阿里巴巴集群所有的数据同步任务都是用SQL语句来定义,如何实现?
Posted 中间件兴趣圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里巴巴集群所有的数据同步任务都是用SQL语句来定义,如何实现?相关的知识,希望对你有一定的参考价值。
众所周知,阿里巴巴开源了Canal,支持通过订阅mysql Binlog从而实现将MySQL增量同步到诸如MQ、ElasticSearch的能力,但对Oracle却无能为力,那如何实现Oracle数据的增量同步呢?
本文将关注CDC领域又一后起之秀:Flink-CDC,用SQL语句定义同步任务,并且支持Oracle增量同步,本篇将一步一步如何使用flink-cdc实现Oracle增量同步,本系列的后续文章会重点剖析其实现原理。
1、准备Oracle环境
本文假设大家成功安装好了Oracle,并不打算介绍如何安装Oracle,如果您还未安装Oracle数据库,可先百度之。
1.1 开启归档日志
首先想要实现Oracle增量同步,必须开启Oracle的归档日志,查看Oracle是否开启归档日志的方法如下图所示:

如果还未开启归档日志,可以使用如下命令开启Oracle归档日志:
sqlplus /nolog
SQL> conn/as sysdba;
SQL> shutdown immediate;
SQL> startup mount;
SQL> alter database archivelog;
SQL> alter database open;
1.2 开启数据库级别的supplemental log
可以通过如下命令开启数据库级别的supplemental日志。
alter database add supplemental log data (all) columns;
可以通过如下命令查看是否成功开启数据库级别的supplemental:
alter database add supplemental log data (all) columns;
-- 可以通过如下命令查看是否开启
SELECT supplemental_log_data_min min,
supplemental_log_data_pk pk,
supplemental_log_data_ui ui,
supplemental_log_data_fk fk,
supplemental_log_data_all allc from v$database;
显示结果:
MIN PK UI FK ALL
-------- --- --- --- ---
IMPLICIT NO NO NO YES
其中 supplemental_log_data_all 为 yes 表示开启了所有字段的 supplemental机制。
1.3 创建测试用户与表
可以通过如下命令简单创建测试的用户与表结构:
-- 创建用户
create user YOUR_NAME identified by YOUR_PASSWORD;
-- 给用户授权
grant connect,resource,dba to YOUR_NAME;
-- 创建表
create table T_TEST_01
(
ID NUMBER not null,
NAME VARCHAR2(100)
)
/
create unique index T_TEST_01_ID_UINDEX
on T_TEST_01 (ID)
/
alter table T_TEST_01
add constraint T_TEST_01_PK
primary key (ID)
/
1.4 开启表级别的supplemental机制
可以通过如下命令开启表级别的supplemental
ALTER TABLE 用户名.表名 ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
2、Flink-CDC测试代码
首先在java中要使用flink-cdc,需要在pom文件中添加如下依赖:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.13.3</flink.version>
<target.java.version>1.8</target.java.version>
<scala.binary.version>2.11</scala.binary.version>
<maven.compiler.source>$target.java.version</maven.compiler.source>
<maven.compiler.target>$target.java.version</maven.compiler.target>
<log4j.version>2.12.1</log4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_$scala.binary.version</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-oracle-cdc</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>$log4j.version</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>$log4j.version</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>$log4j.version</version>
</dependency>
</dependencies>
与之对应的Java的测试代码如下:
package net.codingw;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class Oracle2ConsoleTest
public static void main(String[] args)
try
StreamExecutionEnvironment blinkStreamEnv = StreamExecutionEnvironment.getExecutionEnvironment();
int parallelism = 1;
blinkStreamEnv.setParallelism(parallelism);
EnvironmentSettings settings =
EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(blinkStreamEnv, settings);
String sourceSql = "CREATE TABLE test (ID INT,NAME STRING) WITH ('connector' = 'oracle-
cdc','hostname' = 'localhost','port' = '1521','username' = 'CDC','password' = '123456','database-
name' = 'helowin','schema-nae' = 'CDC','table-name' = 't_test_01', 'scan.startup.mode' = 'latest-
offset', 'debezium.log.mining.strategy'='online_catalog',
'debezium.log.mining.continuous.mine'='true' )";
String sinkSql = "CREATE TABLE sink_table (ID INT, NAME STRING) WITH ( 'connector' = 'print')";
String insertSql = "INSERT INTO sink_table SELECT ID, NAME FROM test";
tableEnv.executeSql(sourceSql);
tableEnv.executeSql(sinkSql);
tableEnv.executeSql(insertSql);
catch (Throwable e)
e.printStackTrace();
启动后,如果在数据库中添加一条记录,运行效果如下:

更新一条记录,运行效果如下:

删除一条记录,运行效果如下:

3、遇到的坑
在测试Flink-CDC实现Oracle增量同步的过程中,主要碰到两个比较大的坑。
3.1 同步延迟较大
默认的配置同步延迟需要耗费3-5分钟,目前官方提供的解决方法,在创建flink schema时,指定如下两个参数:
- ‘debezium.log.mining.strategy’=‘online_catalog’
- ‘debezium.log.mining.continuous.mine’=‘true’
上述参数设定后,同步延迟能降低到秒级别。
至于背后的原理,将在本系列的后续文章进行详细探讨与分析。
3.2 存在锁表风险
由于测试过程中出现了好几次的锁表,分析查看原因发现在 RelationalSnapshotChangeEventSource 的 doExecute 中会调用 lockTablesForSchemaSnapshot 中会锁表,对应的实现类为OracleSnapshotChangeEventSource:
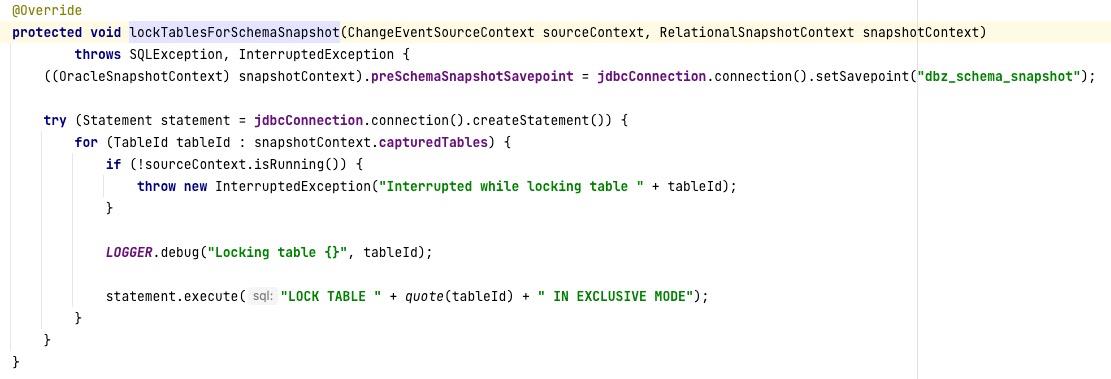
但其释放的地方,感觉有些问题,具体在RelationalSnapshotChangeEventSource 的 doExecute中,部分截图如下所示:

温馨提示:后续会对其机制进行详细解读,后续再来思考是否可以优化,如何优化该段代码,因为锁表在生产环境是一个风险极大的操作。
4、Oracle增量同步背后的理论基础
Oracle CDC 连接器支持捕获并记录 Oracle 数据库服务器中发生的行级变更,其原理是使用 Oracle 提供的 LogMiner 工具或者原生的 XStream API [3] 从 Oracle 中获取变更数据。
LogMiner 是 Oracle 数据库提供的一个分析工具,该工具可以解析 Oracle Redo 日志文件,从而将数据库的数据变更日志解析成变更事件输出。通过 LogMiner 方式时,Oracle 服务器对解析日志文件的进程做了严格的资源限制,所以对规模特别大的表,数据解析会比较慢,优点是 LogMiner 是可以免费使用的。
基本原理如下图所示:
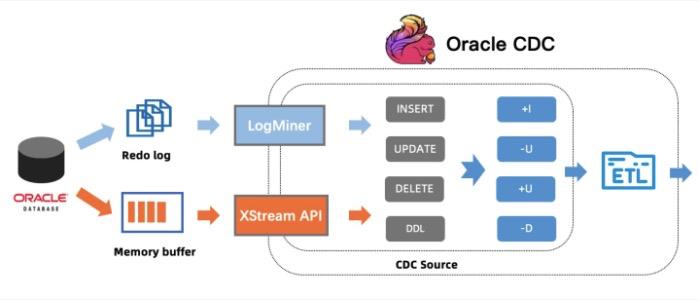
本图来源于:https://nowjava.com/article/44249
本文就介绍到这里了,后续关于Flink Oracle CDC相关的实现原理,将在本系列的后续文章加以详细探讨,敬请期待。
以上是关于阿里巴巴集群所有的数据同步任务都是用SQL语句来定义,如何实现?的主要内容,如果未能解决你的问题,请参考以下文章