PDF分割?有了这把魔法剪,PDF任你裁剪(PyPDF2)-
Posted Tisfy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PDF分割?有了这把魔法剪,PDF任你裁剪(PyPDF2)-相关的知识,希望对你有一定的参考价值。
传送门
用PyDPF2实现pdf文件的裁剪
背景故事
我们老师给我们了一些很不错的PDF,为了便于我们打印,把PDF做成了一张上有4页的形式。
但是可能不太方便阅读。于是,想到用python处理一下。

环境准备
使用PyPDF2,如果没有需要先安装。网上教程很多,这里简单说一下:
可以Win+R,输入
cmd并回车,弹出小黑框,输入pip install PyPDF2即可。
过程
首先导入PyPDF2
import PyPDF2
然后定义要处理的PDF文件的路径和要输出的PDF文件的路径
input_file_path = 'C:\\\\Users\\\\LetMeFly\\\\Desktop\\\\lec1_1.pdf'
output_file_path = 'C:\\\\Users\\\\LetMeFly\\\\Desktop\\\\lec1_1-sp.pdf'
output_file = PyPDF2.PdfFileWriter()
获取要处理的PDF的信息
input_file = PyPDF2.PdfFileReader(open(input_file_path, 'rb'))
page_info = input_file.getPage(0) # 这里假设每一页PDF都一样大
width = float(page_info.mediaBox.getWidth()) # 宽度
height = float(page_info.mediaBox.getHeight()) # 高度
page_count = input_file.getNumPages() # 页数
然后先尝试裁剪一个 200 ∗ 200 200*200 200∗200的小PDF(看不懂先别着急,等会会讲)
this_page = input_file.getPage(0) # 获取第1页
this_page.mediaBox.lowerLeft=(0,0)
this_page.mediaBox.lowerRight=(200,0)
this_page.mediaBox.upperLeft = (0,200)
this_page.mediaBox.upperRight = (200,200)
把裁剪出来的小块添加到要输出的PDF中并输出
output_file.addPage(this_page)
output_file.write(open(output_file_path, 'wb'))
总体就是:
import PyPDF2
input_file_path = 'C:\\\\Users\\\\LetMeFly\\\\Desktop\\\\lec1_1.pdf'
output_file_path = 'C:\\\\Users\\\\LetMeFly\\\\Desktop\\\\lec1_1-sp.pdf'
output_file = PyPDF2.PdfFileWriter()
input_file = PyPDF2.PdfFileReader(open(input_file_path, 'rb'))
page_info = input_file.getPage(0) # 这里假设每一页PDF都一样大
width = float(page_info.mediaBox.getWidth()) # 宽度
height = float(page_info.mediaBox.getHeight()) # 高度
page_count = input_file.getNumPages() # 页数
this_page = input_file.getPage(0) # 获取第1页
this_page.mediaBox.lowerLeft=(0,0)
this_page.mediaBox.lowerRight=(200,0)
this_page.mediaBox.upperLeft = (0,200)
this_page.mediaBox.upperRight = (200,200)
output_file.addPage(this_page)
output_file.write(open(output_file_path, 'wb'))
可以看到桌面上多出了一个lec1_1-sp.pdf,打开张这样

像素正好是
200
∗
200
200*200
200∗200
接下来讲解lowerLeft、lowerRight、upperLeft、upperRight为什么是这些参数。
PyPDF2中,获取pdf的宽和高时,长的是高,短的是宽。就像第一张图片,

然而lowerLeft、lowerRight、upperLeft、upperRight中的8个值(其实有4对相同的)不好记,于是我打包了一个函数:
def split(page, tup):
page.mediaBox.lowerLeft=(tup[0],tup[1])
page.mediaBox.lowerRight=(tup[2],tup[1])
page.mediaBox.upperLeft = (tup[0], tup[3])
page.mediaBox.upperRight = (tup[2], tup[3])
使用这个函数时,你只需要把要裁剪的Page、矩形左上角、右下角两个点的xy坐标传入就行了。
如图,坐标只需要传入(1,1,2,3)就行了,分别是左上角的xy和右下角的xy
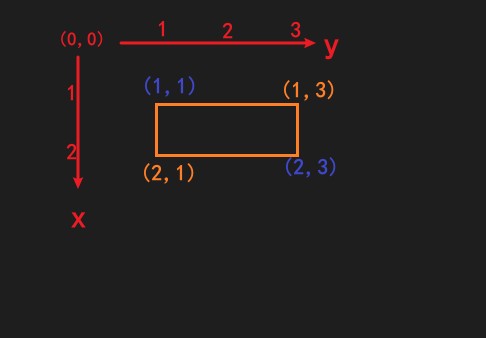
即split(this_page, (1,1,2,3))
所以假如要做如下裁剪

只需要split(this_page, (100,60,180,310))即可
完成代码:
import PyPDF2
input_file_path = 'C:\\\\Users\\\\LetMeFly\\\\Desktop\\\\lec1_1.pdf'
output_file_path = 'C:\\\\Users\\\\LetMeFly\\\\Desktop\\\\lec1_1-sp.pdf'
output_file = PyPDF2.PdfFileWriter()
input_file = PyPDF2.PdfFileReader(open(input_file_path, 'rb'))
def split(page, tup):
page.mediaBox.lowerLeft=(tup[0],tup[1])
page.mediaBox.lowerRight=(tup[2],tup[1])
page.mediaBox.upperLeft = (tup[0], tup[3])
page.mediaBox.upperRight = (tup[2], tup[3])
page_info = input_file.getPage(0) # 这里假设每一页PDF都一样大
width = float(page_info.mediaBox.getWidth()) # 宽度
height = float(page_info.mediaBox.getHeight()) # 高度
page_count = input_file.getNumPages() # 页数
this_page = input_file.getPage(0) # 获取第1页
split(this_page, (100,60,180,310))
output_file.addPage(this_page)
output_file.write(open(output_file_path, 'wb'))
那么如何批量处理一张4页的PDF呢?
篇幅限制,请看这里。
原创不易,转载请附上原文链接哦~
Tisfy:https://letmefly.blog.csdn.net/article/details/117637420
以上是关于PDF分割?有了这把魔法剪,PDF任你裁剪(PyPDF2)-的主要内容,如果未能解决你的问题,请参考以下文章