UI自动化框架,数据驱动 vs 关键字驱动怎么选
Posted 测试萌萌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了UI自动化框架,数据驱动 vs 关键字驱动怎么选相关的知识,希望对你有一定的参考价值。
01 UI自动化测试用例剖析
让我们先从分析一端自动化测试案例的代码开始我们的旅程。以下是我之前写的一个自动化测试的小Demo。这个Demo基于Selenium与Java。

自动化测试小Demo
它要测试的东西其实是要看一下百度搜索能不能返回兴业银行的官网。我们分析一下这段代码都包含些什么东西。
-
第一,这段代码包含了定位符。
熟悉Selenium的都知道,inpubBox和searchButton就是网页的元素,通过By.id实例化,然后driver在findElement 的时候是通过他们的id,就是”kw”和”su”找到他们的。所以”kw” 和”su”就是他们的定位符。

定位符
-
第二,这段代码包含测试数据。
“兴业银行”,“兴业银行欢迎您”就是测试要输入的数据。

测试数据
-
第三部分没前面两部分那么直观。
这段代码在基于”kw”找到inputBox后,往里填入“兴业银行”四个字,然后点击了searchButton提交搜索申请,然后在搜索结果里面寻找“兴业银行欢迎您”的text,然后以是否找到这个text作为assert的标准。这些测试步骤反映的是真实的业务逻辑, 并且不能随意更换顺序。所以第三部分是业务逻辑。

业务逻辑
-
第四部分是业务逻辑里面的每一个步骤的具体操作
例如输入某段文字,或者点击一个按钮等。具体到我们的例子就是sendKeys和click。

具体操作
-
第五部分就是如果把前面四部分都抽出去后,测试代码剩下的东西
基本上就是一些负责准备或者是清理的代码,例如初始化driver等。我把它称为代码骨架。
经上分析,一个自动化测试用例由五部分组成:定位符、测试数据、业务逻辑、具体操作、代码骨架。

UI自动化测试结构
02 数据驱动的自动化测试
如果把测试数据抽取出去,通过数据的改变驱动自动化测试的执行,最终引起测试结果的改变,就是数据驱动的自动化测试。说白了,就是测试数据参数化。
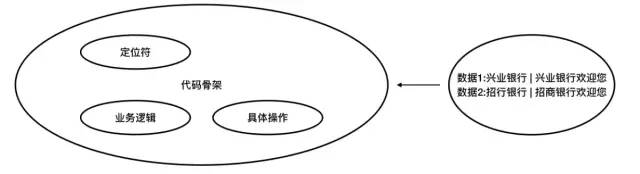
数据驱动
数据驱动的自动化测试适合测试场景与业务逻辑相对简单,变化不是特别大,但是测试数据对测试结果影响大的情景,或者是需要通过大量不同的测试数据对相同的测试场景展开测试的情景。它实现的方式比较简单,但由于业务逻辑还是镶嵌于测试代码里面的,业务逻辑与测试代码还是强耦合的,一旦业务场景发生改变,需要修改测试代码来适应业务的变化。
想要隔离业务对测试代码的影响,就必须使用关键字驱动的方法。
03 关键字驱动的自动化测试
简单来说,关键字驱动的自动化测试,就是在数据驱动的基础上,把具体操作抽取到代码以外,通过具体操作的改变来驱动测试的执行。
这里的说的关键字其实就是具体的操作,例如例子里面的sendKeys和click。但由于具体操作(关键字)是基于业务逻辑的,要想把关键字抽取,业务逻辑也得一同抽取,才能实现真正的关键字驱动。同时,具体操作的对象是定位符定位的元素,所以定位符也必须得一同抽取出代码意外,才能完全隔离业务对代码的影响。

关键字驱动
基于关键字驱动的自动化测试适合业务场景复杂,测试步骤繁多的情景,又或者是希望搭建统一测试平台的情景。它最大的优点是使不懂编程的业务人员可以在不需要读懂代码的情况下,通过更改配置,自由添加新的测试用例或修改现有的测试用例。这一点在敏捷开发里面相当实用,可以把业务卷入到测试当中,让测试用例的准备工作尽可能提前;另外,测试代码与要测试的业务逻辑完全隔离,同一份测试代码可以复用于不同的测试场景,较少了重复开发的成本。但是,它也不是完全没有缺点。
-
首先,并不是所有场景都需要基于关键字驱动的,有些场景数据驱动的方法能解决的话就应该果断选用数据驱动,而不应该过度设计;
-
第二,由于业务逻辑与代码隔离了,代码的可读性将大大降低,单纯的代码基本没有业务含义,要想通过读测试代码来了解业务,基本是不可能了。牺牲了代码的可读性来换取可重用性。
-
第三,由于代码复用了,每一个测试用例的执行都相当于一次全新的测试,这意味着如果不加额外处理,测试报告将被互相覆盖,永远都只保留最后一个测试用例的执行结果。
04 关键字驱动的自动化测试例子
这是我很早之前写的一个关键字驱动的自动化测试的Demo。基本的想法是把定位符、测试数据、业务逻辑、具体操作多抽取到一个叫做testCase.properties的文件。
Parameter用于存贮从testCase.properties读出来的属性,主测试类TestBankIndex通过读取这个文件来驱动测试的执行。关键字所对应的具体操作放在了PageAction里面。
在testCase.Properties里面,通过testCaseNameList来定义测试用例名字,中间用|分割开。testCaseNameList以下,是每一个测试用例的具体测试步骤。每个测试步骤名字以测试用例名字作为前缀,并且其排列顺序就是测试步骤的顺序。然后测试步骤的值以测试所需的操作(关键字)、定位方式、定位表达式、测试数据、超时时间排列得来,中间以|分割。这里有一个比较特别的是断言。如果是断言的话,会有Keyword,用于断言的判断。

testCase.Properties
-
Parameter用于存储testCase.Properties的属性
它其实只是一个简单的Java Bean。

Parameter
-
PageAction用于定义每个关键字对应的具体操作。
我们以search方法为例,通过传入Parameter来获取search需要的元素定位于要输入的搜索文本,然后执行真正的搜索操作,并等待特定的时间。

PageAction
-
TestBankIndex是主测试类
但实际上里面就一个testEachCase方法。里面大量使用Java 反射机制来实例化和执行方法。所以,testEachCase在执行的时候,它不到最后一刻都不知道它要运行哪个测试用例与执行什么操作的,这些完全在testCase.properties里面定义。

TestBankIndex
基本上就是这样。代码没时间优化,很多地方都写的不是很规范,也没有单元测试;测试报告覆盖的问题也没有处理;testCase.properties过于重量级了,什么都往里塞。还没有UI,不方面操作。但作为一个MVP,基本上实现了UI自动化测试框架所需要的功能。
最后: 下方这份完整的软件测试视频学习教程已经整理上传完成,朋友们如果需要可以自行免费领取【保证100%免费】

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!

以上是关于UI自动化框架,数据驱动 vs 关键字驱动怎么选的主要内容,如果未能解决你的问题,请参考以下文章