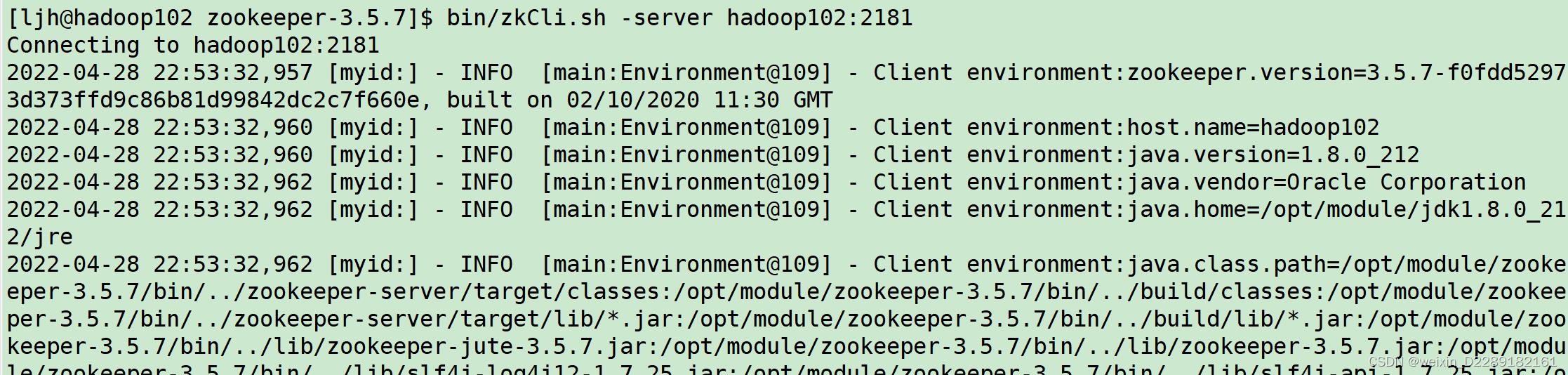
ls
-
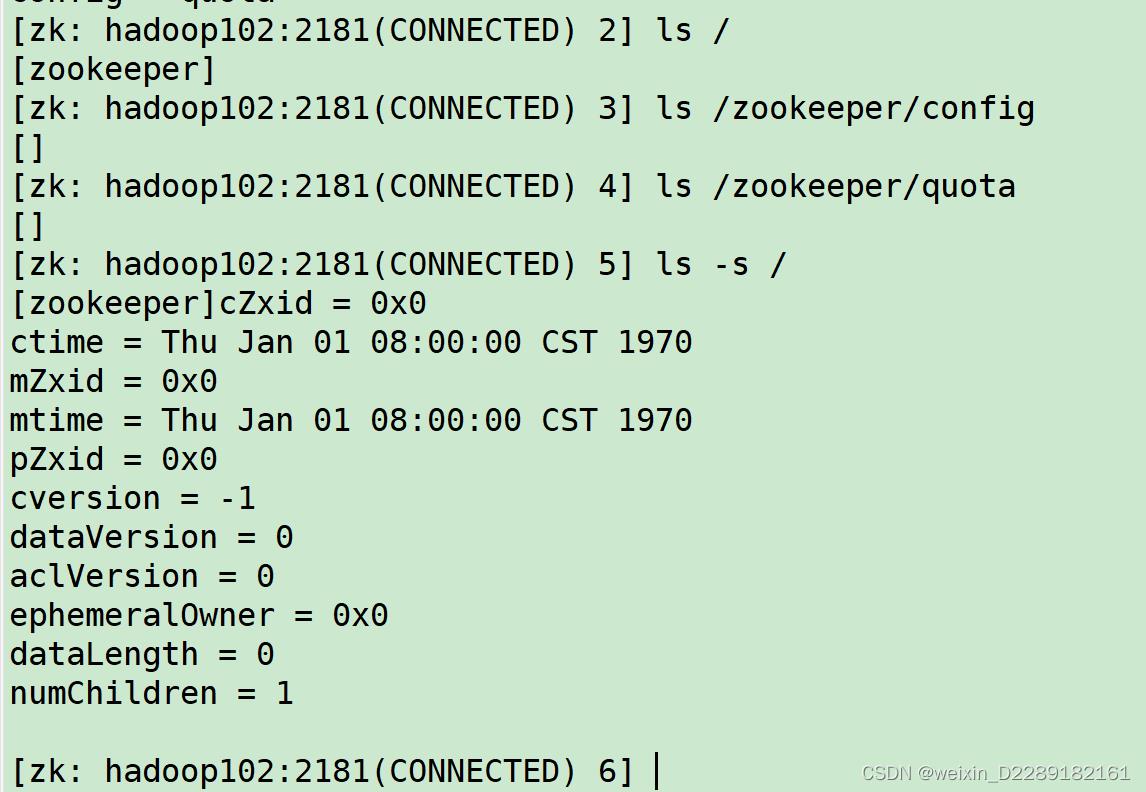
create

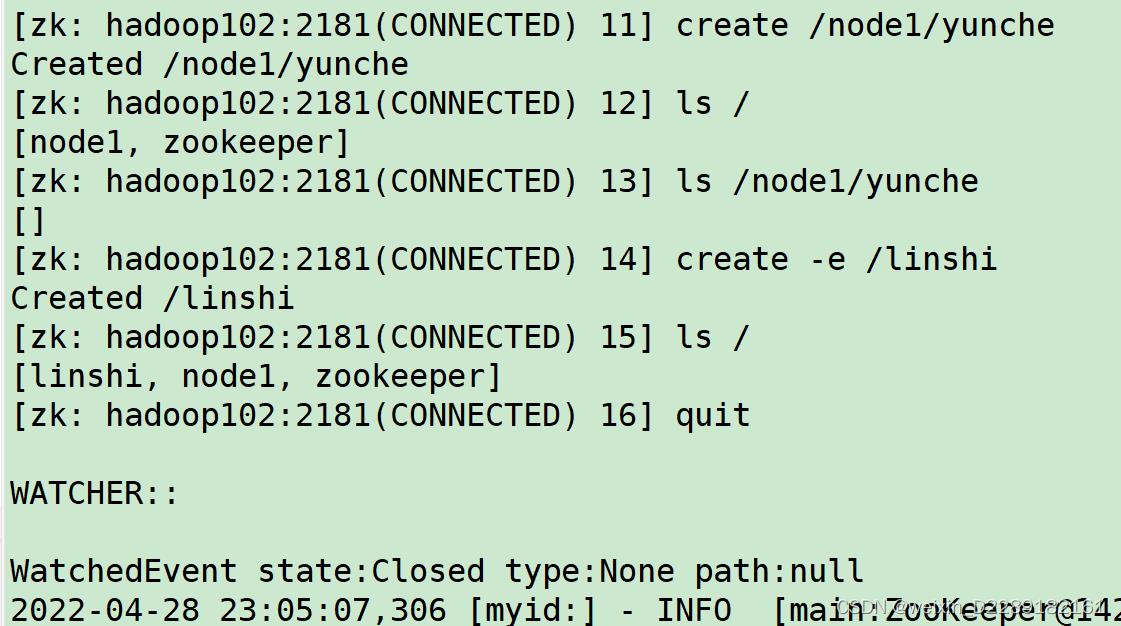
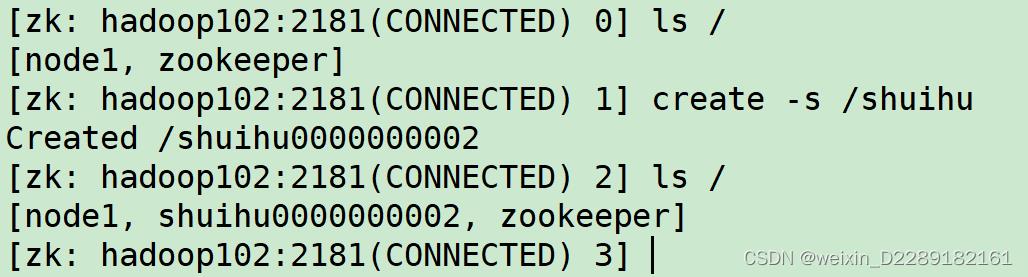
-
get set ls -w (监控节点的子节点变化) get -w(监控节点值变化)
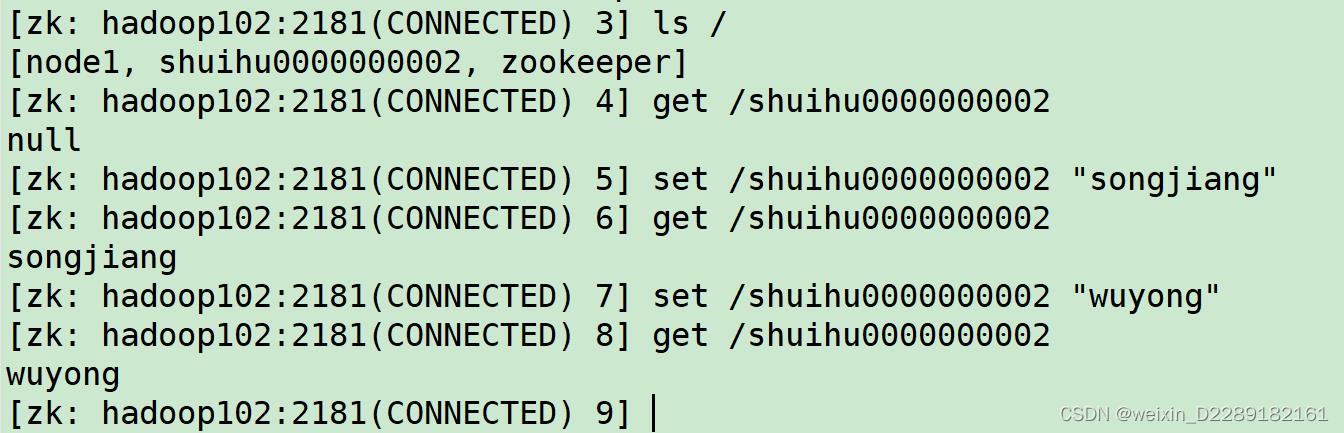




-
stat

-
deleteall
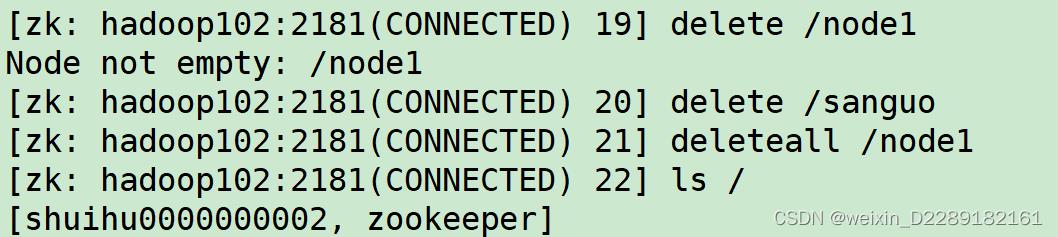
-
ls2查看详细信息

ideaAPI操作
Gitee代码地址:
- 建项目,导依赖,建目录
- 测试连接客户端
- 创建结点
- 获取子节点
- 判断结点是否为空
- 获取数据
- 修改结点下内容
- 删除节点
- 递归删除结点
核心概念
结点类型Stat结构体
- 1

- 2
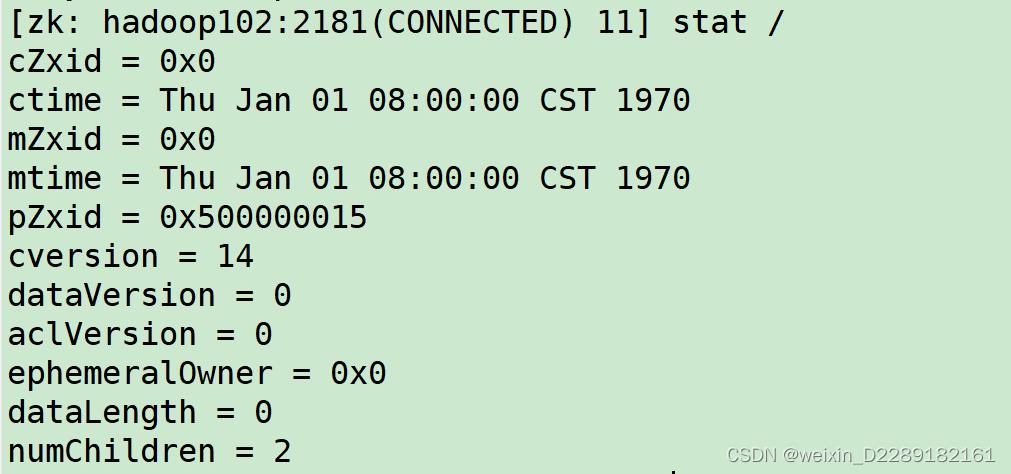
czxid-创建节点的事务zxid
dataversion - znode数据变化号。删除更改数据版本号
dataLength- znode的数据长度
numChildren - znode子节点数量
监听器原理(重点)
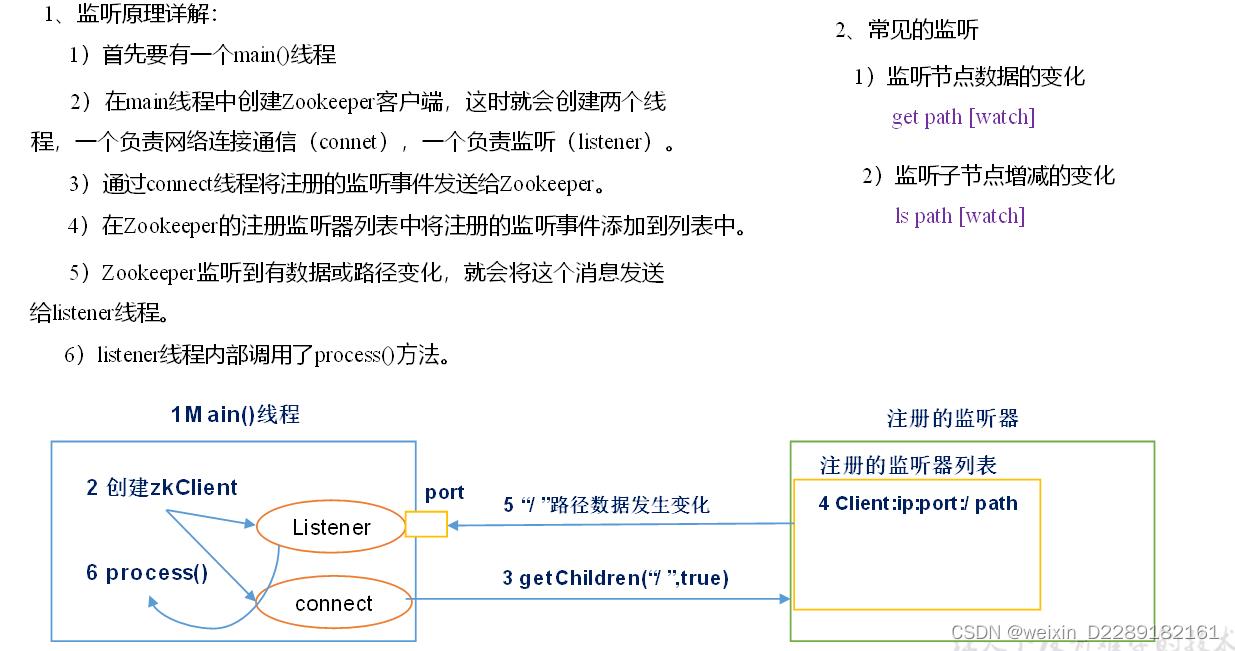
zookeeper是一个文件系统+通知机制的框架。管理框架综合信息,来协调各个服务之间的工作。
首先各个服务到zookeeper注册自己。就是在zk监听列表中添加了一个监听事件。客户端会创建两个线程一个connect负责网络连接通信,另一个负责监听Listener。
获取zk连接对象时候在Watcher()中写process方法,只要将来zk维护的数据发生变化,立刻从监听列表找到。调用Listener()线程,再由此调用process通知到本地,做出相应变化
选举机制(重点)
- 总原则:集群中每台机器参与投票,通过交换选票的到每台机器的最终结果,一旦出现得票总数超过机器总数一半,当选为lender
- 举例:假设有五台服务器组成的Zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据。集群机器顺时启动

特殊情景:当服务器3也就是lender突然宕机,集群会重新选出一个lender,首先比较每台机器czxid(事务ID),最大者当选。极端情况czxid相等,直接比较myid。 - 一般情况下推荐zk集群使用奇数台机器原因?
比如三台机器的集群容错率为1,四台机器容错率也为1。考虑节省资源的情况下,推荐部署奇数台机器
写数据流程
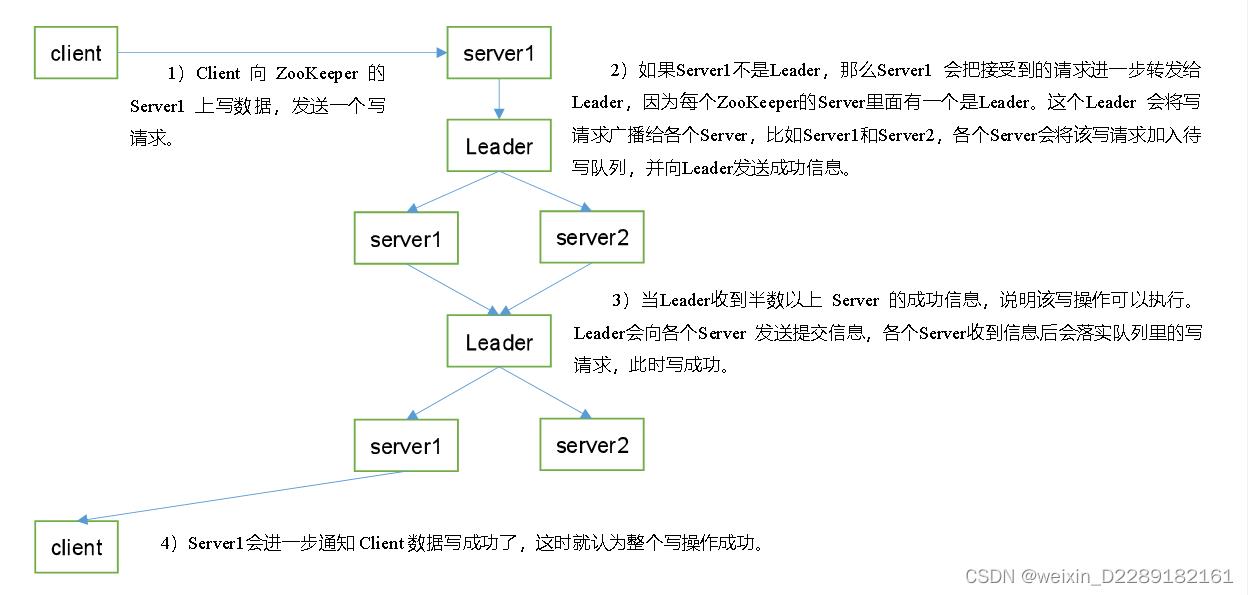
1.客户端向ZK集群中的一台机器server1发送写数据请求
2.server1接收到请求后,请示lender有写数据的请求来了
3.lender拿到请求后,进行广播,让集群每一台机器都准备写数据
4.各个机器将写数据请求加入待写队列,回馈lender成功信息
5.lender受到半数以上的成功信息后,再次广播,都落实写数据请求
6.当数据成功写入后,由server1回应客户端数据写入成功
以上是关于Hadoop生态系统-zookeeper的主要内容,如果未能解决你的问题,请参考以下文章