床长人工智能教程 - 神经网络是如何进行预测的?
Posted 人工智能AI技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了床长人工智能教程 - 神经网络是如何进行预测的?相关的知识,希望对你有一定的参考价值。
朋友们,如需转载请标明出处:http://blog.csdn.net/jiangjunshow
上一篇文章中我们已经知道了如何将数据输入到神经网络中。那么神经网络是如何根据这些数据进行预测的呢?我们将一张图片输入到神经网络中,神经网络是如何预测这张图中是否有猫的呢??
这个预测的过程其实只是基于一个简单的公式:z = dot(w,x) + b。看到这个公式,完全不懂~不少同学可能被吓得小鸡鸡都萎缩了一截。不用怕,看完我下面的解说后,你就会觉得其实它的原理很简单。就像玻璃栈道一样,只是看起来可怕而已。

上面公式中的x代表着输入特征向量,假设只有3个特征,那么x就可以用(x1,x2,x3)来表示。如下图所示。w表示权重,它对应于每个输入特征,代表了每个特征的重要程度。b表示阈值[yù zhí],用来影响预测结果。z就是预测结果。公式中的dot()函数表示将w和x进行向量相乘。(不用怕,在后面的文章《向量化》中我会用很通俗易懂的语言来给大家介绍向量相乘有关的高等数学知识)。我们现在只需要知道上面的公式展开后就变成了z = (x1 * w1 + x2 * w2 + x3 * w3) + b。
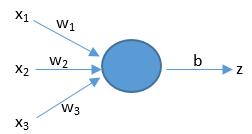
那么神经网络到底是如何利用这个公式来进行预测的呢?下面我通过一个实例来帮助大家理解。
假设周末即将到来,你听说在你的城市将会有一个音乐节。我们要预测你是否会决定去参加。音乐节离地铁挺远,而且你女朋友想让你陪她宅在家里搞事情,但是天气预报说音乐节那天天气特别好。也就是说有3个因素会影响你的决定,这3个因素就可以看作是3个输入特征。那你到底会不会去呢?你的个人喜好——你对上面3个因素的重视程度——会影响你的决定。这3个重视程度就是3个权重。
如果你觉得地铁远近无所谓,并且已经精力衰竭不太想搞事情了,而且你很喜欢蓝天白云,那么我们将预测你会去音乐节。这个预测过程可以用我们的公式来表示。我们假设结果z大于0的话就表示会去,小于0表示不去。又设阈值b是-5。又设3个特征(x1,x2,x3)为(0,0,1),最后一个是1,它代表了好天气。又设三个权重(w1,w2,w3)是(2,2,7),最后一个是7表示你很喜欢好天气。那么就有z = (x1 * w1 + x2 * w2 + x3 * w3) + b = (0 * 2 + 0 * 2 + 1 * 7) + (-5) = 2。预测结果z是2,2大于0,所以预测你会去音乐节。
如果你最近欲火焚身,并且对其它两个因素并不在意,那么我们预测你将不会去音乐节。这同样可以用我们的公式来表示。设三个权重(w1,w2,w3)是(2,7,2),w2是7表示你有顶穿钢板的欲火。那么就有z = (x1 * w1 + x2 * w2 + x3 * w3) + b = (0 * 2 + 0 * 7 + 1 * 2) + (-5) = -3。预测结果z是-3,-3小于0,所以预测你不会去,会呆在家里搞事情。

(CSDN会定期扫黄,如果看不到图片,纯属正常)
预测图片里有没有猫也是通过上面的公式。经过训练的神经网络会得到一组与猫相关的权重。当我们把一张图片输入到神经网络中,图片数据会与这组权重以及阈值进行运算,结果大于0就是有猫,小于0就是没有猫。
你平时上网时有没有发现网页上的广告都与你之前浏览过的东西是有关联的?那是因为很多网站都会记录下你平时的浏览喜好,然后把它们作为权重套入到上面的公式来预测你会购买什么。如果你发现你朋友电脑手机上的网页里面老是出现一些情趣用品或SM道具的广告,那你朋友肯定是个性情中人。
上面那个用于预测的公式我们业界称之为逻辑回归,这个名字有点奇怪,大家记住就行了,只是个名字而已。
最后再稍微提一下激活函数。在实际的神经网络中,我们不能直接用逻辑回归。必须要在逻辑回归外面再套上一个函数。这个函数我们就称它为激活函数。激活函数非常非常重要,如果没有它,那么神经网络的智商永远高不起来。而且激活函数又分好多种。后面我会花好几篇文章来给大家介绍激活函数。在本篇文章的末尾,我只给大家简单介绍一种叫做sigmoid的激活函数。它的公式和图像如下。
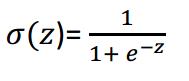
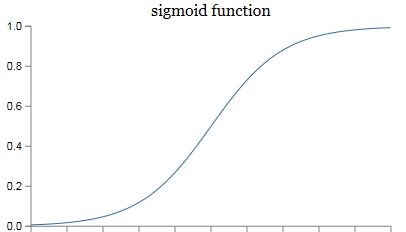
我们在这里先只介绍它的一个用途——把z映射到[0,1]之间。上图中的横坐标是z,纵坐标我们用y’来表示,y’就代表了我们最终的预测结果。从图像可以看出,z越大那么y’就越靠近1,z越小那么y’就越靠近0。那为什么要把预测结果映射到[0,1]之间呢?因为这样不仅便于神经网络进行计算,也便于我们人类进行理解。例如在预测是否有猫的例子中,如果y’是0.8,就说明有80%的概率是有猫的。
激活函数就只介绍这些,后面的文章再详细介绍它。有些同学可能会不乐意,要求我多说一些,其实我也想口若悬河地扒拉扒拉说一大堆,因为把一件简单的事给说复杂了是很容易的,而要把一件复杂的事给说简单了是非常非常难的。每篇文章我都是改了又改,删了又删,目的就是让它尽可能的通俗易懂。说多了反而让你们变得晕头转向。例如其实在逻辑回归公式中,w其实应该写成w.T,因为实际运算中我们需要w的转置矩阵。你是不是有点晕头转向了~~我在教程前面的文章里通常会省略掉一些细节,因为那些细节较难,而且他们对于大家理解最重要的理论部分又没有帮助;在后面的文章,我会慢慢地把他们给介绍出来,让你们循序渐进,快乐地在不知不觉中学会人工智能这一尖端的高科技。
在本篇文章中,我们知道了神经网络是如何进行预测的。那么它又是如何判断自己是否预测正确了的呢?如果发现自己预测错误了,他又是如何从错误中进行学习,使自己越来越聪明的呢?后面的文章我将给大家揭晓!
以上是关于床长人工智能教程 - 神经网络是如何进行预测的?的主要内容,如果未能解决你的问题,请参考以下文章