从0到1搭建大数据平台之监控
Posted 大数据指北
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从0到1搭建大数据平台之监控相关的知识,希望对你有一定的参考价值。
大家好,我是脚丫先生 (o^^o)
大数据平台设计中,监控系统尤为重要。
它时刻关乎大数据开发人员的幸福感。
试想如果半夜三更,被电话吵醒解决集群故障问题,那是多么的痛苦!!!
但是不加班是不可能的,因此就要避免无效的集群报警对我们造成影响,完善我们的监控预警系统,经过精细化监控指标项、对异常进行自动化处理、告警收敛等一系列操作,相信你也可以睡一个安稳觉。

一、监控系统
小伙伴们都知道,搭建一个大数据平台不是目的,稳定的使用才是核心。
大数据平台的日志和监控可以说是数据开发人员的两只眼睛。
然而大数据平台涉及的组件比较多,因此一个统一的集群和平台监控必不可少。
一般而言,我们主要以:监控粒度、监控指标完整性、监控实时性作为评价监控系统是否优秀的三要素。
我们将监控系统分为三层:
- 系统层
顾名思义,系统层主要监控我们大数据平台所依赖的服务器。
通过对服务器的监控,可以实时的掌握服务器的工作状态、内存消耗、健康状态等,以保证服务器的稳定运行。

监控指标: 内存、磁盘、CPU、网络流量、系统进程等系统级别指标。
- 应用层
应用层的监控可以理解为,对部署在服务器上的各种应用进行监控。包括但是不限于Hadoop集群、调度服务和大数据平台应用等等。
比如说,Hadoop集群的某个节点出现了故障,我们能够快速定位,并处理该问题。
对应用的整体运行状况进行了解、把控,确保服务的状态正常,服务的运行性能正常。
监控指标: JVM堆内存、GC、CPU使用率、线程数、吞吐量等。
- 业务层
业务层算是最贴近系统用户的,同时可以反馈系统及应用层的问题。
业务系统本质目的是为了达成业务目标,因此监控业务系统是否正常最有效的方式是从数据上监控业务目标是否达成。
对业务数据进行监控,可以快速发现程序的bug或业务逻辑设计缺陷。
比如说,我们会监控调度服务的执行情况、Datax数据集成的抽取情况等等。

二、常用大数据平台开源监控组件
常用的开源监控组件比较多,这里以比较常用的三种。
- Zabbix
基于Web界面提供分布式系统监视及网络监视功能的企业级开源解决方案。
它易于入门,能实现基础的监控,但是深层次需求需要非常熟悉Zabbix并进行大量的二次定制开发,难度较大;此外,系统级别报警设置相对比较多,如果不筛选的话报警邮件会很多;并且自定义的项目报警需要自己设置,过程比较繁琐。
- OpenFalcon
小米开源的面向互联网企业的监控产品。它是一款企业级、高可用、可扩展的开源监控解决方案,提供实时报警、数据监控等功能。可以非常容易的监控整个服务器的状态,比如磁盘空间,端口存活,网络流量等。
- Prometheus
它是一套开源的监控、报警和时间序列数据库组合。也是最近比较流行的开源监控工具~深受广大小伙伴的喜欢。作为新一代的云原生监控系统,其最大的优点在于:
| 易管理性 | Prometheus核心部分只有一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储 |
|---|---|
| 高效性 | 单一Prometheus可以处理数以百万的监控指标;每秒处理数十万的数据点 |
| 易于伸缩性 | 可以对Prometheus进行扩展,形成一个逻辑集群 |
| 丰富的看板 | 多种可视化图表及仪表盘支持 |
| 针对容器监控 | 对docker,k8S监控有成熟解决方案 |

总而言之, 以上三种是现在较为流行的监控工具,在这里我进一步对他们进行方案对比:
| Zabbix | OpenFalcon | Prometheus | |
|---|---|---|---|
| 可扩展性 | 可扩展能力强 | 可扩展能力强 | 可扩展能力强 |
| 监控数据采集 | 推送、拉取 | 推送、拉取 | 推送、拉取 |
| 监控数据存储 | mysql/psql | 归档RRD,存储mysql+redis+opentsdb | 自带时序数据库存储方案, 类似于OpenTSDB |
| 自定义指标 | c++/python | go/python/shell | go/python/shell |
| 告警功能 | 支持 | 支持 | 支持 |
| 使用场景 | 大中型企业、私有云 | 大中型企业、私有云 | 大中型企业、私有云 |
三、大数据平台监控体系构建
3.1 概况
研发的大数据平台,修改了前端登陆界面,对于一个大数据开发人来说,前端的学习真的非常痛苦,感觉好难。
不过也是逐渐上手了。
其监控体系是基于基于开源:xxx_exporter+promethues+grafana的构建监控系统,方案如下:
其中
- exporter
一般是使用来采集各种组件运行时的指标数据。
- promethues
构建指标时序数据库。
- grafana
构建指标显示面板。
目前已有各种docker容器方便的构建各种监控体系
3.2 构建过程
详细的xxx_exporter+promethues+grafana搭建过程,直接参考百度,较为详细。
(1)采用docker的方式快速搭建监控基础。
version: '3.7'
services:
node-exporter:
image: prom/node-exporter:latest
restart: always
network_mode: "host"
ports:
- "9100:9100"
dingtalk:
image: timonwong/prometheus-webhook-dingtalk:latest
restart: always
network_mode: "host"
volumes:
- ./alertmanager/config.yml:/etc/prometheus-webhook-dingtalk/config.yml
ports:
- "8060:8060"
alertmanager:
depends_on:
- dingtalk
image: prom/alertmanager:latest
restart: always
network_mode: "host"
volumes:
- ./alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml
ports:
- "9093:9093"
- "9094:9094"
prometheus:
depends_on:
- alertmanager
image: prom/prometheus:latest
restart: always
network_mode: "host"
user: root
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- ./prometheus/alert-rules.yml:/etc/prometheus/alert-rules.yml
- ./prometheus/configs:/etc/prometheus/configs
ports:
- "9090:9090"
grafana:
depends_on:
- prometheus
image: grafana/grafana:latest
restart: always
network_mode: "host"
volumes:
- ./grafana:/var/lib/grafana
- ./grafana.ini:/etc/grafana/grafana.ini
- ./index.html:/usr/share/grafana/public/views/index.html
ports:
- "3000:3000"
(2) promethues的配置
#全局配置信息:
global:
scrape_interval: 15s #默认抓取间隔1m, 15秒向目标抓取一次数据
evaluation_interval: 15s
#个性化的抓取配置信息
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
#监控物理主机:cpu、memory、disk等
- job_name: node_exporter
static_configs:
- targets:
- 'localhost:9091'
- job_name: 'bigdata-namenode' #用于监控namenode组件
file_sd_configs:
- files:
- configs/namenode.json #hdfs参数获取地址
- job_name: 'bigdata-datanode' #用于监控datanode
file_sd_configs:
- files:
- configs/datanode.json
- job_name: 'bigdata-resourcemanager' #用于监控resourcemanager
file_sd_configs:
- files:
- configs/resourcemanager.json
- job_name: 'bigdata-nodemanager' #用于监控nodemanager
file_sd_configs:
- files:
- configs/nodemanager.json
针对于大数据组件繁多,因此对于监控json的配置也需要一一对应。
暂时以以上几个组件监控为例。
(3)构建之后的效果
以grafana指标展示界面,嵌入大数据平台里作为监控系统。
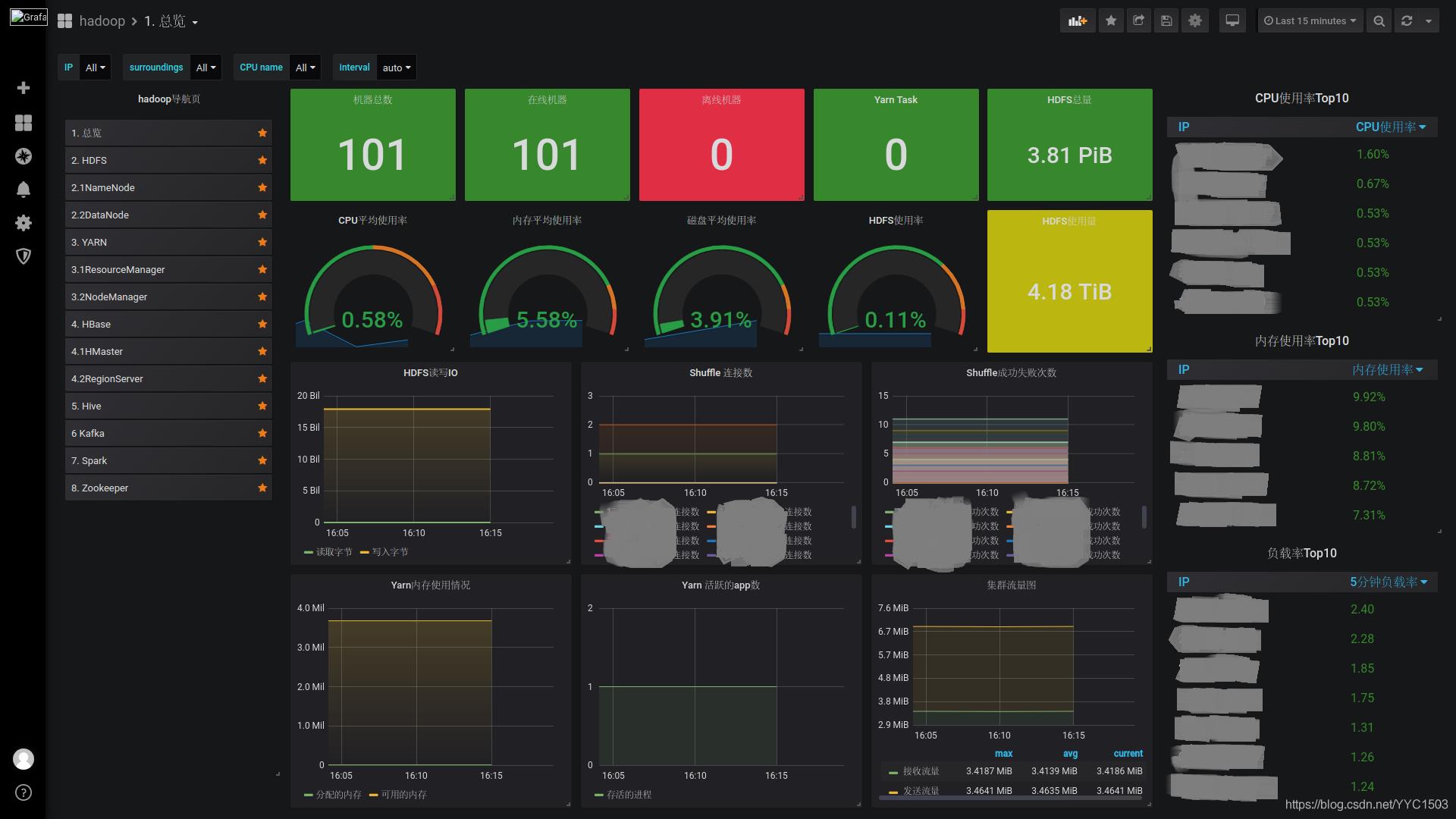
效果图主要是在grafana里对每个组件进行编辑,小伙伴们可以自行设计想要的效果。
更多精彩内容请关注 微信公众号 👇「大数据指北」🔥:
一枚热衷于分享大数据基础原理,技术实战,架构设计与原型实现之外,还喜欢输出一些个人私活案例。
更多精彩福利干货,期待您的关注 ~
以上是关于从0到1搭建大数据平台之监控的主要内容,如果未能解决你的问题,请参考以下文章