NLP中的对话机器人——预训练基准模型
Posted 愤怒的可乐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP中的对话机器人——预训练基准模型相关的知识,希望对你有一定的参考价值。
引言
本文是七月在线《NLP中的对话机器人》的视频笔记,主要介绍FAQ问答型聊天机器人的实现。
场景二
上篇文章中我们解决了给定一个问题和一些回答,从中找到最佳回答的任务。
在场景二中,我们来实现: 给定新问题,从问答库中找到能回答该问题的最佳答案。
那怎么实现呢? 一种方案是直接匹配问题和答案,计算一个匹配分数,选出匹配分数最高的。
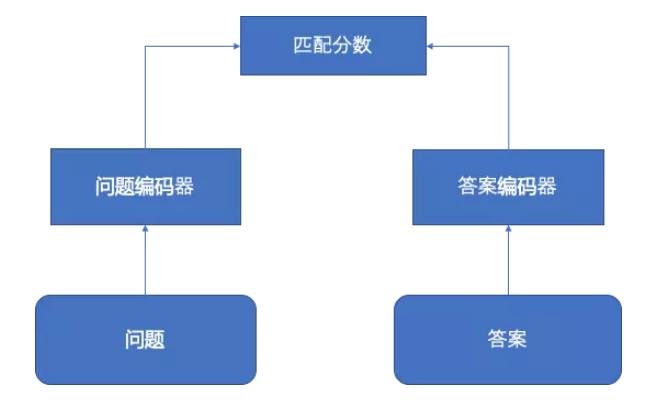
但是基于这些数据集上,这种方法的效果不佳。
另一种做法是类似相似问题检索,从问答库中找到给定问题的最相似的问题,用它的答案作为给定问题的答案。
那如何计算问题之间的相似度呢?
我们这里尝试两个简单的基准模型,分别是基于ELMo和BERT的语句表示,得到问题的句向量,然后通过余弦相似度来计算问题间的相似得分。
我们这里使用现成的ELMo和BERT模型。
ELMo基准模型
数据集
https://pan.baidu.com/s/1z1Rnnk-ubRSvzDu4UvLlIw

实现
可以使用哈工大的预训练的ELMo模型, 仓库为: https://github.com/HIT-SCIR/ELMoForManyLangs
选择简体中文版,可能仓库中的链接打不开,可以从百度云: https://pan.baidu.com/s/1RNKnj6hgL-2orQ7f38CauA?errno=0&errmsg=Aut 下载。
下载并解压之后,我们需要修改config.json当中的config_path参数,改成:configs/cnn_50_100_512_4096_sample.json,即去掉前面的../。
还要安装ELMoForManyLangs的包:
git clone https://github.com/HIT-SCIR/ELMoForManyLangs
cd ELMoForManyLangs
python setup.py install
在安装分词工具pkuseg。
上面步骤都做好之后,我们进行测试,看能否正常工作:
from elmoformanylangs import Embedder
import pkuseg
# 得到我们的elmo encoder
e = Embedder('zhs.model')
sents = ["今天天气真好啊",
"潮水退了就知道谁没穿裤子"]
seg = pkuseg.pkuseg()
sents = [seg.cut(sent) for sent in sents]
print(sents)
embeddings = e.sents2elmo(sents)
print(embeddings)
测试失败了吗,报错:
TypeError: Highway.forward: return type `<class 'torch.Tensor'>` is not a `<class 'NoneType'>`.
解决:
pip uninstall -y overrides
pip install overrides==3.1.0
再次运行,结果:
[['今天', '天气', '真', '好', '啊'], ['潮水', '退', '了', '就', '知道', '谁', '没', '穿', '裤子']]
[array([[ 0.07444969, 0.12170488, 0.18306534, ..., -0.27513036,
0.03082917, -0.6021218 ],
[-0.17950936, 0.3002583 , 0.41858768, ..., -0.7238658 ,
1.5381049 , -1.1729732 ],
[ 0.2640982 , 0.53036195, 0.6604749 , ..., 0.12223349,
0.5540275 , -0.50095123],
[ 0.5308723 , 0.05570847, 0.09236425, ..., -0.9979615 ,
0.13710646, -0.33056557],
[ 0.22956477, 0.43202046, -0.42210087, ..., -0.9834735 ,
0.0821436 , -0.15420763]], dtype=float32), array([[ 0.04015709, 0.42856467, 0.6768381 , ..., -0.10523877,
0.48780942, 0.00312402],
[ 0.5922051 , 0.21770744, 1.1809255 , ..., -0.12190163,
0.61034995, 0.1050753 ],
[ 0.614235 , -0.04580465, -0.03073702, ..., 0.34837866,
0.5443483 , 0.02076633],
...,
[ 0.76723504, 1.413464 , 1.071545 , ..., -1.464156 ,
0.5184709 , -0.5683145 ],
[ 0.13504069, 0.44970334, 0.8248094 , ..., -0.17855829,
-0.39308357, 0.24178888],
[ 0.44061318, 0.6780157 , -0.07952423, ..., -1.2203757 ,
0.14167261, 0.3741262 ]], dtype=float32)]
正常运行,下面可以开始编码了。
首先引入相关包:
import os
import pickle
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
import pandas as pd
import pkuseg
from elmoformanylangs import Embedder # 通过上面的python setup.py install安装
目录结构如下:
具体实现非常简单,只需要把分词后的句子列表传给ELMo模型,就可以得到每个单词的词向量。
为了得到句向量,这里我们采用对句子中每个单词向量求均值的方法。
e = Embedder('zhs.model') # EMLo模型
seg = pkuseg.pkuseg() # 分词工具
# 如果第一次执行(较耗时)
if not os.path.exists("embeddings.pkl"):
train_df = pd.read_csv("financezhidao_filter.csv").sample(frac=0.1) # 只取10%的数据量
# 取最佳答案中的tile和reply字段
candidates = train_df[train_df["is_best"] == 1][["title", "reply"]]
candidate_title = candidates["title"].tolist()
candidate_reply = candidates["reply"].tolist()
# 对title分词
titles = [seg.cut(title) for title in candidates["title"]]
# 计算title中单词词向量
embeddings = e.sents2elmo(titles)
# list of numpy arrays, each array with shape [seq_len * 1024]
# code.interact(local=locals())
# 对seq_len中的单词取平均,这样不管句子长度多少,都可以得到维度一致的句向量
# 除了取平均还可以:求和/取最大值等
candidate_embeddings = [np.mean(embedding, 0) for embedding in embeddings] # a list of 1024 dimensional vectors
# 保存嵌入
with open("embeddings.pkl", "wb") as f:
pickle.dump([candidate_title, candidate_reply, candidate_embeddings], f)
print("Save embeddings to embeddings.pkl")
else:
with open("embeddings.pkl", "rb") as f:
candidate_title, candidate_reply, candidate_embeddings = pickle.load(f)
print("Load embeddings success")
我们可以先为问答库中的问题计算好句向量,然后保存下来,下次直接加载就可以了。
当有了新问题进来,我们只需要按照相同的方法计算新问题的句向量,然后与问答库中的问题计算余弦相似度。
while True:
title = input("你的问题是?\\n > ")
if len(title.strip()) == 0:
continue
title = [seg.cut(title.strip())]
title_embedding = [np.mean(e.sents2elmo(title)[0], 0)] # 得到了新问题的ELMo embedding
scores = cosine_similarity(title_embedding, candidate_embeddings)[0]
# 得到得分最高的5个问题对应的索引
top5_indices = scores.argsort()[-5:][::-1]
print("[得分] 参考问题 对应答案")
for index in top5_indices:
print(f"[scores[index]] candidate_title[index] 对应答案:candidate_reply[index]\\n")
运行效果:
你的问题是?
> 如何发财
2023-02-26 15:07:57,114 INFO: 1 batches, avg len: 4.0
[得分] 参考问题 对应答案
[0.6191050410270691] 如何去理财,教我如何理财 对应答案:欢迎关注招行理财,招行有储蓄、大额存单、基金、理财产品、外汇、黄金、白银等投资可供您选择。风险和收益基本成正比,要求保本就选择储蓄,追求低风险可以考虑货币基金和低风险的理财产品,追求高收益可以了解投资型基金、外汇,黄金及白银,若您当地有招行,可以联系网点客户经理交流理财事宜。
[0.6009083390235901] 100万年轻人现在如何理财 对应答案:要是这100万是你所有的资产、建议你分散投资,可以选择三种不同的风险投资。1、低风险占40%,收益在5%左右一年利息两万左右,可以把钱做银行理财或买国债。2、中风险占50%,收益在11%左右一年利息五六万,可以选择一些靠谱的P2P网贷。3、高风险占10%,收益20%多甚至更高,可以做一些股票、期货类的。要么就找个有升值空间的三、四线城市或海边投资套房子,剩下的理财。
[0.5920484066009521] 聪明女人应该怎样理财 对应答案:所在城市若有招商银行,可了解下招行发售的理财产品,首次购买理财产品,需先办理风险评估,评估后,可购买对应您的风险承受能力等级的理财产品。您可以进入招行主页,点击“理财产品”-“个人理财产品”页面查看,也可通过“搜索”分类您需要的理财产品。温馨提示:购买之前请详细阅读产品说明书。
[0.58339524269104] 年轻人应该如何理财? 对应答案:目前招行个人投资理财方式较多:定期、国债、受托理财、基金、黄金等做组合投资,不同产品的投资起点不一,对应的风险级别也不相同。建议您可以到我行网点咨询理财经理的相关建议。
[0.5725947022438049] 手头几万闲钱如何理财最靠谱 对应答案:欢迎关注招行理财,招行有储蓄、大额存单、基金、理财产品、外汇、黄金、白银等投资可供您选择。风险和收益基本成正比,要求保本就选择储蓄,追求低风险可以考虑货币基金和低风险的理财产品,追求高收益可以了解投资型基金、外汇,黄金及白银,若您当地有招行,可以联系网点客户经理交流理财事宜。
你的问题是?
> 我要如何借钱
2023-02-26 15:08:40,206 INFO: 1 batches, avg len: 6.0
[得分] 参考问题 对应答案
[0.8377593159675598] 我是说要怎样挂失 对应答案:如果是招商银行一卡通或信用卡,都可以致电相应的客服热线,进入人工挂失。也可以通过网上银行挂失。
[0.8101509213447571] 我可以借钱吗 对应答案:建议您通过正规平台咨询办理。若在招行申请个人贷款,目前规定贷款人的年龄需年满18周岁,且年龄+贷款年限不得超过70岁。未成年人如需申请贷款,可尝试由父母(或一方)作为共同贷款申请人;具体能否办理,建议您联系当地网点的个贷部门详询。
[0.8072128295898438] 我要还款怎么搞 对应答案:若是招行信用卡,我行信用卡还款有多种方式,如通过自助存款机存现、网点柜面还款,网络还款、便利店还款等,您可以登录以下网址查看我行的还款方式介绍,以选择适合您的方式(网址:http://cc.cm####na.com/Cu######ce/Re#####nt.aspx)。
[0.7984545230865479] 我想贷你能? 对应答案:所在城市若有招商银行,可通过招行尝试申请贷款,由于各贷款项目所需条件及申请材料有所不同,请您在8:30-18:00致电9####选择3个人客户服务-3-3-8进入人工服务提供贷款用途及城市详细了解所需资料。贷款申请是否通过,请以经办行个贷部门的综合审核结果为准。
[0.7939909100532532] 我要贷款谁能帮我 对应答案:若您所在城市有招行,可通过招行尝试申请贷款,请您在8:30-18:00致电9####选择“2人工服务-“1”个人银行业务-“4”个人贷款业务进入人工服务提供贷款用途及城市详细了解所需资料。
你的问题是?
>
可以看到,我们没有进行任何训练,就可以得到一个效果还行的模型,我们可以利用分数排名来计算mean receiprocal rank。
然后基于此,去实现一个比基准模型更好的模型。
下面,我们来看如何实现BERT基准模型。
BERT基准模型
与ELMo模型类似,我们可以用BERT来对句子进行编码。BERT句向量表示有多种方式,比如使用[CLS]的向量表示句向量,但在这里效果不好,推荐和ELMo一样,才有句子中单词的平均值。
数据集
下载地址: https://pan.baidu.com/s/18Lwq16VBo6wBD_qLb3i33g
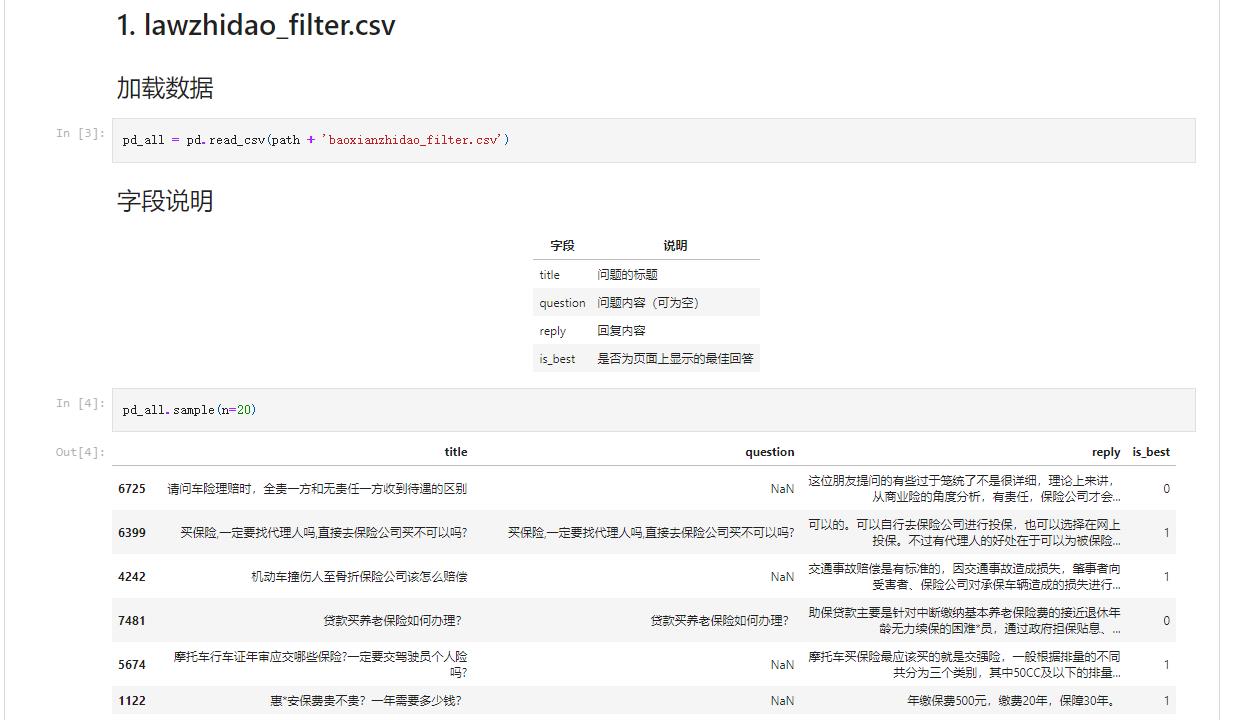
这次我们使用法律知道数据集,如上图所示。
实现
同样也是使用哈工大提供的预训练模型: https://github.com/ymcui/Chinese-BERT-wwm 。
我们利用HuggingFace包,这里可以不用费劲地去寻找该模型的下载地址,而可以直接通过huggingface下载。
下面会看到怎么做。
首先加载相应的包:
import logging
import os
import pickle
import pandas as pd
import torch
from sklearn.metrics.pairwise import cosine_similarity
from torch.utils.data import DataLoader, SequentialSampler, TensorDataset
from tqdm import tqdm
from transformers import (
BertConfig,
BertModel,
BertTokenizer,
)
from transformers import glue_convert_examples_to_features
from transformers.data.processors.utils import InputExample, DataProcessor
然后定义需要用到的参数:
# 参数
# 从HuggingFace官网下载
model_path = "hfl/chinese-bert-wwm-ext"
max_seq_length = 128
learning_rate = 2e-5
batch_size = 32
data_dir = "lawzhidao_filter.csv"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
定义数据处理类:
class FAQProcessor(DataProcessor):
"""处理我们的数据"""
def get_example_from_tensor_dict(self, tensor_dict):
"""
构建输入样本,我们这里针对BERT的输入只是单个句子,所以只有text_a参数
:param tensor_dict:
:return:
"""
return InputExample(
tensor_dict["idx"].numpy(), # 样本ID
tensor_dict["sentence"].numpy().decode("utf-8"), # text_a
None, # text_b
str(tensor_dict["label"].numpy()) # 标签
)
def get_candidates(self, file_dir):
train_df = pd.read_csv(file_dir)
# 只需要最佳答案中的title和reply
candidates = train_df[train_df["is_best"] == 1][["title", "reply"]]
# 转换为列表
self.candidate_title = candidates["title"].tolist()
# 保存在属性candidate_reply中
self.candidate_reply = candidates["reply"].tolist()
return self._create_examples(self.candidate_title, "train")
def _create_examples(self, lines, set_type):
"""创建训练样本"""
examples = []
for i, line in enumerate(lines):
guid = f"set_type-i"
examples.append(InputExample(guid=guid, text_a=line, text_b=None, label=1))
return examples
将数据转换为BERT能理解的格式:
def convert_examples_to_dataset(examples, tokenizer):
# 将数据转换为特征
features = glue_convert_examples_to_features(
examples,
tokenizer,
max_length=max_seq_length,
label_list=[1],
output_mode="classification"
)
# 转换为tensor
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
dataset = TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids)
return dataset
定理模型推理函数:
def infer(model, dataset):
"""
让model在数据dataset上进行推理
:param model:
:param dataset:
:return:
"""
sentence_outputs = []
sampler = SequentialSampler(dataset)
dataloader = DataLoader(dataset, sampler=sampler, batch_size=batch_size)
logger.info(f" Num examples = len(dataset), Batch size = batch_size")
for batch in tqdm(dataloader, desc="Inferring"):
model.eval()
batch = tuple(t.to(device) for t in batch)
with torch.no_grad():
inputs =
"input_ids": batch[0],
"attention_mask": batch[1],
"token_type_ids": (batch[2])
outputs = model(**inputs)
# 我们计算句子中单词向量的均值
sequence_output, _ = outputs[:2]
sequence_output = sequence_output.mean(axis=1)
sentence_outputs.append(sequence_output)
return sentence_outputs
我们也是直接加载预训练好的模型来使用:
def main():
# 配置日志打印格式
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
config = BertConfig.from_pretrained(model_path)
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertModel.from_pretrained(model_path, config=config)
model.to(device)
if not os.path.exists("embeddings.pkl"):
processor = FAQProcessor()
candidate_title, candidate_reply = processor.candidate_title, processor.candidate_reply
examples = (processor.get_candidates(data_dir))
dataset = convert_examples_to_dataset(examples, tokenizer)
outputs = infer(model, dataset)
candidate_embeddings = torch.cat([o.cpu().data for o in outputs]).numpy()
with open("embeddings.pkl", "wb") as fout:
pickle.dump([candidate_title, candidate_reply, candidate_embeddings], fout)
print("Save candidate_embeddings to embeddings.pkl")
else:
with open("embeddings.pkl", "rb") as fin:
candidate_title, candidate_reply, candidate_embeddings = pickle.load(fin)
print("Embeddings loaded.")
while True:
title = input("你的问题是?\\n >")
if len(title.strip()) == 0:
continue
# 单个InputExample
examples = [InputExample(guid=0, text_a=title