史诗级的突破,如何让GPT接口调用能绕过4000 tokens 的长度限制
Posted dotNET跨平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了史诗级的突破,如何让GPT接口调用能绕过4000 tokens 的长度限制相关的知识,希望对你有一定的参考价值。
最近很高兴有机会较为全面深入地研究GPT / ChatGPT这一热门技术,学到了不少东西,当然也遇到不少问题,其中一个问题就是,所有的GPT模型,都会有输入输出长度(加起来)的限制这个问题,就好像一个紧箍咒似的。
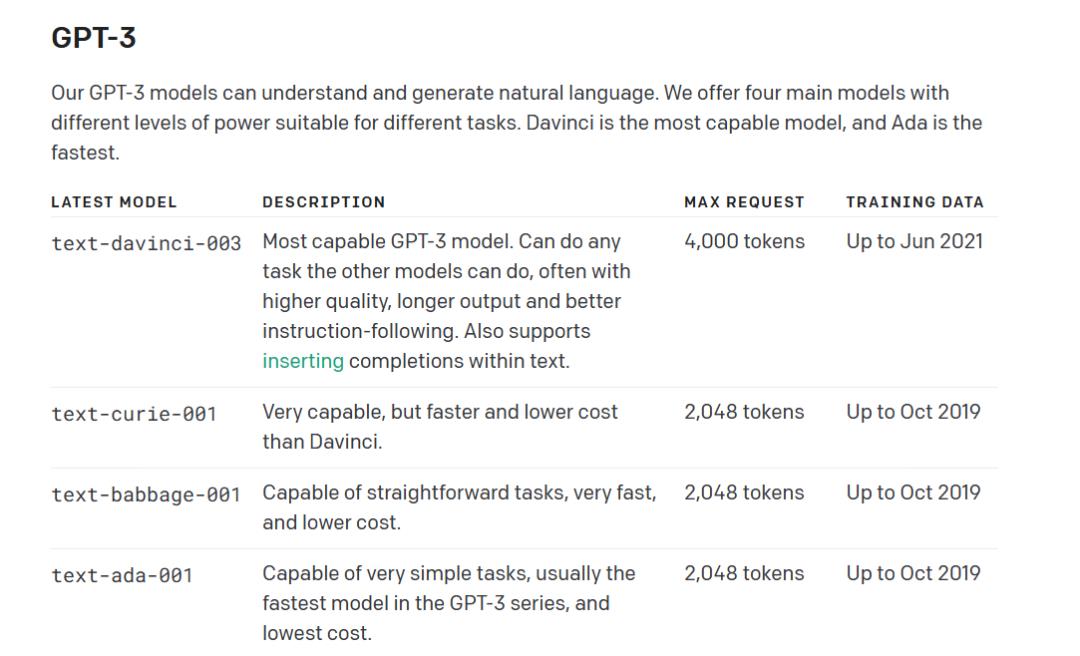
我这段时间看到很多不同的一些办法来想办法绕过这个限制,例如把一个长的prompt拆成多个短的,逐个执行后再拼接起来。虽然有的确实能实现效果,但就是很麻烦。
难道没有更好的办法了么?我倒是实验了如下的这方法,而且确实是可行的。

你可能会说,我的内容不是一个网页啊,我是本地的一些文字呢?其实,这又有什么难的呢?你要做的无非是把你的文字,转换为一个网页即可。例如本例我演示一下,我把刚才那个openai的帮助文档保存在本地,形成一个html文件。
这个文件其实是可以直接通过浏览器打开的。

那么问题来了,这个文件是肯定不可能被openai 在云端读取到的?怎么办呢?还是很容易,我可以本地把这个文件打开来,并且用反向代理将其发布到公网允许匿名访问。首先,我用了一个静态服务器来把这个网页托管起来。

然后用ngrok来做反向代理

运行起来后的效果如下

那么接下来你要做的就是,把这个地址给GPT去解析即可。

打完,收工!
请注意,真实场景下,你完全可以动态地生成很多本地的html文件,然后通过这个办法就解决了长度限制的问题了。
以上是关于史诗级的突破,如何让GPT接口调用能绕过4000 tokens 的长度限制的主要内容,如果未能解决你的问题,请参考以下文章