flink学习day05:checkpoint 原理与实践
Posted 黑马程序员官方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flink学习day05:checkpoint 原理与实践相关的知识,希望对你有一定的参考价值。
flink checkpoint
checkpointe是什么?
基于state出发,flink基于与state可以做非常多复杂的事情,但是state是存储在内存中,内存中的数据是不安全的易丢失的,所以flink为了解决这个问题就引入了checkpointed机制,所谓的checkpointe就是把整个flink job的某一瞬间的状态数据进行快照(拍照),后续可以从这个快照(持久到外部存储)。checkponite是可以周期性执行。
state 与checkpoint?
state就是某个一个task/operator的状态数据,存储在内存中
checkpoint是把state数据持久化存储的机制,可以周期性的执行。
2 checkpoint工作流程
就是希望把flinkjob 某一瞬间的所有状态数据全部持久化出来,存储到hdfs,
困难:flink job是一个分布式的程序,是不是可以考虑每个节点的task自己先拍照,然后最终合并到一起,这样也是一个大合照。
如果是多个人如何要求大家是同一瞬间和同一刻进行的这个动作,可以从时间点上控制,
但是对于程序我们如何实现每个task拍快照时所谓的时刻(不是时间)相同的呢?而是要求大家处理的数据是同一个时把状态记录下来。
因此flink的checkpoint是向数据流中加入一个barrier,每个operator收到这个barrier时把自己的state持久化出去,等到每个operator都进行这个checkpoint动作那就可以认为在这个barrier之前所有的数据都已经被所有operator处理过了。
所以从checkpoint恢复数据一定是不会丢失和重复的!!
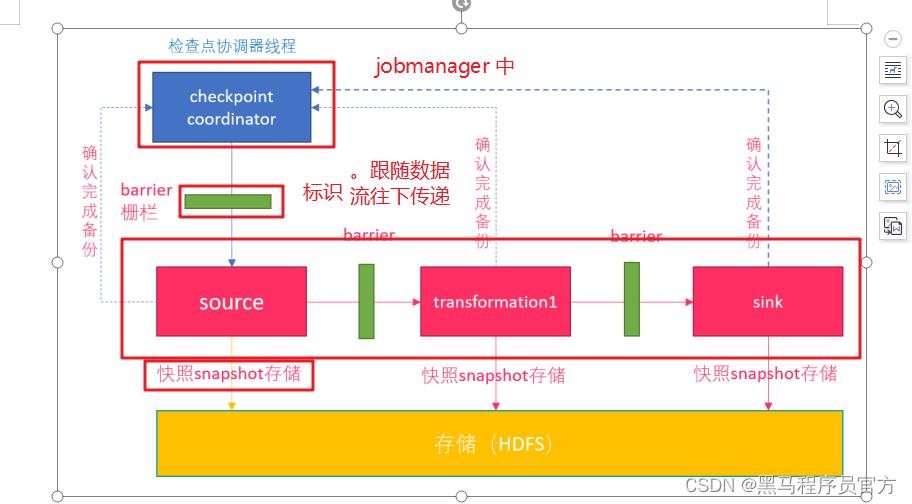
一次checkpointe涉及的角色:
jobmanager–>checkpoint coordinator
所有的operator
persistent storage
checkpoint可选外部存储介质
memorystatebackend

基于文件系统的statebackend 推荐使用hdfsstatebackend

基于RocksDB的statebackend 建议如果是有超大状态数据以及希望进行增量checkpoint时使用这种方式的statebanckend

总结:
flink checkpoint可选的外部持久化介质有三种
memory statebackend:不建议,开发测试
fsstatebackend:生产建议使用,而且使用的hdfs
rocksdbstatebackend:生产可以使用,需要taskmanager装有rocksdb;有超大状态的时候可以考虑使用,以及需要增量checkpoint时使用。
checkpoint设置方式
1 修改flink-conf.yaml:全局修改,影响所有的程序
2 通过程序env.setstatebackend指定持久化介质类型,如果设置是rocksdb需要我们添加rocksdb的依赖。
具体的案例:
需求:自定义发送字符串数据,开启ck相关属性,查看确认是否有数据在指定目录下生成。
代码:
package cn.itcast.ck
import java.util.concurrent.TimeUnit
import org.apache.flink.runtime.state.filesystem.FsStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig
import org.apache.flink.streaming.api.functions.source.RichSourceFunction, SourceFunction
import org.apache.flink.streaming.api.scala.DataStream, StreamExecutionEnvironment
import org.apache.flink.api.scala._
/*
演示ck相关配置
*/
object CheckPonitDemo
def main(args: Array[String]): Unit =
/*
1 获取运行环境
2 设置ck相关属性
3 自定义数据源source,发送字符串数据
4 打印
5 启动
*/
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2 设置ck属性
// 2.1开启ck //指定使用hdfsstatebackend
env.setStateBackend(new FsStateBackend("hdfs://node1:8020/flink/ck_demo"))
//2.2 设置checkpoint的周期间隔 默认是没有开启ck,需要通过指定间隔来开启ck
env.enableCheckpointing(1000)
//2.3 设置ck的执行语义,最多一次,至少一次,精确一次
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
//2.4 设置两次ck之间的最小时间间隔,两次ck之间时间最少差500ms
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// 2.5 设置ck的超时时间,如果超时则认为本次ck失败,继续一下一次ck即可,超时60s
env.getCheckpointConfig.setCheckpointTimeout(60000)
//2.6 设置ck出现问题,是否让程序报错还是继续任务进行下一次ck,true:让程序报错,false:不报错进行下次ck
//如果是false就是ck出现问题我们允许程序继续执行,如果下次ck成功则没有问题,但是如果程序下次ck也没有成功,
//此时程序挂掉需要从ck中恢复数据时可能导致程序计算错误,或者是重复计算数据。
env.getCheckpointConfig.setFailOnCheckpointingErrors(false)
// 2.7设置任务取消时是否保留检查点 retain:则保存检查点数据,delete:删除ck作业数据
env.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
//2.8 设置程序中同时允许几个ck任务同时进行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
// 3自定义source
val strDs: DataStream[String] = env.addSource(
new RichSourceFunction[String]
var flag = true
override def run(ctx: SourceFunction.SourceContext[String]): Unit =
while (flag)
ctx.collect("hello flink")
TimeUnit.SECONDS.sleep(1)
override def cancel(): Unit =
flag = false
)
//4 打印
strDs.print()
// 4启动
env.execute()
总结:
相关属性需要设置如上所示,如果生产中需要结合数据量以及你对数据精确性要求,只要ck不过于频繁降低程序的实时性即可。建议使用hdfsstatebackend保证ck的稳定性。
flink重启策略
基于flink的ck进行容错处理之后,如果程序出现异常或者崩溃我们考虑可以让程序自动重启并恢复到犯错之前的状态(借助ck持久化的state)继续运行。
flink重启策略如何设置:
1 flink-conf.yaml:全局有效
2 env.setrestartStrategy:指定当前程序的重启策略
一般是与ck结合使用:
1 如果没有ck则没有重启,
2 如果设置ck,但是不设置重启策略,会进行无限的重启
重启策略介绍:三种
固定延迟重启策略
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 重启次数
Time.of(10, TimeUnit.SECONDS) // 重启时间间隔
))
job会重启三次,每次间隔是10s
失败率重启:
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个测量时间间隔最大失败次数
Time.of(5, TimeUnit.MINUTES), //失败率测量的时间间隔
Time.of(10, TimeUnit.SECONDS) // 两次连续重启的时间间隔
))
5分钟内重启三次,每次间隔是10s;如果5分钟内超过三次则程序退出,不再重启。
无重启策略
程序出现错误直接退出不会重启。
演示案例代码:
package cn.itcast.ck
import java.util.concurrent.TimeUnit
import org.apache.flink.api.common.restartstrategy.RestartStrategies
import org.apache.flink.api.common.state.ListState
import org.apache.flink.api.scala._
import org.apache.flink.runtime.state.filesystem.FsStateBackend
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.scala.DataStream, StreamExecutionEnvironment
/*
演示flink重启策略
*/
object RestartDemo
def main(args: Array[String]): Unit =
/*
* 1.获取执行环境
2.设置检查点机制:路径,重启策略
3.自定义数据源
(1)需要继承SourceFunction
(2)让程序报错,抛出异常
4.数据打印
5.触发执行
*/
//1 创建流处理运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//方便观察数据,设置并行度为1
env.setParallelism(1)
// 2 设置检查点相关属性,重启策略
env.enableCheckpointing(1000) //开启ck,每秒执行一次
//设置检查点存储数据路径
env.setStateBackend(new FsStateBackend("hdfs://node1:8020/flink/ck"))
//任务取消时,保存检查点数据(后续可以从检查点中恢复数据)
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
// 设置可以同时进行几个ck任务
env.getCheckpointConfig.setMaxConcurrentCheckpoints(2)
//固定延迟重启策略: 程序出现异常的时候,重启3次,每次延迟5秒钟重启,超过3次,程序退出
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000))
// 2 自定义source
val sourceDs: DataStream[Long] = env.addSource(new MySource())
// 3 打印数据
sourceDs.print()
// 4 启动
env.execute()
// 2 自定义source 实现sourcefunction,以及checkpointedfunction
class MySource extends SourceFunction[Long]
var flag = true
//定义发送数据的初始值
var offset = 0L
//定义Liststate
var offsetListState: ListState[Long] = null
//2.1 生成数据的方法
override def run(ctx: SourceFunction.SourceContext[Long]): Unit =
while (flag)
//发送数据,实现发送一个数值,每次增加1 ,来表是所谓消费者的偏移量数据,offset应该从offsetListstate中获取,获取不到再从0开始
offset += 1
ctx.collect(offset)
println("发送数据 offset>>" + offset)
TimeUnit.SECONDS.sleep(1)
//设置故障,程序遇到异常
if (offset % 5 == 0)
println("程序遇到异常。。。,将要重启。。")
throw new RuntimeException("程序遇到异常。。。,将要重启。。")
override def cancel(): Unit =
flag = false
flink savepoint
savepoint:手动触发的checkpoint,全量持久化,操作比较重,由开发人员手动触发手动恢复,集群升级,任务代码升级等
checkpoint:程序自动管理,依据我们配置的ck的属性和重启策略来恢复task,小的错误例如网络抖动导致的超时

savepoint案例
需求:
我们实现一个wordcount案例,我们手动触发savepoint,然后停止程序,紧接着手动恢复程序到savepoint状态,我们判断单词是从0开始还是从savepoint中开始
代码:
package cn.itcast.sp
import java.util.concurrent.TimeUnit
import org.apache.flink.api.common.restartstrategy.RestartStrategies
import org.apache.flink.api.scala._
import org.apache.flink.runtime.state.filesystem.FsStateBackend
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.scala.DataStream, StreamExecutionEnvironment
/*
演示flink中savepoint使用
*/
object SavepointDemo
def main(args: Array[String]): Unit =
/*
* 1.获取执行环境
2.设置检查点机制:路径,重启策略
3.自定义数据源
(1)需要继承SourceFunction
(2)发送字符串
4. 单词统计 数据打印
5.触发执行
*/
//1 创建流处理运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//方便观察数据,设置并行度为1
env.setParallelism(1)
// 2 设置检查点相关属性,重启策略
env.enableCheckpointing(1000) //开启ck,每秒执行一次
//设置检查点存储数据路径
env.setStateBackend(new FsStateBackend("hdfs://node1:8020/flink/ck"))
//任务取消时,保存检查点数据(后续可以从检查点中恢复数据)
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
// 设置可以同时进行几个ck任务
env.getCheckpointConfig.setMaxConcurrentCheckpoints(2)
//固定延迟重启策略: 程序出现异常的时候,重启3次,每次延迟5秒钟重启,超过3次,程序退出
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000))
// 2 自定义source
val sourceDs: DataStream[String] = env.addSource(new MySource())
// 3 打印数据
sourceDs.flatMap(_.split(" ")).map(_ -> 1).keyBy(0).sum(1).print()
// 4 启动
env.execute()
// 2 自定义source 实现sourcefunction,以及checkpointedfunction
class MySource extends SourceFunction[String]
var flag = true
//2.1 生成数据的方法
override def run(ctx: SourceFunction.SourceContext[String]): Unit =
while (flag)
ctx.collect("hello world")
TimeUnit.SECONDS.sleep(1)
override def cancel(): Unit =
flag = false
总结savepoint
1 手动触发state持久化到具体指定的路径
执行savepoint
bin/flink savepoint jobid savepoint路径
恢复数据到指定的savepoint
bin/flink run -s 之前savepoint路径 --class xxx /root/sp.jar
savepoint就像是手动checkpoint!!
flink中一致性语义
讨论分布式计算程序入spark,flink的一致性语义到底在说啥呢?
通俗理解一致性语义:指的是一条数据进入处理程序之后被处理几次,程序会不会丢失或者重复计算数据。
总结
flink中端到端一致性语义
如果flink程序在两次ck之间失败了,如何恢复?因为程序重启之后是恢复到上次成功的ck出,又因为现在程序是在两次ck之间失败了,从上一次ck成功处程序又处理了部分数据并且输出到外部系统了。因此如果只是简单的把程序恢复到上次成功的ck处,会导致程序重复计算部分数据。
所以flink引出了两阶段提交:
1 上一次ck成功之后,开启一个pre-cmmit阶段,(到下一次ck成功,这期间所有的操作都是预提交,可撤回的)
2 只有等到所有operator都完成了ck,这时在进行第二阶段任务,真正提交commit.
source:如kafka可以重放数据
flink程序:通过ck机制保证一致性语义
sink:输出系统要有事务机制,可以pre-cmmit。

flink kafka 端到端一致性语义案例
需求:
使用socket发送数据,flink接收消息之后发送到kafka中,使用flinkkafkaproducer011(两阶段提交协议)。
两阶段提交协议是依赖ck
代码:
使用 flinkkafkaproducer生产数据(默认实现了两阶段提交的方法),直接使用即可。
package cn.itcast.twophase
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.runtime.state.filesystem.FsStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011
import org.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper
import org.apache.kafka.clients.producer.ProducerConfig
//使用socket发送数据,flink接收消息之后发送到kafka中,使用flinkkafkaproducer011(两阶段提交协议)。
object SocketToKafkaTwoPhaseDemo
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2 设置ck属性
// 2.1开启ck //指定使用本地fsstatebackend
env.setStateBackend(new FsStateBackend("file:///e://data//checkpoint-demo//"))
//2.2 设置checkpoint的周期间隔 默认是没有开启ck,需要通过指定间隔来开启ck
env.enableCheckpointing(10000)
//2.3 设置ck的执行语义,最多一次,至少一次,精确一次
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
//2.4 设置两次ck之间的最小时间间隔,两次ck之间时间最少差500ms
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// 2.5 设置ck的超时时间,如果超时则认为本次ck失败,继续一下一次ck即可,超时60s
env.getCheckpointConfig.setCheckpointTimeout(60000)
//2.6 设置ck出现问题,是否让程序报错还是继续任务进行下一次ck,true:让程序报错,false:不报错进行下次ck
//如果是false就是ck出现问题我们允许程序继续执行,如果下次ck成功则没有问题,但是如果程序下次ck也没有成功,
//此时程序挂掉需要从ck中恢复数据时可能导致程序计算错误,或者是重复计算数据。
env.getCheckpointConfig.setFailOnCheckpointingErrors(false)
// 2.7设置任务取消时是否保留检查点 retain:则保存检查点数据,delete:删除ck作业数据
env.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
//2.8 设置程序中同时允许几个ck任务同时进行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
// 3 读取socket数据
val socketDs = env.socketTextStream("node1", 9999)
// 4 打印
socketDs.print()
// 5 输出到kafka
var topic = "test"
val prop = new Properties()
prop.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092")
//设置连接kafka事务的超时时间,flinkproducer默认事务超时时间是1h,kafka中默认事务超时时间是15分钟
prop.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 60000 * 15 + "") //设置客户端事务超时时间与kafka保持一致
socketDs.addSink(new FlinkKafkaProducer011[String](
topic,
new KeyedSerializationSchemaWrapper(new SimpleStringSchema()),
prop,
//设置producer的语义,默认是at-least-once
FlinkKafkaProducer011.Semantic.EXACTLY_ONCE
))
// 6 启动
env.execute()
总结:
(1)写入kafka保证exactly-once,可以使用flinkkafkaproducer011,
(2) 指定producer的一致性语义为exactly-once
注意:
1 指定flinkproducer作为kafkaclinet的事务超时时间不能大于kafka的事务超时时间!!
使用flink消费kafka数据,默认读取数据是read_uncommitted,可以读取提交和未提交的数据,我们验证效果需要指定读取已提交的数据。
代码:
package cn.itcast.twophase
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.DataStream, StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.clients.producer.ProducerConfig
//测试flink+kafka 一致性语义效果
// 使用flink消费kafka中数据
object KafkaExactlyoneceTest
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
var topic = "test"
val prop = new Properties()
prop.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092")
//设置消费者的隔离级别,默认是读取未提交数据 read_uncommitted
prop.setProperty(ConsumerConfig.ISOLATION_LEVEL_CONFIG,"read_committed")
val kafkaDs: DataStream[String] = env.addSource(new FlinkKafkaConsumer011[String](
topic,
new SimpleStringSchema(),
prop
))
//打印
kafkaDs.print("测试kafka 一致性结果数据>>")
//启动
env.execute()
flink mysql端到端一致性语义案例
//需求:
从kafka中消费数据然后写入mysql,但是要求使用两阶段提交协议保证一致性语义。自定义mysqlsink并且实现两阶段提交的相关方法
代码:
package cn.itcast.twophase
import java.sql.Connection, DriverManager
import java.util.Properties
import org.apache.flink.api.common.ExecutionConfig
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.common.typeutils.base.VoidSerializer
import org.apache.flink.api.java.typeutils.runtime.kryo.KryoSerializer
import org.apache.flink.api.scala._
import org.apache.flink.runtime.state.filesystem.FsStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig
import org.apache.flink.streaming.api.functions.sink.SinkFunction, TwoPhaseCommitSinkFunction
import org.apache.flink.streaming.api.scala.DataStream, StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.clients.producer.ProducerConfig
//测试flink+mysql 一致性语义效果 ,两阶段要结合ck才能实现,业务:单词计数,然后写入mysql指定表中
// 使用flink消费kafka中数据
object KafkaToMsqlDemo
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2 设置ck属性
// 2.1开启ck //指定使用本地fsstatebackend
env.setStateBackend(new FsStateBackend("file:///e://data//checkpoint-demo2//"))
//2.2 设置checkpoint的周期间隔 默认是没有开启ck,需要通过指定间隔来开启ck
env.enableCheckpointing(10000)
//2.3 设置ck的执行语义,最多一次,至少一次,精确一次
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
//2.4 设置两次ck之间的最小时间间隔,两次ck之间时间最少差500ms
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// 2.5 设置ck的超时时间,如果超时则认为本次ck失败,继续一下一次ck即可,超时60s
env.getCheckpointConfig.setCheckpointTimeout(60000)
//2.6 设置ck出现问题,是否让程序报错还是继续任务进行下一次ck,true:让程序报错,false:不报错进行下次ck
//如果是false就是ck出现问题我们允许程序继续执行,如果下次ck成功则没有问题,但是如果程序下次ck也没有成功,
//此时程序挂掉需要从ck中恢复数据时可能导致程序计算错误,或者是重复计算数据。
env.getCheckpointConfig.setFailOnCheckpointingErrors(false)
// 2.7设置任务取消时是否保留检查点 retain:则保存检查点数据,delete:删除ck作业数据
env.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
//2.8 设置程序中同时允许几个ck任务同时进行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
var topic = "test"
val prop = new Properties()
prop.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092")
//设置消费者的隔离级别,默认是读取未提交数据 read_uncommitted
prop.setProperty(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed")
//设置程序消费kafka的便宜量提交策略
prop.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false")
val kafkaConsumer = new FlinkKafkaConsumer011[String](
topic,
new SimpleStringSchema(),
prop
)
//设置kafka消费者偏移量是基于ck成功时提交
kafkaConsumer.setCommitOffsetsOnCheckpoints(true)
val kafkaDs: DataStream[String] = env.addSource(kafkaConsumer)
//打印
kafkaDs.print("读取到的kafka中的数据>>")
//实现单词统计逻辑
val wcDs = kafkaDs.flatMap(_.split(" ")).map(_ -> 1).keyBy(0).sum(1)
//写入mysql,要求使用两阶段协议保证一致性语义为exactly-once
wcDs.addSink(new MysqlTwoPhaseCommit)
//启动
env.execute()
//自定义 sinkfunciton实现TwoPhaseCommitSinkFunction in:(单词,数量) txn:transaction对象(自定义), context:void
class MysqlTwoPhaseCommit extends TwoPhaseCommitSinkFunction[(String, Int), MysqlConnectionSate, Void](
//自定义对象的序列化类型
new KryoSerializer[MysqlConnectionSate](classOf[MysqlConnectionSate], new ExecutionConfig),
//上下文件对象序列化类型
VoidSerializer.INSTANCE
)
//开启事务 ,pre-commit开始阶段, 每次开始ck
override def beginTransaction(): MysqlConnectionSate =
// 获取一个连接
val connection = DriverManager.getConnection("jdbc:mysql://node1:3306/test", "root", "123456")
//执行 ,关闭mysql的事务自动提交动作
connection.setAutoCommit(false) //mysql中默认提交事务是自动提交,改为手动提交,ck成功时flink自动提交
new MysqlConnectionSate(connection)
//执行你的动作
override def invoke(transaction: MysqlConnectionSate, value: (String, Int), context: SinkFunction.Context[_]): Unit =
//读取数据并写入mysql中
val connection = transaction.connection
//sql语句 word是主键,可以根据主键更新,duplicate key update:主键存在则更新指定字段的值,否则插入新数据
var sql = "insert into t_wordcount(word,count) values(?,?) on duplicate key update count= ? "
//获取preparestatement
val ps = connection.prepareStatement(sql)
//赋值
ps.setString(1, value._1)
ps.setInt(2, value._2)
ps.setInt(3, value._2)
ps.executeUpdate() //不是预提交,
// 关闭
ps.close()
//预提交
override def preCommit(transaction: MysqlConnectionSate): Unit =
//invoke中完成
//真正提交
override def commit(transaction: MysqlConnectionSate): Unit =
transaction.connection.commit()
transaction.connection.close()
//回滚
override def abort(transaction: MysqlConnectionSate): Unit =
transaction.connection.rollback()
transaction.connection.close()
//要求 该connect无需被序列化,加上transient关键字可以保证该属性不会随着对象序列化
class MysqlConnectionSate(@transient val connection: Connection)
总结
1 实现twophasecommitsinkfunction,需要注意数据的泛型,以及序列化类型,我们自定义的mysqlconnectionstate的主要作用其实就是存放一个connection对象,供其他方法使用
2 mysqlconnectionstate对象中的connection属性需要添加transient关键字,保证不被序列化
一致性总结:
1 flink程序结合自身ck机制加上外部输出系统和数据源具有重放功能实现了端到端的一致性,但是这种一致性带来的问题就是程序的实时性下降明显,除非对数据的精确性要求很高才使用,一般我们使用语义就是at-least-once即可(这种语义效率最高但是有可能丢失数据)。
flink 异步IO
什么场景使用异步IO?
我们flink在流式计算过程需要与外部存储系统进行交互,默认是同步操作,就是发送请求等待响应,等待过程什么也不做,单纯等待,因此会造成吞吐量下降。同步IO的弊端就是如此。
为了解决同步io,与外部系统交互吞吐量下降明显的问题,出现异步IO,异步io无需单纯等待响应,发送请求之后可以继续发送请求,如果那个请求由返回则处理哪个结果,大大提高吞吐能力。
使用前提
1 要求数据库支持异步请求的api,
2 如果没有异步请求的api,可以变相通过线程池来实现,但是这种方式效率不如上一种。
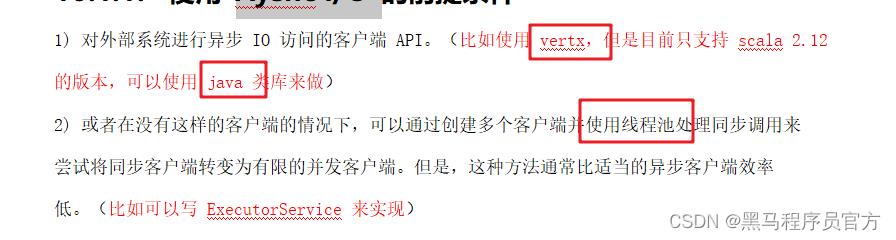
异步IO的简单步骤

关于异步IO 请求发送顺序
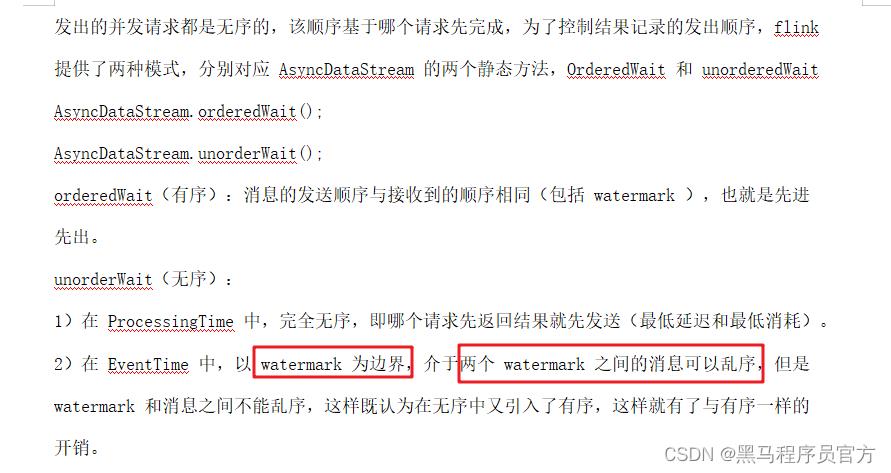
flink中两种顺序
无序:完全不关心发送和响应的顺序 unorderedwatit
有序: orderwait api;processtime 其实是无无序,eventime保证watermark与消息之间不乱序,但是watermark与另一个watermark之间的消息是无序。
异步IO案例
需求
读取集合中的城市id使用异步IO去redis中读取城市名称
redis 准备数据
hset AsyncReadRedis 1 beijing
hset AsyncReadRedis 2 shanghai
hset AsyncReadRedis 3 guangzhou
hset AsyncReadRedis 4 shenzhen
hset AsyncReadRedis 5 hangzhou
hset AsyncReadRedis 6 wuhan
hset AsyncReadRedis 7 chengdu
hset AsyncReadRedis 8 tianjin
hset AsyncReadRedis 9 chongqing
代码:
package cn.itcast.async
import java.util.concurrent.TimeUnit
import org.apache.flink.streaming.api.scala.AsyncDataStream, DataStream, StreamExecutionEnvironment
import org.apache.flink.api.scala._
import org.apache.flink.configuration.Configuration
import org.apache.flink.runtime.concurrent.Executors
import org.apache.flink.streaming.api.scala.async.ResultFuture, RichAsyncFunction
import redis.clients.jedis.Jedis, JedisPool, JedisPoolConfig
import scala.concurrent.ExecutionContext, ExecutionContextExecutor, Future
//读取集合中的城市id使用异步IO去redis中读取城市名称
object AsyncReadRedisDemo
def main(args: Array[String]): Unit =
/*
1 创建运行环境
2 加载集合中的城市id数据
3 使用异步io读取redis
4 打印数据
5 启动
*/
// 1 创建运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2 加载集合中的城市id数据
val cityIdDs = env.fromCollection(List("1", "2", "3", "4", "5", "6", "7", "8", "9"))
// 3 使用异步io
val resDs: DataStream[String] = AsyncDataStream.unorderedWait(
cityIdDs,
new MyAsyncFunciton,
1000,
TimeUnit.MILLISECONDS
)
// 4 打印结果
resDs.print()
// 5启动
env.execute()
//使用 异步IO的步骤
/*
1 准备一个类实现asyncrichfunction
1.1 open 创建或者打开数据连接,一般使用连接池获取连接
1.2 重写timeout方法,处理异步请求超时的问题
1.3 发送异步请求的方法 asyncinvoke
2 使用AsyncDataStream工具类,调用orderedwait等方法实现异步操作流
*/
//@param <IN> The type of the input elements.
//*@ param <OUT>
//The type of the returned elements. 修改flink版本,改为flink.1.8即可
class MyAsyncFunciton extends RichAsyncFunction[String, String]
var jedis: Jedis = null
//创建redis连接池
override def open(parameters: Configuration): Unit =
val config = new JedisPoolConfig
config.setLifo(true)
config.setMaxTotal(10)
config.setMaxIdle(10)
//获取连接时的最大等待毫秒数(如果设置为阻塞时BlockWhenExhausted),如果超时就抛异常, 小于零:阻塞不确定的时间, 默认-1
config.setMaxWaitMillis(-1)
//逐出连接的最小空闲时间 默认1800000毫秒(30分钟)
config.setMinEvictableIdleTimeMillis(1800000)
//最小空闲连接数, 默认0
config.setMinIdle(0)
//每次逐出检查时 逐出的最大数目 如果为负数就是 : 1/abs(n), 默认3
config.setNumTestsPerEvictionRun(3)
//对象空闲多久后逐出, 当空闲时间>该值 且 空闲连接>最大空闲数 时直接逐出,不再根据MinEvictableIdleTimeMillis判断 (默认逐出策略)
config.setSoftMinEvictableIdleTimeMillis(1800000)
//在获取连接的时候检查有效性, 默认false
config.setTestOnBorrow(false)
//在空闲时检查有效性, 默认false
config.setTestWhileIdle(false)
//初始化连接池对象
val pool = new JedisPool(config, "node2", 6379)
jedis = pool.getResource
//关闭连接
override def close(): Unit =
jedis.close()
//处理异步请求超时的方法,否则默认超时会报出异常
override def timeout(input: String, resultFuture: ResultFuture[String]): Unit =
println("input >>" + input + ",,,请求超时。。。")
//定义一个异步回调的上下文件
implicit lazy val executor: ExecutionContextExecutor = ExecutionContext.fromExecutor(Executors.directExecutor())
//异步请求方法:input:输入数据, resultfutrue:异步请求结果对象
def asyncInvoke(input: String, resultFuture: ResultFuture[String]): Unit =
//执行异步请求,请求结果封装在resultfuture中
Future
val result = jedis.hget("AsyncReadRedis", input)
//异步回调返回
resultFuture.complete(Array(input+">>>"+result))
总结:
异步IO适用于我们流式程序需要访问外部存储的场景,mysql,redis,hbase等,
都可以考虑使用异步IO,即使不支持异步请求,也可以变相使用线程池来模拟实现异步的效果。
异步io 原理分析
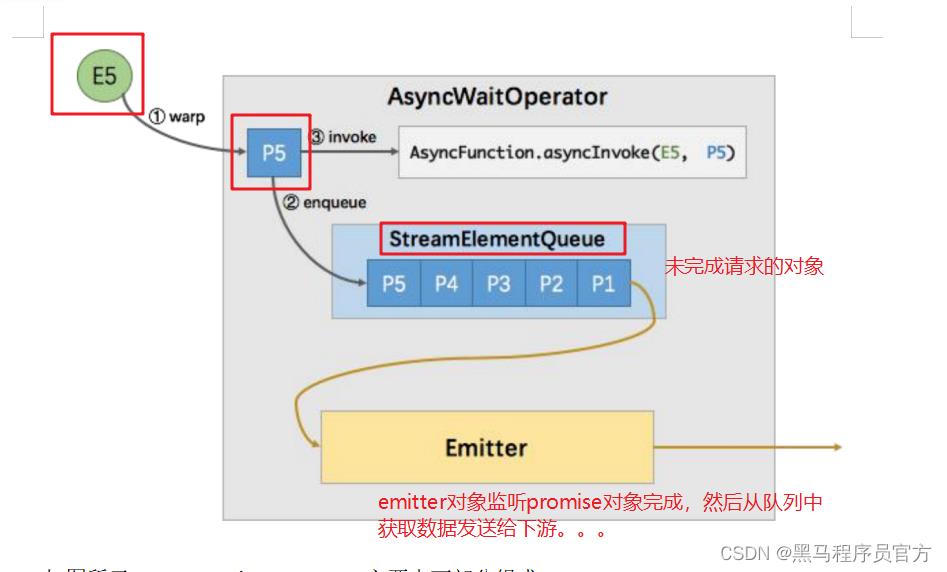
flink 的背压
什么是背压?
就是在流式计算中,一个任务是分多个阶段每个阶段处理的内容以及所在节点都是不一样的,那么可能就会有处理快慢之分,如果处理慢的task其它task不管不顾那最终程序一定会崩溃。
flink如何解决背压?
flink通过上下游节点的资源使用情况来找到程序中处理速度最慢的组件,然后按照这个组件的速度来处理数据,
对于背压机制我们无需做任何处理时flink程序自动实现
参考意义就是尽量保证程序中没有明显处理速度过慢的节点,否则会拖慢整个程序。
flink的内存管理
flink程序也是运行jvm之上
大数据程序运行在jvm之上有哪些问题?
1 使用java对象存储,资源利用率不高
2 jvm会有GC的问题,影响程序性能
3 oom,内存使用超过堆内存
flink针对这些问题从以下几个方面解决:
1 自己定制内存管理,memorysegment结构,并且对taskmanager堆内存进行划分,保证大数据量的对象以及消耗资源的算法等都是运行在memorymanger管理的memorysegment上,
2 flink直接把对象序列化存储,并且提供了高效访问二进制数据方法,减少了序列化和发序列的开销
3 flink 提供了自己一套序列化框架,针对自己程序的特点,
4 flink扩展使用对外内存,来扩展内存,自己直接来管理内存,大大扩充taskmanager的内存空间。
flink sql
批处理案例
package cn.itcast.sql
import org.apache.flink.api.scala.ExecutionEnvironment, _
import org.apache.flink.table.api.Table, TableEnvironment
import org.apache.flink.types.Row
//演示flinksql批处理
//3)创建一个样例类 Order 用来映射数据(订单名、用户名、订单日期、订单金额)
case class Order(id: Int, userName: String, createTime: String, money: Double)
object BatchSql
def main(args: Array[String]): Unit =
/*
1)获取一个批处理运行环境
2)获取一个Table运行环境
3)创建一个样例类 Order 用来映射数据(订单名、用户名、订单日期、订单金额)
4)基于本地 Order 集合创建一个DataSet source
5)使用Table运行环境将DataSet注册为一张表
6)使用SQL语句来操作数据(统计用户消费订单的总金额、最大金额、最小金额、订单总数)
7)使用TableEnv.toDataSet将Table转换为DataSet
8)打印测试
*/
// 1)获取一个批处理运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 2)获取一个Table运行环境
val tenv = TableEnvironment.getTableEnvironment(env)
// 4)基于本地 Order 集合创建一个DataSet source
val orderDataSet: DataSet[Order] = env.fromElements(
Order(1, "zhangsan", "2018-10-20 15:30", 358.5),
Order(2, "zhangsan", "2018-10-20 16:30", 131.5),
Order(3, "lisi", "2018-10-20 16:30", 127.5),
Order(4, "lisi", "2018-10-20 16:30", 328.5),
Order(5, "lisi", "2018-10-20 16:30", 432.5),
Order(6, "zhaoliu", "2018-10-20 22:30", 451.0),
Order(7, "zhaoliu", "2018-10-20 22:30", 362.0),
Order(8, "zhaoliu", "2018-10-20 22:30", 364.0),
Order(9, "zhaoliu", "2018-10-20 22:30", 341.0)
)
// 5)使用Table运行环境将DataSet注册为一张表
tenv.registerDataSet("t_order", orderDataSet)
// 6)使用SQL语句来操作数据(统计用户消费订单的总金额、最大金额、最小金额、订单总数)
// 用户消费订单的总金额、最大金额、最小金额、订单总数。
val sql =
"""
| select
| sum(money) totalMoney,
| max(money) maxMoney,
| min(money) minMoney,
| count(1) totalCount
| from t_order
| group by
| userName
""".stripMargin
// 7)使用TableEnv.toDataSet将Table转换为DataSet
val table: Table = tenv.sqlQuery(sql)
table.printSchema()
tenv.toDataSet[Row](table).print()
总结:
flink 使用sql进行batch开发
1 通过env获取一个tableenv对象
2 数据对象最好是case class类型,这样天生就有字段信息
3 如果对某个dataset想要执行sql查询,需要注册成为一张表,
tenv.regeisterDataSet(表名,datastream)
4 执行查询 tenv.sqlquery(sql),最后返回的是table对象
5 tenv.toDataSetRow,可以获取到dataset
flink 流处理sql 案例
注意地方:

需求:
使用Flink SQL来统计5秒内 用户的 订单总数、订单的最大金额、订单的最小金额。
代码
package cn.itcast.sql
import java.util.UUID
import java.util.concurrent.TimeUnit
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.source.RichSourceFunction, SourceFunction
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.DataStream, StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.types.Row
import scala.util.Random
// 4)创建一个订单样例类 Order ,包含四个字段(订单ID、用户ID、订单金额、时间戳)
case class Order(orderId: String, userId: Int, money: Long, createTime: Long)
//使用Flink SQL来统计5秒内 用户的 订单总数、订单的最大金额、订单的最小金额。
object StreamSql
def main(args: Array[String]): Unit =
/*
1)获取流处理运行环境
2)获取Table运行环境
3)设置处理时间为 EventTime
4)创建一个订单样例类 Order ,包含四个字段(订单ID、用户ID、订单金额、时间戳)
5)创建一个自定义数据源
a.使用for循环生成1000个订单
b.随机生成订单ID(UUID)
c.随机生成用户ID(0-2)
d.随机生成订单金额(0-100)
e.时间戳为当前系统时间
f.每隔1秒生成一个订单
6)添加水印,允许延迟2秒
7)导入 import org.apache.flink.table.api.scala._ 隐式参数
8)使用 registerDataStream 注册表,并分别指定字段,还要指定rowtime字段
9)编写SQL语句统计用户订单总数、最大金额、最小金额
分组时要使用 tumble(时间列, interval '窗口时间' second) 来创建窗口
10)使用 tableEnv.sqlQuery 执行sql语句
11)将SQL的执行结果转换成DataStream再打印出来
12)启动流处理程序
*/
// 1)获取流处理运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2)获取Table运行环境
val tenv = TableEnvironment.getTableEnvironment(env)
// 3)设置处理时间为 EventTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 5)创建一个自定义数据源
val orderDs: DataStream[Order] = env.addSource(new RichSourceFunction[Order]
var flag = true
override def run(ctx: SourceFunction.SourceContext[Order]): Unit =
while(flag)
ctx.collect(Order(UUID.randomUUID().toString, Random.nextInt(3),
Random.nextInt(101), System.currentTimeMillis()))
TimeUnit.SECONDS.sleep(1)
override def cancel(): Unit =
flag = false
)
// 6)添加水印,允许延迟2秒
val wmDs: DataStream[Order] = orderDs.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[Order](Time.seconds(2))
override def extractTimestamp(element: Order): Long =
element.createTime
)
//7)导入 import org.apache.flink.table.api.scala._ 隐式参数
// 8)使用 registerDataStream 注册表,并分别指定字段,还要指定rowtime字段
import org.apache.flink.table.api.scala._
tenv.registerDataStream(
"t_order",
wmDs,
'orderId, 'userId, 'money, 'createTime.rowtime
)
// 9)编写SQL语句统计用户订单总数、最大金额、最小金额
val sql =
"""
|select
| userId,
| count(1) totalCount,
|max(money) maxMoney,
|min(money) minMoney
|from t_order
|group by
|tumble(createTime, interval '5' second),
|userId
|
""".stripMargin
// 10)使用 tableEnv.sqlQuery 执行sql语句
val table = tenv.sqlQuery(sql)
// 11 转为datastream打印
tenv.toRetractStream[Row](table).print()
// 12 启动
env.execute()
总结:
1 *timestamp是关键字不能作为字段的名字(关键字不能作为字段名字)*
2 使用流处理sql如果使用窗口一定要指定基于eventime,还要指定rowtime
3 注册为表的时候,通过’指定字段信息,指定rowtime
new BoundedOutOfOrdernessTimestampExtractor[Order](Time.seconds(2))
override def extractTimestamp(element: Order): Long =
element.createTime
)
//7)导入 import org.apache.flink.table.api.scala._ 隐式参数
// 8)使用 registerDataStream 注册表,并分别指定字段,还要指定rowtime字段
import org.apache.flink.table.api.scala._
tenv.registerDataStream(
"t_order",
wmDs,
'orderId, 'userId, 'money, 'createTime.rowtime
)
// 9)编写SQL语句统计用户订单总数、最大金额、最小金额
val sql =
"""
|select
| userId,
| count(1) totalCount,
|max(money) maxMoney,
|min(money) minMoney
|from t_order
|group by
|tumble(createTime, interval '5' second),
|userId
|
""".stripMargin
// 10)使用 tableEnv.sqlQuery 执行sql语句
val table = tenv.sqlQuery(sql)
// 11 转为datastream打印
tenv.toRetractStream[Row](table).print()
// 12 启动
env.execute()
总结:
1 ***\\*timestamp是关键字不能作为字段的名字(关键字不能作为字段名字)\\****
2 使用流处理sql如果使用窗口一定要指定基于eventime,还要指定rowtime
3 注册为表的时候,通过'指定字段信息,指定rowtime
4 使用window操作,本案例使用滚动窗口,放置在group by之后。
以上是关于flink学习day05:checkpoint 原理与实践的主要内容,如果未能解决你的问题,请参考以下文章