kafka的存储和容错机制
Posted csm_81
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka的存储和容错机制相关的知识,希望对你有一定的参考价值。
文章目录
(一)Topic、Partition扩展
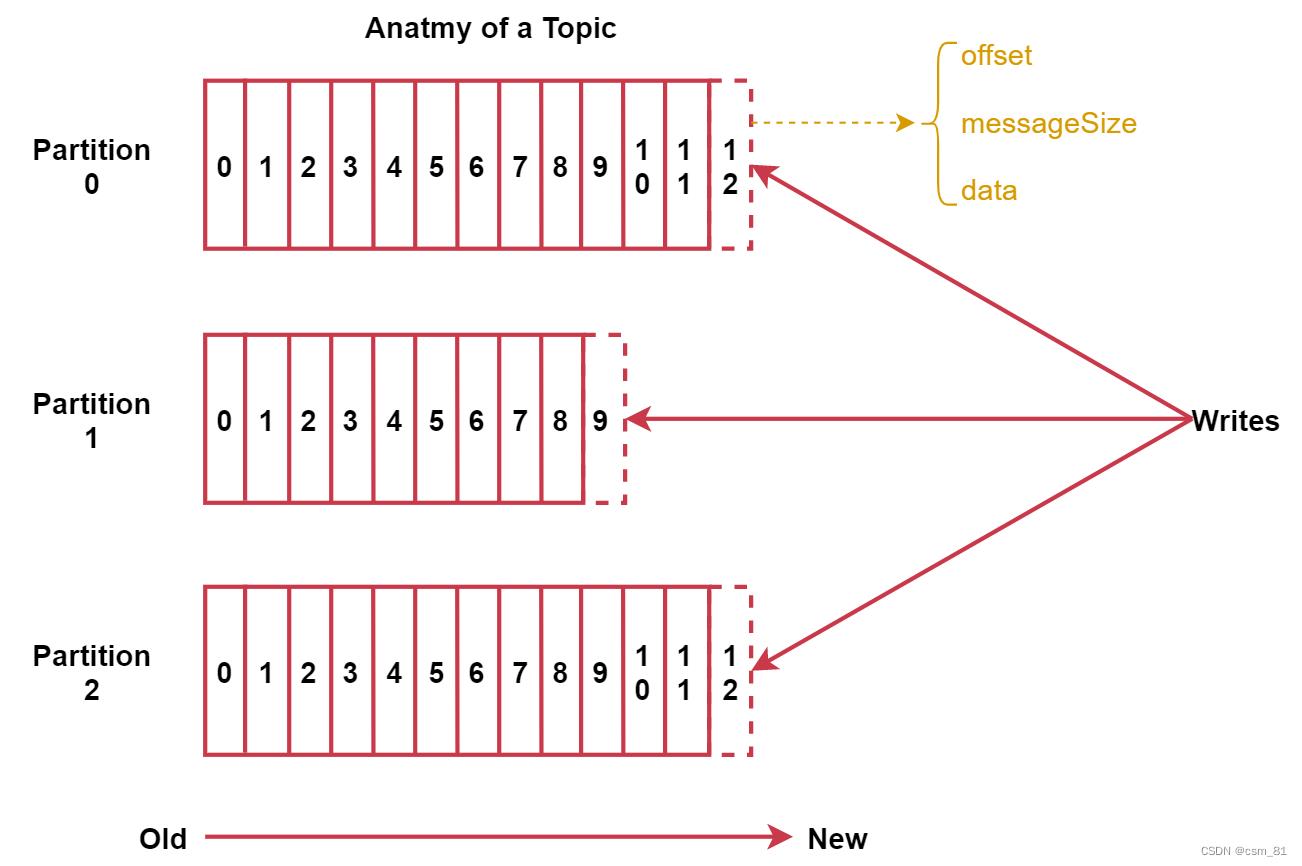
每个partition在存储层面是append log文件。
新消息都会被直接追加到log文件的尾部,每条消息在log文件中的位置称为offset(偏移量)。
越多partitions可以容纳更多的consumer,有效提升并发消费的能力。
- 具体什么时候增加topic的数量?什么时候增加partition的数量呢?
业务类型增加需要增加topic、数据量大需要增加partition
(二)Message扩展
每条Message包含了以下三个属性:
- offset 对应类型:long 表示此消息在一个partition中的起始的位置。可以认为offset是partition中Message的id,自增的
- MessageSize 对应类型:int32 此消息的字节大小。
- data 是message的具体内容。
如图:
(三)kafka存储策略
在kafka中每个topic包含1到多个partition,每个partition存储一部分Message。每条Message包含三个属性,其中有一个是offset。
问题:offset相当于partition中这个message的唯一id,那么如何通过id高效的找到message?
分段+索引
kafak中数据的存储方式是这样的:
1、每个partition由多个segment【片段】组成,每个segment中存储多条消息,
2、每个partition在内存中对应一个index,记录每个segment中的第一条消息偏移量。
Kafka中数据的存储流程是这样的:
生产者生产的消息会被发送到topic的多个partition上,topic收到消息后往对应partition的最后一个segment上添加该消息,segment达到一定的大小后会创建新的segment。
来看这个图,可以认为是针对topic中某个partition的描述。
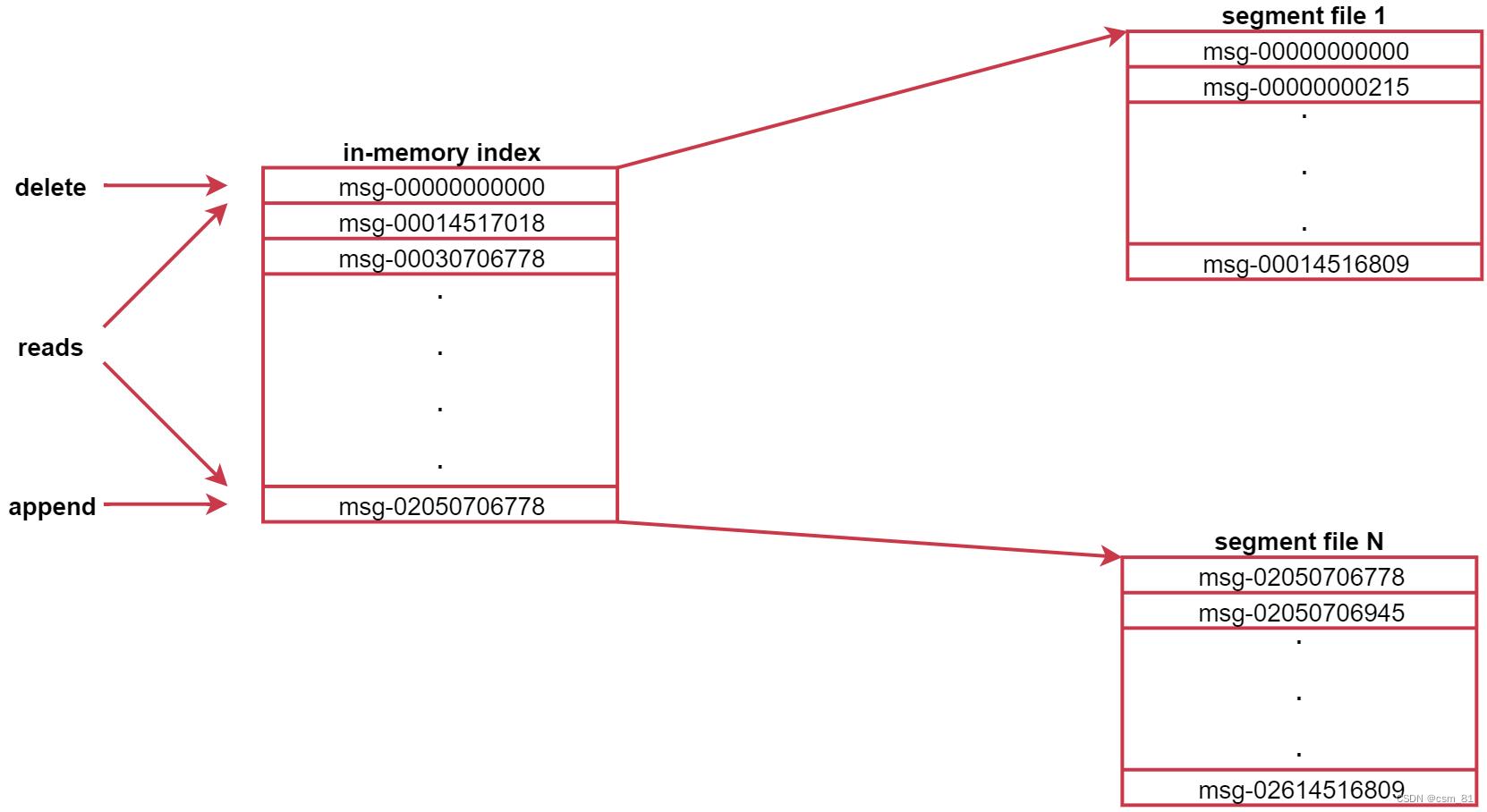
图中左侧就是索引,右边是segment文件,左边的索引里面会存储每一个segment文件中第一条消息的偏移量,由于消息的偏移量都是递增的,这样后期查找起来就方便了,先到索引中判断数据在哪个segment文件中,然后就可以直接定位到具体的segment文件了,这样再找具体的那一条数据就很快了,因为都是有序的。
(四)kafka容错机制
1)当Kafka集群中的一个Broker节点宕机,会出现什么现象?
- 当kafka集群中的broker节点启动之后,会自动向zookeeper中进行注册,保存当前节点信息。
2)当Kafka集群中新增一个Broker节点,会出现什么现象?
- 新加入一个broker节点,zookeeper会自动识别并在适当的机会选择此节点提供服务
但是启动后有个问题:发现新启动的这个节点不会是任何分区的leader?怎么重新均匀分配
1)Broker中的自动均衡策略(默认已经有)
auto.leader.rebalance.enable=true
leader.imbalance.check.interval.seconds 默认值:300
2)手动执行:
bin/kafka-leader-election.sh --bootstrap-server localhost:9092 --election-type preferred --all-topic
以上是关于kafka的存储和容错机制的主要内容,如果未能解决你的问题,请参考以下文章