mnist example for lstm in caffe
Posted 机器学习的小学生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mnist example for lstm in caffe相关的知识,希望对你有一定的参考价值。
下面给出在caffe中使用lstm的一个例子,其中数据集采用mnist。
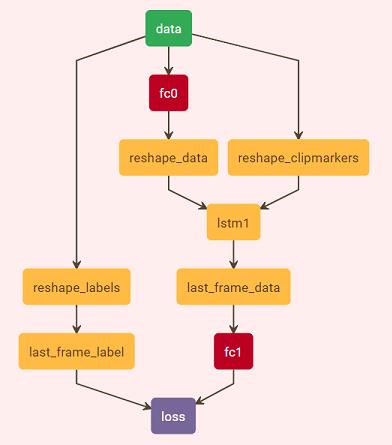
- 为了实现mnist数据的序列话,将mnist的每一行看成一帧,每一列则就是该帧的特征矢量。
- 在使用lstm时,一定要注意clip_markers,每个序列以0开始,后面接1保持为当前序列。
- 损失的计算有两种方式,每个序列的最后一帧参加到损失的计算,或者每个序列中所有帧都参加损失的计算。注意下面代码中最后全连接fc1和损失层中的axis参数,采用第二种方式时,需要将这两个层的axis设置为2。
为了方便测试,这里分享代码和数据:
链接:https://pan.baidu.com/s/1grTdZhP4pqZmDzs7-WB31w
提取码:rxyn
训练代码为:
train_mnist_classification.py
#coding=gbk
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as sio # loadmat
from scipy.misc.pilutil import *
import h5py
from os.path import join, realpath, dirname
from caffe import layers as L, params as P
import sys, os
from caffe._caffe import Solver
import scipy.io as io
import time
import caffe
from caffe.proto import caffe_pb2
# enum Engine DEFAULT = 0; CAFFE = 1; CUDNN = 2;
# enum NormRegion ACROSS_CHANNELS = 0; WITHIN_CHANNEL = 1;
# mnist 10class
def make_lstm(trainSource,batchSize,nframe,cross_id,nclass,type1):
n = caffe.NetSpec()
n.data, n.labels, n.clip_markers = L.Python(name='data',ntop=3,
python_param=dict(module='python_read_data_for_mnist',layer='AllDataLayer',
param_str='\\'phase\\': \\'train\\', \\'dataset_name\\': \\'mnist\\', \\'data_type\\': \\'image\\',\\'batch_size\\': '+str(batchSize)
+ ',\\'cross_id\\':'+str(cross_id)+''),)
n.fc0 = L.InnerProduct(n.data,name='fc0',num_output=128,
weight_filler=dict(type='xavier',std=0.005),
bias_filler=dict(type='constant',value=0.1),
param=[dict(lr_mult=1,decay_mult=1),dict(lr_mult=2,decay_mult=0)]
)
n.reshape_data = L.Reshape(n.fc0,name='reshape_data',reshape_param='shape':'dim':[nframe,batchSize,128])
n.reshape_labels = L.Reshape(n.labels,name='reshape_labels',reshape_param='shape':'dim':[nframe,batchSize])
n.reshape_clipmarkers = L.Reshape(n.clip_markers,name='reshape_clipmarkers',reshape_param='shape':'dim':[nframe,batchSize])
n.lstm1 = L.LSTM(n.reshape_data,n.reshape_clipmarkers,name='lstm1',recurrent_param='num_output':64,
'weight_filler':'type':'uniform','min':-0.01,'max':0.01,
'bias_filler':'type':'constant','value':0)
# the output of lstm convert to
if type1 == 'using_last_frame_compute_loss':
n.last_frame_data = L.Python(n.lstm1,name='last_frame_data',ntop=1,
python_param=dict(module='data_separate_for_mnist',layer='data_separate'),
propagate_down=[1]) # for main tasks
n.last_frame_label = L.Python(n.reshape_labels,name='last_frame_label',ntop=1,
python_param=dict(module='label_separate_for_mnist',layer='label_separate'),
propagate_down=[0]) # for main tasks
n.fc1 = L.InnerProduct(n.last_frame_data,name='fc1',num_output=nclass,
weight_filler=dict(type='xavier',std=0.005),
bias_filler=dict(type='constant',value=0.1),
param=[dict(lr_mult=1,decay_mult=1),dict(lr_mult=2,decay_mult=0)])
n.loss = L.SoftmaxWithLoss(n.fc1,n.last_frame_label,
name='loss',ntop=1)
elif type1 == 'using_all_frame_compute_loss':
n.fc1 = L.InnerProduct(n.lstm1,name='fc1',num_output=nclass,
weight_filler=dict(type='xavier',std=0.005),
bias_filler=dict(type='constant',value=0.1),
param=[dict(lr_mult=1,decay_mult=1),dict(lr_mult=2,decay_mult=0)],
axis=2)
n.loss = L.SoftmaxWithLoss(n.fc1,n.reshape_labels,
name='loss',ntop=1,
softmax_param='axis':2)
return n.to_proto()
def make_solver(train_net,snapshot,snapshot_prefix):
maxIter = 20000
s = caffe_pb2.SolverParameter()
s.random_seed = 0xCAFFE
#s.type = 'Adam'
s.type = 'SGD'
s.display = 20
s.iter_size = 1
s.base_lr = 0.01 # 0.0005 for customs, 0.0001 for mean3
s.lr_policy = "step"
s.gamma = 0.1
s.momentum = 0.9
s.stepsize = 5000
s.max_iter = maxIter
s.weight_decay = 0.0005
s.snapshot = snapshot
s.snapshot_prefix = snapshot_prefix
s.train_net = train_net
return s
ncross = 1 # 仅进行一次实验。
for nc in range(ncross):
print('cross_id: ',str(nc+1))
##########################
nclass = 10 # for caspeal: 21 ,for pointing04: 93 , cmupie: 13
zoo_path = 'ZOO_lstm/'
snap_path = 'snapshots_lstm_for_mnist_all/'
pretrained_weight = None
debug_suf = ''
trainSource = None
snapshot = 1000000 # not use
niter = 10000 #5000
snap_interval = 2000
isShow = True
batchSize = 256
nframe = 28 # imgSize[0]
type1 = 'using_last_frame_compute_loss' # using_last_frame_compute_loss, using_all_frame_compute_loss
##########################
nstep = 0
if not os.path.exists(snap_path):
os.mkdir(snap_path)
file_path = snap_path+'/cross'+str(nc+1)
if not os.path.exists(file_path):
os.mkdir(file_path)
with open(zoo_path + 'train.prototxt', 'w') as f:
f.write(str(make_lstm(trainSource,batchSize,nframe,nc,nclass,type1))) # 这里的 nc不需要加1
caffe.set_device(0)
caffe.set_mode_gpu()
#caffe.set_mode_cpu()
train_net = zoo_path + 'train.prototxt'
snapshot_prefix = snap_path + 'cross' + str(nc+1) + debug_suf + '/vgg_'
print(snapshot_prefix)
print(train_net)
solver_pro = zoo_path + 'solver.prototxt'
with open(solver_pro, 'w') as f:
f.write(str(make_solver(train_net,snapshot,snapshot_prefix)))
print(solver_pro)
mysolver = caffe.get_solver(solver_pro)
loss1 = np.zeros(niter)
disp_interval = 1
isPrint = True
if isShow:
plt.ion()
#plt.axis([0,niter,0,1])
#fig = plt.figure()
#pass
for it in range(niter):
mysolver.step(1)
loss1[it] = mysolver.net.blobs['loss'].data.copy()
if it % disp_interval == 0 or it+1 == niter :
print('it:',it,' loss1:', loss1[it])
if isShow and it>=1:
plt.plot([it-1,it],[loss1[it-1],loss1[it]],'r-')
plt.show()
plt.pause(0.00001)
if (it+1) % snap_interval == 0:
plt.savefig(snap_path+str(it+1)+'.pdf')
mysolver.net.save(snapshot_prefix + 'iter_' + str(it+1) + '.caffemodel')
预测代码为:
#coding=gbk
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as sio # loadmat
from scipy.misc.pilutil import *
import h5py
from os.path import join, realpath, dirname
from caffe import layers as L, params as P
import sys, os
from caffe._caffe import Solver
import scipy.io as io
import time
import caffe
from caffe.proto import caffe_pb2
import mnist_version2_for_caffe_lstm as mnist
from numpy import *
# enum Engine DEFAULT = 0; CAFFE = 1; CUDNN = 2;
# enum NormRegion ACROSS_CHANNELS = 0; WITHIN_CHANNEL = 1;
# mnist 10class
def make_lstm_deploy(batchSize,nframe,feat_len,nclass,type1):
n = caffe.NetSpec()
n.data = L.Input(name='data',ntop=1,input_param=dict(shape=dict(dim=[batchSize*nframe,feat_len])))
n.labels = L.Input(name='labels',ntop=1,input_param=dict(shape=dict(dim=[batchSize*nframe,1])))
n.clip_markers = L.Input(name='clip_markers',ntop=1,input_param=dict(shape=dict(dim=[batchSize*nframe,1])))
n.fc0 = L.InnerProduct(n.data,name='fc0',num_output=128,
weight_filler=dict(type='xavier',std=0.005),
bias_filler=dict(type='constant',value=0.1),
param=[dict(lr_mult=1,decay_mult=1),dict(lr_mult=2,decay_mult=0)]
)
n.reshape_data = L.Reshape(n.fc0,name='reshape_data',reshape_param='shape':'dim':[nframe,batchSize,128])
n.reshape_labels = L.Reshape(n.labels,name='reshape_labels',reshape_param='shape':'dim':[nframe,batchSize])
n.reshape_clipmarkers = L.Reshape(n.clip_markers,name='reshape_clipmarkers',reshape_param='shape':'dim':[nframe,batchSize])
n.lstm1 = L.LSTM(n.reshape_data,n.reshape_clipmarkers,name='lstm1',recurrent_param='num_output':64,
'weight_filler':'type':'uniform','min':-0.01,'max':0.01,
'bias_filler':'type':'constant','value':0)
# the output of lstm convert to
if type1 == 'using_last_frame_compute_loss':
n.last_frame_data = L.Python(n.lstm1,name='last_frame_data',ntop=1,
python_param=dict(module='data_separate_for_mnist',layer='data_separate'),
propagate_down=[1]) # for main tasks
n.last_frame_label = L.Python(n.reshape_labels,name='last_frame_label',ntop=1,
python_param=dict(module='label_separate_for_mnist',layer='label_separate'),
propagate_down=[0]) # for main tasks
n.fc1 = L.InnerProduct(n.last_frame_data,name='fc1',num_output=nclass,
weight_filler=dict(type='xavier',std=0.005),
bias_filler=dict(type='constant',value=0.1),
param=[dict(lr_mult=1,decay_mult=1),dict(lr_mult=2,decay_mult=0)])
n.prob = L.Softmax(n.fc1,name='prob',)
#n.loss = L.SoftmaxWithLoss(n.fc1,n.last_frame_label,
# name='loss',ntop=1)
elif type1 == 'using_all_frame_compute_loss':
n.fc1 = L.InnerProduct(n.lstm1,name='fc1',num_output=nclass,
weight_filler=dict(type='xavier',std=0.005),
bias_filler=dict(type='constant',value=0.1),
param=[dict(lr_mult=1,decay_mult=1),dict(lr_mult=2,decay_mult=0)],
axis=2)
n.prob = L.Softmax(n.fc1,name='prob',softmax_param='axis':2)
#n.loss = L.SoftmaxWithLoss(n.fc1,n.reshape_labels,
# name='loss',ntop=1,softmax_param='axis':2)
return n.to_proto()
###########################################################
nclass = 10 # mnist
zoo_path = 'ZOO_lstm/'
model_root = 'snapshots_lstm_for_mnist/'
pretrained_weight = None
trainSource = None
snapshot = 1000000 # not use
niter = 10000 #5000
snap_interval = 2000
isShow = True
batchSize = 100
nframe = 28 # imgSize[0]
feat_len = 28 # imgSize[1]
type1 = 'using_last_frame_compute_loss' # using_last_frame_compute_loss, using_all_frame_compute_loss
#以上是关于mnist example for lstm in caffe的主要内容,如果未能解决你的问题,请参考以下文章