深度学习在视频多目标跟踪中的应用综述
Posted AI浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习在视频多目标跟踪中的应用综述相关的知识,希望对你有一定的参考价值。
文章目录
- 摘要
- 1、简介
- 2、MOT:算法、指标和数据集
- 3、MOT中的深度学习
- 4、分析与比较
- 5、结论与未来发展方向
摘要
论文链接:https://arxiv.org/pdf/1907.12740.pdf
多目标跟踪(MOT)的问题包括在一个序列中跟踪不同物体的轨迹,通常是一个视频。近年来,随着深度学习的兴起,为这个问题提供解决方案的算法受益于深度模型的表示能力。本文对利用深度学习模型解决单摄像机视频的MOT任务的工作进行了全面的调查。确定了MOT算法的四个主要步骤,并深入回顾了深度学习如何在每个阶段中使用。还提供了对三个MOTChallenge数据集上所述工作的完整实验比较,确定了一些顶级性能方法之间的相似性,并提出了一些可能的未来研究方向。
关键词 多目标跟踪·深度学习·视频跟踪·计算机视觉·卷积神经网络·LSTM·强化学习
1、简介
多目标跟踪(MOT),也称为多目标跟踪(MTT),是一种计算机视觉任务,旨在分析视频,以识别和跟踪属于一个或多个类别的对象,如行人、汽车、动物和无生命物体,而不需要任何关于目标外观和数量的先验知识。与对象检测算法不同的是,对象检测算法的输出是由坐标、高度和宽度标识的矩形包围框的集合,MOT算法还将目标ID关联到每个框(称为检测),以区分类内对象。MOT算法输出的示例如图1所示。MOT任务在计算机视觉中扮演着重要的角色:从视频监控到自动驾驶汽车,从动作识别到人群行为分析,许多这些问题都将受益于高质量的跟踪算法。

在单目标跟踪(SOT)中,目标的外观是先验已知的,而在MOT中,需要一个检测步骤来识别目标,这些目标可以离开或进入场景。同时跟踪多个目标的主要困难来自于物体之间的各种遮挡和相互作用,这些物体有时也具有相似的外观。因此,简单地应用SOT模型直接求解MOT会导致较差的结果,通常会导致目标漂移和大量ID切换错误,因为此类模型通常难以区分外观相似的类内对象。近年来开发了一系列专门针对多目标跟踪的算法来解决这些问题,以及一些基准数据集和竞赛,以简化不同方法之间的比较。
最近,越来越多这样的算法开始利用深度学习(DL)的表征能力。深度神经网络(DNN)的优势在于它们能够学习丰富的表示形式,并从输入中提取复杂和抽象的特征。卷积神经网络(CNN)目前是空间模式提取的最先进技术,用于图像分类[1,2,3]或物体检测[4,5,6]等任务,而长短期记忆(LSTM)等循环神经网络(RNN)用于处理顺序数据,如音频信号、时间序列和文本[7,8,9,10]。由于DL方法已经能够在许多这些任务中达到最佳性能,我们现在逐渐看到它们被用于大多数性能最佳的MOT算法中,帮助解决问题划分的一些子任务。
这项工作介绍了利用深度学习模型的功能来执行多对象跟踪的算法的调查,重点是用于MOT算法的各个组件的不同方法,并将它们放在每个提议的方法的上下文中。虽然MOT任务可以应用于2D和3D数据,也可以应用于单摄像头和多摄像头场景,但在本次调查中,我们主要关注从单摄像头记录的视频中提取的2D数据。
关于MOT的一些综述和调查已经发表。它们的主要贡献和局限性如下:
-
Luo等人[11]提出了第一个专门关注MOT的综合综述,特别是行人跟踪。他们提供了MOT问题的统一公式,并描述了在MOT系统的关键步骤中使用的主要技术。他们将深度学习作为未来的研究方向之一,因为当时只有极少数算法采用了深度学习。
-
Camplani等人[12]提出了一项关于多重行人跟踪的调查,但他们关注的是RGB- d数据,而我们的重点是2D RGB图像,没有额外的输入。此外,他们的综述没有涵盖基于深度学习的算法。
-
Emami等人[13]提出了一种将单传感器和多传感器跟踪任务作为多维分配问题(MDAP)的公式。他们还提出了一些在跟踪问题中使用深度学习的方法,但这不是他们论文的重点,他们也没有提供这些方法之间的任何实验比较。
-
Leal-Taixé等人。[14]对MOT15[15]和MOT16[16]数据集上的算法获得的结果进行了分析,提供了关于结果的研究趋势线和统计数据的摘要。他们发现,在2015年之后,方法已经从试图为关联问题找到更好的优化算法转变为专注于改进亲和模型,他们预测,更多的方法将通过使用深度学习来解决这一问题。然而,这项工作也没有关注深度学习,也没有涵盖最近几年发表的MOT算法。
在本文中,基于所讨论的局限性,我们的目的是提供一个调查,主要贡献如下:
-
我们提供了关于深度学习在多目标跟踪中的使用的第一次全面调查,重点是从单摄像头视频中提取的2D数据,包括过去调查和评论中没有涵盖的近期作品。DL在MOT中的应用实际上是最近的事情,许多方法在过去三年中已经发表。
-
我们确定了MOT算法中的四个常见步骤,并描述了每个步骤中采用的不同DL模型和方法,包括使用它们的算法上下文。每个被分析的作品所使用的技术也被总结在一个表中,以及可用源代码的链接,作为未来研究的快速参考。
-
我们收集了最常用的MOT数据集的实验结果,以在它们之间进行数值比较,也确定了表现最好的算法的主要趋势。
-
最后,我们讨论了未来可能的研究方向。
综述是按照这种方式进一步组织的。在第2节中,我们首先描述了MOT算法的一般结构和最常用的指标和数据集。第3节在MOT算法的四个确定步骤中探索了各种基于dl的模型和算法。第4节介绍了所提出的算法之间的数值比较,并确定了当前方法的共同趋势和模式,以及一些局限性和未来可能的研究方向。最后,第5节总结前几节的调研结果,并提出一些最后的评论。
2、MOT:算法、指标和数据集
在本节中,对MOT问题进行了一般描述。MOT算法的主要特征和常用步骤在2.1节中进行了识别和描述。通常用于评估模型性能的指标在2.2节中讨论,而最重要的基准数据集在2.3节中给出。
2.1、MOT算法简介
MOT算法中采用的标准方法是检测跟踪:从视频帧中提取一组检测(即识别图像中目标的边界框),并用于指导跟踪过程,通常通过将它们关联在一起,以便为包含相同目标的边界框分配相同的ID。由于这个原因,许多MOT算法将任务表述为分配问题。现代检测框架[4,17,18,5,6]确保了良好的检测质量,大多数MOT方法(如我们将看到的,有一些例外)一直专注于改善关联;事实上,许多MOT数据集提供了一个标准的检测集,可以由算法使用(因此可以跳过检测阶段),以便专门比较它们在关联算法质量上的性能,因为检测器性能会严重影响跟踪结果。
MOT算法也可分为批处理方法和在线方法。批处理跟踪算法允许使用未来信息(即来自未来帧),当试图确定某一帧中的对象身份时。它们经常利用全局信息,从而获得更好的跟踪质量。相反,在线跟踪算法只能使用现在和过去的信息来预测当前帧。这在某些场景下是必需的,比如自动驾驶和机器人导航。与批处理方法相比,在线方法往往表现更差,因为它们不能使用未来的信息修复过去的错误。需要注意的是,虽然实时算法需要以在线方式运行,但并不是每个在线方法都必须实时运行;事实上,除了极少数例外,在线算法在实时环境中仍然太慢,特别是在利用深度学习算法时,这通常是计算密集型的。
尽管文献中提出了各种各样的方法,但绝大多数MOT算法共享以下部分或全部步骤(如图2所示):
-
检测阶段:对象检测算法分析每个输入帧,使用包围框识别属于目标类的对象,在MOT上下文中也称为“检测”;
-
特征提取/运动预测阶段:一个或多个特征提取算法分析检测和/或轨迹,以提取外观、运动和/或交互特征。可选地,运动预测器预测每个跟踪目标的下一个位置;
-
相似匹配阶段:特征和运动预测用于计算检测对和/或轨迹之间的相似度/距离分数;
-
关联阶段:相似度/距离度量用于关联属于同一目标的检测和轨迹,通过为识别同一目标的检测分配相同的ID。
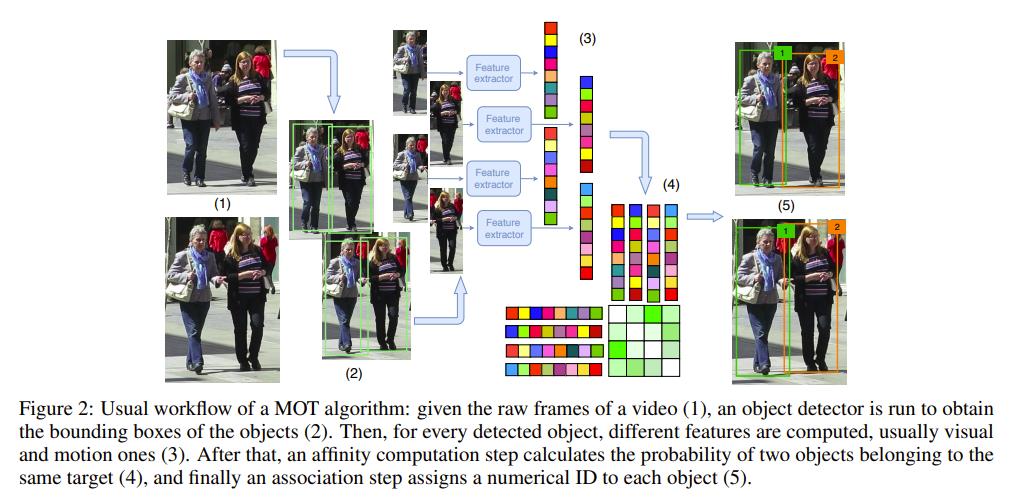
虽然这些阶段可以按照这里给出的顺序依次执行(对于在线方法,通常每帧执行一次,对于批处理方法,整个视频执行一次),但有许多算法将这些步骤中的一些合并在一起,或者将它们交织在一起,甚至使用不同的技术多次执行它们(例如,在两个阶段工作的算法中)。此外,一些方法不直接将检测联系在一起,但使用它们来改进轨迹预测和管理新轨迹的初始化和终止;尽管如此,正如我们将看到的,即使在这种情况下,许多提出的步骤通常仍然可以确定。
2.2、指标
为了提供一个可以公平地测试和比较算法的通用实验设置,一组度量标准实际上已经被建立起来,并且几乎在所有工作中都使用它们。最相关的是Wu和Nevatia定义的指标[19],所谓的CLEAR MOT指标[20],以及最近的ID指标[21]。这些度量集旨在反映测试模型的总体性能,并指出每个模型可能存在的缺陷。因此,这些指标的定义如下:
经典的指标
Wu和Nevatia[19]定义的这些度量指标强调了MOT算法可能犯的不同类型的错误。为了显示这些问题,计算以下值:
-
大部分跟踪(MT)轨迹:在至少80%的帧中被正确跟踪的地面真实轨迹的数量。
-
片段:轨迹假设,最多覆盖80%的真实轨迹。观察到一个真实的轨迹可以被多个碎片覆盖。
-
大部分丢失(ML)轨迹:在不到20%的帧内被正确跟踪的地面真实轨迹的数量。
-
虚假轨迹:与真实物体不对应的预测轨迹(即地面真实轨迹)。
-
ID切换:对象被正确跟踪,但对象的关联ID被错误更改的次数。
完整的MOT指标
CLEAR MOT指标是为2006[22]和2007[23]举行的事件、活动和关系分类(CLEAR)研讨会开发的。这些研讨会由欧洲CHIL项目、美国VACE项目和美国国家标准与技术研究所(NIST)联合组织。这些指标是MOTA(多目标跟踪精度)和MOTP(多目标跟踪精度)。它们是构成它们的其他简单指标的总结。我们将首先解释简单的度量标准,然后在此基础上构建复杂的度量标准。[20]中详细描述了如何将真实对象(ground truth)与跟踪器假设相匹配,因为如何考虑一个假设何时与一个对象相关并不简单,这取决于要评估的精确跟踪任务。在我们的例子中,当我们专注于单摄像机的2D跟踪时,最常用的度量来确定对象和预测是否相关的是包围框的交集除以联合(IoU),因为它是在MOT15数据集[15]的演示论文中建立的度量。具体而言,建立了ground truth与假设之间的映射关系:如果ground truth对象oi与假设hj在框架t−1中匹配,并且在框架t中 I o U ( o i , h j ) ≥ 0.5 IoU(o_i, h_j)≥0.5 IoU(oi,hj)≥0.5,则oi与hj在该框架中匹配,即使存在另一个假设hk,使得 I o U ( o i , h j ) < I o U ( o i , h k ) IoU(o_i, h_j)< IoU(o_i, h_k) IoU(oi,hj)<IoU(oi,hk),考虑连续性约束。在完成前一帧的匹配后,剩余的对象将尝试与剩余的假设匹配,仍然使用0.5的IoU阈值。不能与假设关联的ground truth边界框被视为假阴性(FN),不能与真实边界框关联的假设被标记为假阳性(FP)。另外,在跟踪期间,每次被跟踪的地面真相对象的ID被错误更改,每次被跟踪的地面真相对象的ID被错误更改,都被计算为一次ID切换。然后,计算出的简单指标如下:
- FP:整个视频的误报数;
- FN:整段视频的假阴性数;
- Fragm:碎片总数;
- IDSW: ID交换机总数。
MOTA评分定义如下:
M
O
T
A
=
1
−
(
F
N
+
F
P
+
I
D
S
W
)
G
T
∈
(
−
∞
,
1
]
M O T A=1-\\frac(F N+F P+I D S W)G T \\in(-\\infty, 1]
MOTA=1−GT(FN+FP+IDSW)∈(−∞,1]
GT是地面真值框的个数。需要注意的是,分数可以是负的,因为算法可能会犯比基本真理框数量更大的错误。通常,不报告MOTA,而是报告百分比MOTA,这只是前面的表达式表示为百分比。另一方面,MOTP的计算为:
MOTP
=
∑
t
,
i
d
t
,
i
∑
t
c
t
\\operatornameMOTP=\\frac\\sum_t, i d_t, i\\sum_t c_t
MOTP=∑tct∑t,idt,i
其中 c t c_t ct表示在框架t中匹配的数量, d t , i d_t,i dt,i是假设i与其指定的ground truth对象之间的边界框重叠。需要注意的是,这个指标很少考虑跟踪信息,而是关注检测的质量。
ID 分数
MOTA评分的主要问题是,它考虑了跟踪器做出错误决定的次数,例如切换ID,但在某些情况下(例如机场安全),人们可能更感兴趣的是奖励能够尽可能长时间跟踪对象的跟踪器,以便不丢失其位置。正因为如此,在[21]中定义了两个可选的新指标,这应该是对CLEAR MOT指标所给出的信息的补充。映射不是逐帧匹配地面真相和检测,而是全局执行,分配给给定地面真相轨迹的轨迹假设是最大限度地为地面真相正确分类的帧数。为了解决该问题,构造了一个二部图,取该问题的最小代价解作为问题解。对于二部图,顶点集定义如下:第一个顶点集 V T V_T VT对于每一个真轨迹都有一个所谓的正则节点,对于每一个计算的轨迹都有一个假阳性节点。第二个集合 V C V_C VC,对于每个计算的轨迹都有一个常规节点,对于每个真实的轨迹都有一个假阴性。设置边缘的代价是为了在选择边缘的情况下计算假阴性和假阳性帧的数量(更多信息可以在[21]中找到)。在执行关联之后,根据所涉及节点的性质,有四种不同的可能对。如果 V T V_T VT中的正则节点与 V C V_C VC中的正则节点相匹配(即真实轨迹与计算轨迹相匹配),则计数为真正ID。 V T V_T VT中的每一个假阳性与VC中的一个常规节点匹配,都算作一个假阳性ID。 V T V_T VT中的每一个常规节点匹配 V C V_C VC中的一个假阴性都算一个假阴性ID,最后,每一个假阳性匹配 V C V_C VC中的一个假阴性ID都算一个真阴性ID。然后,计算三个分数。IDTP是选取为真正ID匹配的边的权值之和(它可以看作是在整个视频中正确分配的检测的百分比)。IDFN为所选假阴性ID边权值之和,IDFP为所选假阳性ID边权值之和。利用这三个基本指标,计算出另外三个指标:
- Identification precision: I D P = I D T P I D T P + I D F P I D P=\\fracI D T PI D T P+I D F P IDP=IDTP+IDFPIDTP
- Identification recall: I D R = I D T P I D T P + I D F N I D R=\\fracI D T PI D T P+I D F N IDR=IDTP+IDFNIDTP
- Identification F1: I D F 1 = 2 1 I D P + 1 I D R = 2 I D T P 2 I D T P + I D F P + I D F N IDF1 =\\frac2\\frac1I D P+\\frac1I D R=\\frac2 I D T P2 I D T P+I D F P+I D F N IDF1=IDP1+IDR12=2IDTP+IDFP+IDFN2IDTP
通常,几乎每一项工作中报告的指标都是CLEAR MOT指标,主要是跟踪轨迹(MT),主要是丢失轨迹(ML)和IDF1,因为这些指标是MOTChallenge排行榜中显示的指标(详见2.3节)。此外,跟踪器可以处理的每秒帧数(FPS)经常被报告,也包括在排行榜中。然而,我们发现这个度量很难在不同的算法之间进行比较,因为一些方法包括检测阶段,而另一些方法跳过了这个计算。此外,对所使用的硬件的依赖也与速度有关。
2.3、基准数据集
在过去的几年中,已经发表了大量的MOT数据集。在本节中,我们将介绍最重要的几个,从MOTChallenge基准测试的一般描述开始,然后重点介绍其数据集,最后介绍KITTI和其他不太常用的MOT数据集。
MOTChallenge。MOTChallenge(https://motchallenge.net/)是多对象跟踪最常用的基准测试。除其他外,它提供了目前公开的一些最大的行人跟踪数据集。对于每个数据集,提供了训练分割的基本真理,以及训练和测试分割的检测。MOTChallenge数据集经常提供检测(通常被称为公共检测,而不是算法作者通过使用自己的检测器获得的私有检测)的原因是检测质量对跟踪器的最终性能有很大影响,但算法的检测部分通常独立于跟踪部分,通常使用已经存在的模型;提供每个模型都可以使用的公共检测使得跟踪算法的比较更容易,因为检测质量从性能计算中剔除,跟踪器开始于一个共同的基础。算法在测试数据集上的评估是通过将结果提交给测试服务器来完成的。MOTChallenge网站包含每个数据集的排行榜,在单独的页面上显示使用公共提供的检测模型和使用私人检测的模型。在线方法也是这样标记的。MOTA是MOTA挑战赛的主要评估分数,但还有许多其他指标,包括2.2节中介绍的所有指标。正如我们将看到的,由于绝大多数使用深度学习的MOT算法都专注于行人,因此mott challenge数据集是使用最广泛的,因为它们是目前可用的最全面的数据集,提供了更多的数据来训练深度模型。
MOT15。第一个MOTChallenge数据集是2D MOT 2015(Dataset: https://motchallenge.net/data/2D_MOT_2015/, leaderboard: https://motchallenge.net/results/2D_
MOT_2015/)15。它包含一系列22个视频(11个用于训练,11个用于测试),从旧的数据集中收集,具有各种各样的特征(固定和移动的摄像机,不同的环境和照明条件,等等),因此模型需要更好地概括,以便在其上获得良好的结果。它总共包含11283个不同分辨率的帧,1221个不同的身份和101345个盒子。所提供的检测是使用ACF检测器[24]获得的。
MOT16/17。该数据集的新版本于2016年发布,名为MOT16(Dataset: https://motchallenge.net/data/MOT16/, leaderboard: https://motchallenge.net/results/MOT16/)[16]。这一次,基本真相是从头开始的,因此它在整个数据集是一致的。视频也更有挑战性,因为它们有更高的行人密度。集合中总共包含14个视频(7个用于训练,7个用于测试),其中使用基于变形部分的模型(DPM) v5[25,26]获得的公共检测,与其他模型相比,他们发现在检测数据集上的行人时获得了更好的性能。这次数据集包括11235帧,1342个身份和292733个盒子。MOT17数据集(Dataset: https://motchallenge.net/data/MOT17/, leaderboard: https://motchallenge.net/results/MOT17/)包括与MOT16相同的视频,但具有更准确的地面真相,每个视频有三组检测:一组来自Faster R-CNN[4],一组来自DPM,一组来自Scale-Dependent Pooling detector (SDP)[27]。然后,这些跟踪器必须被证明是多功能的,足够强大,才能在使用不同的检测质量时获得良好的性能。
MOT19。最近,CVPR 2019跟踪挑战赛(https://motchallenge.net/workshops/bmtt2019/tracking.html)发布了一个新版本的数据集,包含8个行人密度极高的视频(4个用于训练,4个用于测试),在最拥挤的视频中,平均每帧行人达245人。数据集包含13410帧,6869个轨道和2259143个盒子,远远超过之前的数据集。虽然该数据集只允许在有限的时间内提交,但该数据将成为2019年底发布MOT19[28]的基础。
KITTI。MOTChallenge数据集侧重于行人跟踪,KITTI跟踪基准(http://www.cvlibs.net/datasets/kitti/eval_tracking.php)[29,30]允许对人和车辆进行跟踪。该数据集是通过在城市周围驾驶汽车收集的,并于2012年发布。它由21个训练视频和29个测试视频组成,共计约19000帧(32分钟)。它包括使用DPM(The website says the detections were obtained using a model based on a latent SVM, or L-SVM. That model is now known as
Deformable Parts Model (DPM))和RegionLets(http://www.xiaoyumu.com/project/detection)[31]探测器获得的探测,以及立体声和激光信息;然而,如前所述,在本次调查中,我们将只关注使用2D图像的模型。CLEAR MOT指标、MT、ML、ID开关和碎片被用来评估这些方法。可以只提交行人的结果,也可以只提交汽车的结果,并且为这两个类别维护了两个不同的排行榜。
其他数据集。除了前面描述的数据集之外,还有一些较老的,现在不太常用的数据集
以上是关于深度学习在视频多目标跟踪中的应用综述的主要内容,如果未能解决你的问题,请参考以下文章