data.frame操作
Posted 拱头
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了data.frame操作相关的知识,希望对你有一定的参考价值。
| data.frame(..., row.names = NULL, check.rows = FALSE, check.names = TRUE,stringsAsFactors = default.stringsAsFactors()): 用做例子的数据: > country=c("US","US","UK","UK","UK") > gender=c("M","F","F","M","F") > age=c(32,45,25,39,99) > q1=c(5,3,3,3,2) > q2=c(4,5,5,3,2) > q3=c(5,2,5,4,1) > q4=c(5,5,5,NA,2) > q5=c(5,5,2,NA,1) > leadership=data.frame(country,gender,age,q1,q2,q3,q4,q5,stringAsFactors=FALSE) |
|
cbind()
将参数按列合并,保证参数的行数相同。
rbind() 将参数按行合并,保证参数的列数相同。 |
| na.omit(dataframe): 这个函数只显示没有缺失值的行。 |
| subset()函数,这个函数用来选取data.frame中的数据很好用: > subset(leadership,age>=35 | age<24,select=c(q1,q2,q3,q4)) q1 q2 q3 q4 2 3 5 2 5 4 3 3 4 NA 5 2 2 1 2 > subset(leadership,age>=35 | age<24,select=q1:q5) q1 q2 q3 q4 q5 2 3 5 2 5 5 4 3 3 4 NA NA 5 2 2 1 2 1 |
| aggregate(dataframe,by,Fun)函数: 这个函数简单的说,就是将dataframe的数据按照by(一个变量名组成的列表)分组使用Fun函数,返回一个处理后的dataframne。对每一列调用tapply(x,by,Fun) |
by(data,INDICES,FUN):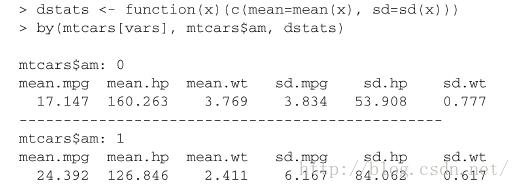 by函数和tapply有点像,但是by函数传入FUN的参数可以是dataframe,tapply传入FUN的参数必须是向量。 |
| nrow(),ncol(): 查看数据框的行数和列数。 |
| apply() 函数,可将一个任意函数“应用”到矩阵、数组、数据框的任何维 度上。 apply 函数的使用格式为: apply(x,MARGIN,FUN,...) 其中, x 为数据对象, MARGIN 是维度的下标, FUN 是由你指定的函数,而 ... 则包括了任何想传 递给 FUN 的参数,例如有一个函数f(x,y,z),调用函数apply(dataframe,1,f,2,3),表示在dataframe的每一行调用f(x,2,3)。在矩阵或数据框中, MARGIN=1 表示行, MARGIN=2 表示列。 apply(algae,1,function(x)sum(is.na(x)))指令解释:统计数据框algae每行数据有多少个缺失值。 |
| tail(dataframe,n): 取数据框最后几行。 |
| head(dataframe,n): 取前几行数据。 |
| dataframe$新列名= x1: 增加新列。 |
| 据框中的元素是通过 dataframe[row indices , column indices] 这样的记号来访问的。 |
| merge(x, y, by = intersect(names(x), names(y)), by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all, sort = TRUE, suffixes = c(".x",".y"), incomparables = NULL, ...)函数: 用来将两个dataframe进行等值连接。 |
| drop参数: 在提取dataframe的行或者列的时候,通过设置,drop=FALSE可以放置提取的行或者列变为向量结构,保持dataframe结果。 例如: > class(leadership[,1]) [1] "factor" > class(leadership[,1,drop=FALSE]) [1] "data.frame" |
| stats::complete.cases(dataframe): 返回一个向量,此向量标志了dataframe里哪些行没有空值。 |
以上是关于data.frame操作的主要内容,如果未能解决你的问题,请参考以下文章