语义分割学习
Posted zxxxxh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了语义分割学习相关的知识,希望对你有一定的参考价值。

滑窗预测
利用分类模型逐像素分类,并且可以复用卷积计算。但是因为分类网络输出前有全连接层,因此要求网络的输入固定。

全卷积网络
将全连接层卷积化,使其不受输入图片宽高的影响。


图像分类模型使用降采样层(步长卷积或池化)获得 高层次特征,导致全卷积网络输出尺寸小于原图,而 分割要求同尺寸输 出。因此,对预测的分割图升采样。
双线性插值
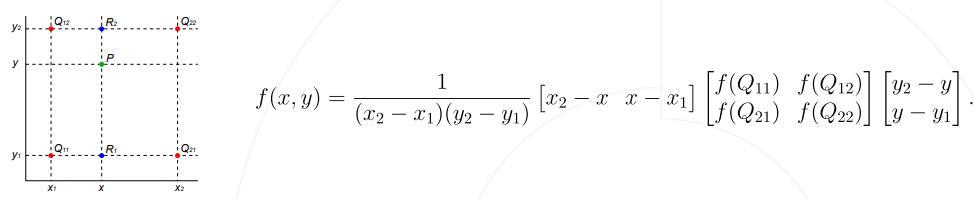

转置卷积

高层特征经过多次下采样,细节丢失严重。因此人们想到将低层次和高层次的特征结合。如FCN、U-Net等。
FCN
基于低层次和高层次特征图分别产生类别预测,升采样到原图大小,再平均得到最终结果。

U-Net
逐级融合高低层次特征。

PSPNet
对特征图进行不同的池化,得到不同尺度的上下文特征。小的特征图对应着更大的感受野,获取大范围的信息,大的特征图包含着局部信息。

DeepLab系列
贡献:
使用空洞卷积解决下采样问题
图像分类模型中的下采样层是输出尺寸变小。而对于分割任务,希望特征图的尺寸保持。因此希望减少网络中的下采样。
去掉池化层和令卷积输入输出尺寸相同,减少下采样次数,但是特征图会变大,需要对应增大卷积核的大小,维持相同的感受野。这样会增大参数量。而使用空洞卷积,就可以在不增加参数的情况下增大感受野。
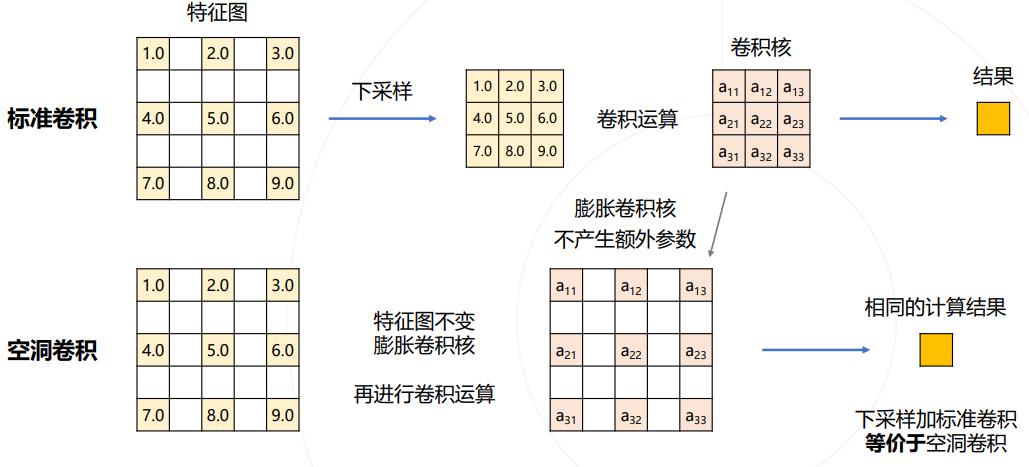
DeepLab在分类网络上修改:1)去除分类模型中的后半部分的下采样层;2)将后续的卷积改为膨胀卷积,并逐步增加rate维持原网络的感受野。

使用条件随机场CRF后处理
CRF 是一种概率模型。DeepLab 使用 CRF 对分割结果进行建模,用能量函数用来表示分割结 果优劣,通过最小化能量函数获得更好的分割结果。



使用多尺度空洞卷积捕捉上下文信息
PSPNet使用不同尺度的池化来获取不同尺度的上下文信息,DeepLab v2、v3使用不同尺度的空洞卷积达到类似的效果。

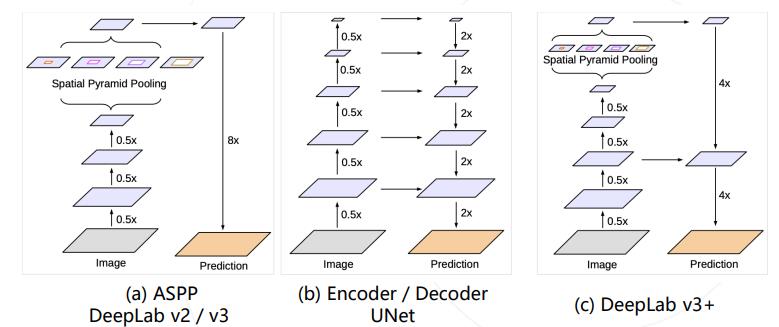
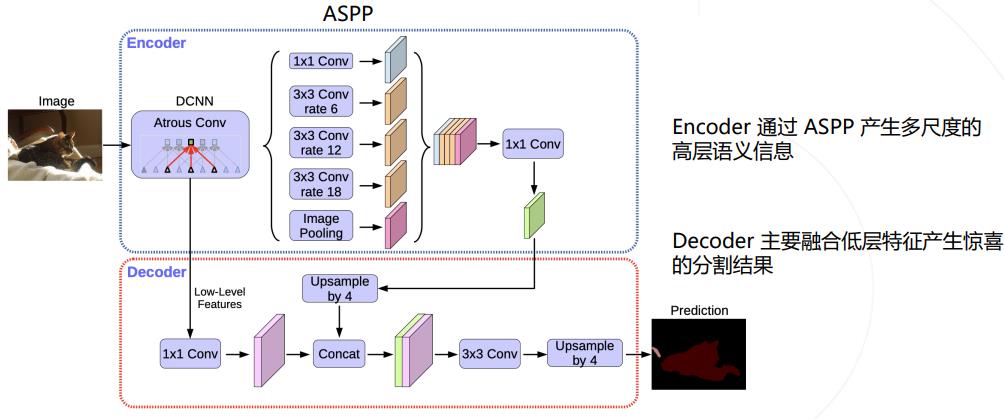
DeepLab v2/v3 模型使用 ASPP 捕捉上下文特征 ,Encoder/Decoder 结构(如 UNet) 在上采样过程中融入低层次的特征图,以获得更精细的分割图 。 DeepLab v3+ 将两种思路融合,在原有模型结构上增加了一个简单的 decoder 结构。
以上是关于语义分割学习的主要内容,如果未能解决你的问题,请参考以下文章