python进阶——AI视觉实现口罩检测实时语音报警系统
Posted lqj_本人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python进阶——AI视觉实现口罩检测实时语音报警系统相关的知识,希望对你有一定的参考价值。
大家好,我是csdn的博主:lqj_本人
哔哩哔哩欢迎关注:小淼前端
本篇文章主要讲述python的人工智能视觉模块的口罩检测实时语音检测报警系统,本篇文章已经成功收录到我们python专栏中:https://blog.csdn.net/lbcyllqj/category_12089557.html
https://blog.csdn.net/lbcyllqj/category_12089557.html
 https://blog.csdn.net/lbcyllqj?spm=1000.2115.3001.5343
https://blog.csdn.net/lbcyllqj?spm=1000.2115.3001.5343目录
前言
本程序主要实现了python的opencv人工智能视觉模块的口罩检测实时语音检测报警。
若不知道怎么安装opencv或者使用的请看我的这篇文章(曾上过csdn综合热榜的top1):
python进阶——人工智能视觉识别_lqj_本人的博客-CSDN博客
同时,另一篇基于opencv的人工智能视觉实现的目标实时跟踪功能(增上过csdn综合热榜的top5):
python进阶——人工智能实时目标跟踪_lqj_本人的博客-CSDN博客
项目介绍
PaddlenHub模块
PaddleHub是飞桨预训练模型管理和迁移学习工具,通过PaddleHub开发者可以使用高质量的预训练模型结合Fine-tune API快速完成迁移学习到应用部署的全流程工作。其提供了飞桨生态下的高质量预训练模型,涵盖了图像分类、目标检测、词法分析、语义模型、情感分析、视频分类、图像生成、图像分割、文本审核、关键点检测等主流模型。
使用时可能遇到的bug
AttributeError: partially initialized module ‘cv2‘ has no attribute ‘gapi_wip_gst_GStreamerPipeline‘bug显示:cv2没有指定的依赖。
解决方法
在我们的pycharm中自带的命令窗口中输入:
pip install opencv-python install "opencv-python-headless<4.3"然后,我们再把我们的opencv-python降低版本为与我们安装的opencv-python-headless版本相同即可,我这里用的都是4.2.0.34版本。

方法解释
因为opencv4.3以上的版本会存在与其他模块依赖的兼容性问题,4.3以上的版本兼容性较差,所以,有时会出现一下bug之类的错误。有时,其实我们写的代码没有问题,只是问题出在了依赖的兼容性问题上!
playsound模块
PlaySound是Windows用于播放音乐的API函数(方法)。在vs2010以上版本需要加入#pragma comment(lib, "winmm.lib")才能使用PlaySound。PlaySound函数原型为 BOOL PlaySound(LPCSTR pszSound, HMODULE hmod,DWORD fdwSound)。PlaySound参数,pszSound是指定了要播放声音的字符串,该参数可以是WAVE文件的名字,或是WAV资源的名字,或是内存中声音数据的指针,或是在系统注册表WIN.INI中定义的系统事件声音。如果该参数为NULL则停止正在播放的声音。
项目思路
1.使用PaddlenHub模块指定算法,根据面部特征的上下左右来判断是否面部有物体遮挡,并判断遮挡区域及位置,若判断条件成功,则绘制绿色矩形及英文提示。若判断条件失败,则绘制红色矩形及英文提示!
2.使用playsound模块指定我们录制好的MP3文件,当判断条件符合时,则按照playsound模块原生函数播放MP3文件,达到语音警告提示效果!
代码详解
首先导入相应模块
import paddlehub
import cv2
from playsound import playsound指定paddlehub模块中的算法并赋值
module=paddlehub.Module(name="pyramidbox_lite_mobile_mask")调用本机摄像头
cap=cv2.VideoCapture(0)循环判断指定位置及遮挡区域
while(cap.isOpened()):
frame = cap.read()[1]
input_dict = 'data':[frame]
results = module.face_detection(data=input_dict)
result = results[0]
设置绑定键盘按压事件
k = cv2.waitKey(1) & 0xFF # 判断按键判断肯定条件时绿色字体和矩形
if result['data']!=[]:
label = result['data'][0]['label']
left = result['data'][0]['left']
right = result['data'][0]['right']
top = result['data'][0]['top']
bottom = result['data'][0]['bottom']
color = (0,255,0)
color2 = (0,255,0)判断否定条件时红色字体和矩形,并播放语音警告提示
if label == 'NO MASK':
color = (0,0,255)
color2 = (0,0,255)
playsound('1.mp3')cv2最后的绘制及显示交互窗口
cv2.rectangle(frame,(left,top),(right,bottom),color,3)
cv2.putText(frame,label,(left,top-10),cv2.FONT_HERSHEY_SIMPLEX,0.8,color2,2)
cv2.imshow('xianshi',frame)判断监听键盘按压事件
if k == ord(' '):#退出
break释放摄像头及内存
#释放摄像头
cap.release()
#释放内存
cv2.destroyAllWindows()完整代码及注释
import paddlehub
import cv2
from playsound import playsound
#指定paddlehub模块的视觉算法
module=paddlehub.Module(name="pyramidbox_lite_mobile_mask")
#调用本机摄像头
cap=cv2.VideoCapture(0)
#循环判断面部区域位置
while(cap.isOpened()):
frame = cap.read()[1]
input_dict = 'data':[frame]
results = module.face_detection(data=input_dict)
result = results[0]
#绑定键盘监听事件
k = cv2.waitKey(1) & 0xFF # 判断按键
#当判断为肯定时,则绘制绿色矩形及文字
if result['data']!=[]:
label = result['data'][0]['label']
left = result['data'][0]['left']
right = result['data'][0]['right']
top = result['data'][0]['top']
bottom = result['data'][0]['bottom']
color = (0,255,0)
color2 = (0,255,0)
#当判断为否定式绘制红色矩形及文字
if label == 'NO MASK':
color = (0,0,255)
color2 = (0,0,255)
#打开录制的MP3语音文件
playsound('1.mp3')
#cv2最会的绘制及显示
cv2.rectangle(frame,(left,top),(right,bottom),color,3)
cv2.putText(frame,label,(left,top-10),cv2.FONT_HERSHEY_SIMPLEX,0.8,color2,2)
#显示交互窗口
cv2.imshow('xianshi',frame)
#监听键盘事件,并判断是否退出
if k == ord(' '):#退出
break
#释放摄像头
cap.release()
#释放内存
cv2.destroyAllWindows()效果展示(不带口罩时会有重复语音警告)

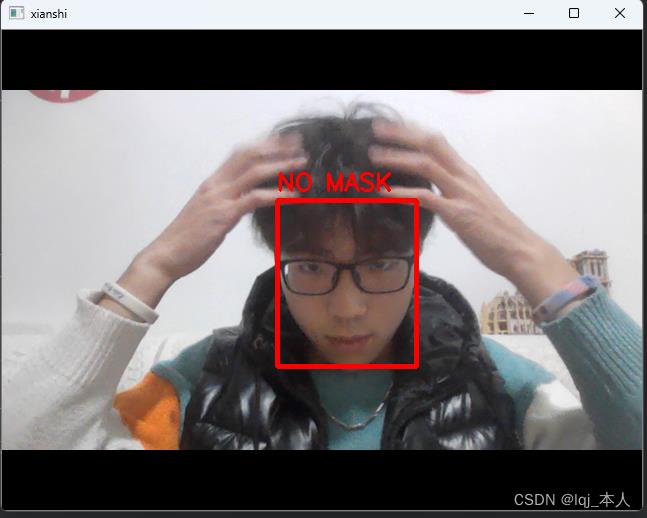
以上是关于python进阶——AI视觉实现口罩检测实时语音报警系统的主要内容,如果未能解决你的问题,请参考以下文章
五分钟快速搭建一个实时人脸口罩检测系统(OpenCV+PaddleHub 含源码)
基于深度学习的口罩检测系统(Python+清新界面+数据集)