PHP页面爬虫
Posted LiuLiwei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PHP页面爬虫相关的知识,希望对你有一定的参考价值。
爬虫想必大家都很了解,通过脚本对目标文件进行抓取。
我想获取每天菜市场菜价。
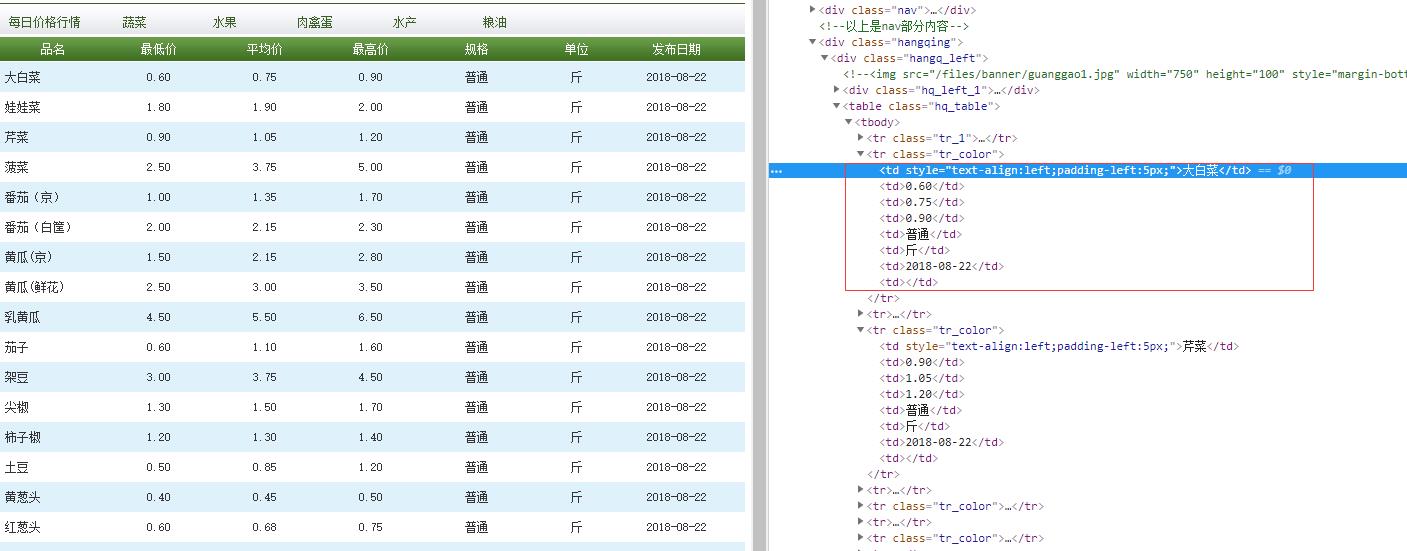
查看控制台,如果有相关信息得接口自然方便不过了,直接请求接口获取数据就可以了。
对于页面信息,需要过滤筛选。
图中信息很规律易于筛选。
首先获取整个页面,可以使用CURL方式请求页面地址,CURL方式也便于需要验证信息的页面传递参数。
过滤页面数据可以使用正则表达式匹配替换。
<?php header( "Content-type:text/html;Charset=utf-8" ); $ch = curl_init(); $url ="http://www.xinfadi.com.cn/marketanalysis/0/list/1.shtml"; curl_setopt ( $ch , CURLOPT_USERAGENT ,"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36" ); curl_setopt($ch,CURLOPT_URL,$url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $content=curl_exec($ch); preg_match_all("/<td style=\\"text-align:left;padding-left:5px;\\">(.*?)<\\/td><td>(.*?)<\\/td><td>(.*?)<\\/td><td>(.*?)<\\/td><td>(.*?)<\\/td><td>(.*?)<\\/td><td>(.*?)<\\/td>/",$content,$matchs,PREG_SET_ORDER); print_r($matchs);
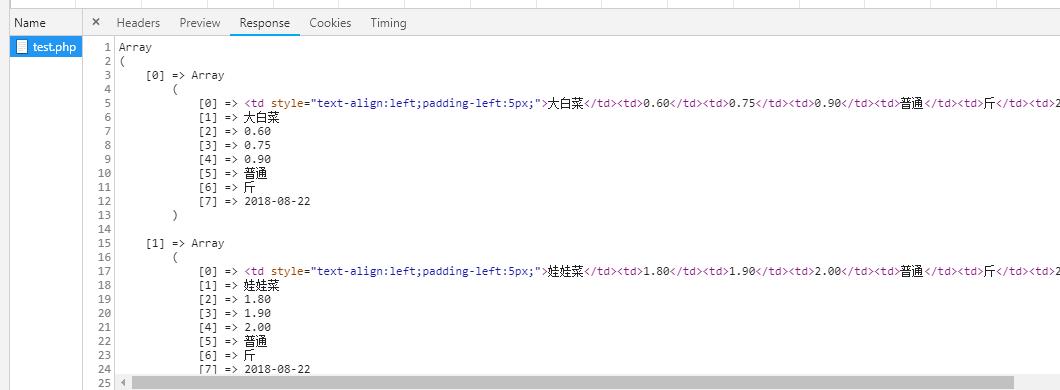
这样就完成了,主要就是使用正则表达式对页面进行过滤筛选,爬取图片也是一样。
接下来将数据存起来就可以了。
DROP TABLE IF EXISTS `tb_commodity_data`; CREATE TABLE `tb_commodity_data` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT \'数据id\', `name` varchar(50) NOT NULL DEFAULT \'\' COMMENT \'商品名\', `summary` varchar(50) NOT NULL DEFAULT \'\' COMMENT \'规格/产地\', `mini_price` decimal(16,4) unsigned NOT NULL DEFAULT \'0.0000\' COMMENT \'最低价\', `avg_price` decimal(16,4) unsigned NOT NULL DEFAULT \'0.0000\' COMMENT \'平均价\', `max_price` decimal(16,4) unsigned NOT NULL DEFAULT \'0.0000\' COMMENT \'最高价\', `unit` varchar(10) NOT NULL DEFAULT \'\' COMMENT \'商品单位\', `category` varchar(45) NOT NULL DEFAULT \'\' COMMENT \'商品分类\', `release_time` datetime NOT NULL DEFAULT \'0000-00-00 00:00:00\' COMMENT \'发布时间\', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\', `source_from` tinyint(1) NOT NULL DEFAULT \'0\' COMMENT \'0:未知来源 1:新发地\', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT=\'商品数据表\';
<?php header("Content-Type: text/html;charset=utf-8"); set_time_limit(1000); $host = \'127.0.0.1\'; $username = \'root\'; $password = \'root\'; $database = \'yii2_shop\'; $connect = mysqli_connect($host,$username,$password,$database); $category = [ \'1\'=>\'蔬菜\', \'2\'=>\'水果\', \'3\'=>\'肉禽蛋\', \'4\'=>\'水产\', \'5\'=>\'粮油\', ]; foreach ($category as $key => $value) { $count=0; $pageSize = 20; header( "Content-type:text/html;Charset=utf-8" ); $ch = curl_init(); $url ="http://www.xinfadi.com.cn/marketanalysis/".$key."/list/1.shtml"; curl_setopt ( $ch , CURLOPT_USERAGENT ,"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36" ); curl_setopt($ch,CURLOPT_URL,$url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $content=curl_exec($ch); preg_match_all("/<em style=\\"color:red;font-weight:bold;\\">(.*?)<\\/em>/",$content,$count,PREG_SET_ORDER);//匹配该表所用的正则 $page = floor($count[0][1]/$pageSize)+1; if($count % $pageSize == 0){ $page = $count/$pageSize; } for ($i=1; $i<= $page; $i++) { // header( "Content-type:text/html;Charset=utf-8" ); $ch = curl_init(); $url ="http://www.xinfadi.com.cn/marketanalysis/".$key."/list/".$i.".shtml"; echo $url.PHP_EOL; curl_setopt ( $ch , CURLOPT_USERAGENT ,"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36" ); curl_setopt($ch,CURLOPT_URL,$url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $content=curl_exec($ch); preg_match_all("/<td style=\\"text-align:left;padding-left:5px;\\">(.*?)<\\/td><td>(.*?)<\\/td><td>(.*?)<\\/td><td>(.*?)<\\/td><td>(.*?)<\\/td><td>(.*?)<\\/td><td>(.*?)<\\/td>/",$content,$pageData,PREG_SET_ORDER);//匹配该表所用的正则 foreach ($pageData as $k => $v) { $sql = "insert into tb_commodity_data(name, summary, mini_price, avg_price, max_price, unit,category,release_time, source_from) values(\'".$v[1]."\',\'".$v[5]."\',\'".$v[2]."\',\'".$v[3]."\',\'".$v[4]."\',\'".$v[6]."\',\'".$value."\',\'".$v[7]."\',\'1\');"; mysqli_query($connect,"set names \'utf8\'");//写库 if(!mysqli_query($connect,$sql)){ $sql = "insert into tb_commodity_data(name, summary, mini_price, avg_price, max_price, unit,category,release_time, source_from) values(\'".$v[1]."\',\'".$v[5]."\',\'".str_replace(",", "", $v[2])."\',\'".str_replace(",", "", $v[3])."\',\'".str_replace(",", "", $v[4])."\',\'".$v[6]."\',\'".$value."\',\'".$v[7]."\',\'1\');"; if(!mysqli_query($connect,$sql)){ echo json_encode($v); } } } sleep(0); } sleep(0); } ?>
以上是关于PHP页面爬虫的主要内容,如果未能解决你的问题,请参考以下文章