工业部分 人工智能
Posted 厨 神
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了工业部分 人工智能相关的知识,希望对你有一定的参考价值。
数据挖掘
特征工程
官网教程
决策树算法|随机森林|决策树模型|机器学习算法|人工智能
0. 初始化spark
val spark=new SparkSession.Builder()
.master("local[*]")
.config("spark.sql.warehouse.dir","hdfs://bigdata1:9000/user/hive/warehouse")
.appName("test")
.enableHiveSupport()
.getOrCreate()
- 读取mysql数据(shtd_industry.MachineData)
val url = "jdbc:mysql://mysql:3306/shtd_industry?useSSL=false"
val table="Machine_Data"
val prop=new Properties()
prop.setProperty("driver","com.mysql.jdbc.Driver")
prop.setProperty("user","root")
prop.setProperty("password","123456")
spark.read.jdbc(url,table,prop).createTempView("MachineData")
- dem4j解析数据
#xpath使用方法同python
返回string
xpath_string(xml所在字段,‘//b(xpath表达式)’) from table;
返回array
xpath(字段/‘132’,‘a/b/text()’)
=>[1,3]
//@id:有id的
//c[@class=‘aaa’]
#current_timestamp()==>2023-02-07 08:26:09.961
create table test_table2(id int,dt timestamp default current_timestamp());
CREATE VIEW companyview
(id,name,email,houseno,street,city,state,pincode,country,passport,visa,mobile,phone)
AS SELECT
xpath(xmldata,'Company/Employee/Id/text()'),
xpath_string(xmldata,'col[@ColName='主轴转速']'), //所有col标签中colName为主轴转速
xpath(xmldata,'Company/Employee/Email/text()'),
xpath(xmldata,'Company/Employee/Address/HouseNo/text()'),
xpath(xmldata,'Company/Employee/Address/Street/text()'),
xpath(xmldata,'Company/Employee/Address/City/text()'),
xpath(xmldata,'Company/Employee/Address/State/text()'),
xpath(xmldata,'Company/Employee/Address/Pincode/text()'),
xpath(xmldata,'Company/Employee/Address/Country/text()'),
xpath(xmldata,'Company/Employee/Passport/text()'),
xpath(xmldata,'Company/Employee/Visa/text()'),
xpath(xmldata,'Company/Employee/Contact/Mobile/text()'),
xpath(xmldata,'Company/Employee/Contact/Phone/text()')
FROM companyxml;
spark.sql(
s"""
| select MachineRecordID,MachineID,if(MachineRecordState='报警',1,0),
| xpath_string(MachineRecordData,"//col[@ColName='主轴转速']/text()"),
| xpath_string(MachineRecordData,"//col[@ColName='主轴倍率']/text()"),
| xpath_string(MachineRecordData,"//col[@ColName='主轴负载']/text()"),
| xpath_string(MachineRecordData,"//col[@ColName='进给倍率']/text()"),
| xpath_string(MachineRecordData,"//col[@ColName='进给速度']/text()"),
| xpath_string(MachineRecordData,"//col[@ColName='PMC程序号']/text()"),
| xpath_string(MachineRecordData,"//col[@ColName='循环时间']/text()"),
| xpath_string(MachineRecordData,"//col[@ColName='运行时间']/text()"),
| xpath_string(MachineRecordData,"//col[@ColName='有效轴数']/text()"),
| xpath_string(MachineRecordData,"//col[@ColName='总加工个数']/text()"),
| xpath_string(MachineRecordData,"//col[@ColName='已使用内存']/text()"),
| xpath_string(MachineRecordData,"//col[@ColName='未使用内存']/text()"),
| xpath_string(MachineRecordData,"//col[@ColName='可用程序量']/text()"),
| xpath_string(MachineRecordData,"//col[@ColName='注册程序量']/text()"),
| MachineRecordDate,
| "root",
| current_timestamp(),
| "root",
| MachineRecordDate
| from $table
|""".stripMargin).show(2)
mysql解析用extractvalue
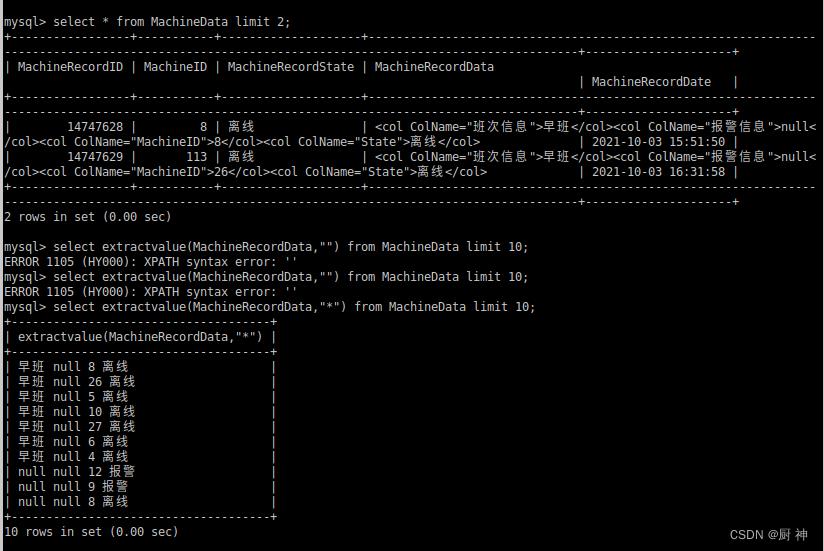 #java的xml解析,但只能解析文件
#java的xml解析,但只能解析文件
val saxReader=new SAXReader()
saxReader.read(Main.class.getClassLoader().getResource("user.xml"))
#scala的xml解析,可传string,file,xml,url
val data="<col ColName=\\"设备IP\\">192.168.2.27</col><col ColName=\\"进给速度\\">null</col><col ColName=\\"急停状态\\">null</col><col ColName=\\"加工状态\\">null</col><col ColName=\\"刀片相关信息\\">null</col><col ColName=\\"切削时间\\">null</col><col ColName=\\"未使用内存\\">null</col><col ColName=\\"循环时间\\">null</col><col ColName=\\"报警信息\\">null</col><col ColName=\\"主轴转速\\">null</col><col ColName=\\"上电时间\\">null</col><col ColName=\\"总加工个数\\">null</col><col ColName=\\"班次信息\\">null</col><col ColName=\\"运行时间\\">null</col><col ColName=\\"正在运行刀具信息\\">null</col><col ColName=\\"有效轴数\\">0</col><col ColName=\\"主轴负载\\">null</col><col ColName=\\"PMC程序号\\">null</col><col ColName=\\"进给倍率\\">0</col><col ColName=\\"主轴倍率\\">null</col><col ColName=\\"已使用内存\\">null</col><col ColName=\\"可用程序量\\">null</col><col ColName=\\"刀补值\\">null</col><col ColName=\\"工作模式\\">null</col><col ColName=\\"机器状态\\">离线</col><col ColName=\\"连接状态\\">faild</col>"
val xml=XML.loadString("<div>"+data+"</div>")
(xml \\"div"\\ "col").foreach(prinitln)
//新建
val xmlUrl= <a>" "+"https://www.baidu.com"+" " </a>
val xmlUrl1=XML.loadString("<a> https://www.baicu.dom </a>")
XML.save("url.xml",xmlUrl,"UTF-8",true,null)
val xmlUrl2=XML.loadFile("url.xml")
val age=30
val xmlUrl3=if(age<29) <age>age</age> else NodeSeq.Empty
//获取元素
// \\子元素 \\\\下级任意元素 @attitude属性值 text:mkString() node match case <a>sub_ele</a>=>println(sub_ele) case sub_ele @_*
//把XML.load包装成udf
//scala版本必须是2.12.8以上,不然用不了udf,请确认(修这个修一天),maven的denpencies必须是scala2.12.8以上!!!!!
- 设置默认值
hive设置默认值
create table test_default(id int, dt timestamp default current_timestamp());
crate table ....default 0.0 as
select * from...
- 根据中文设置值,(报警1 不报警0)
insert into result values()
select if("报警",1,0)
HIVE根据中文设置字段值
- 保存到dwd.fact_machine_learning_data
spark.sql("""
|insert overwrite table dwd.fact_machine_learning_data
|select * from result
""".stripMargin)
- 根据machine_record_id排序并查询第一条
select * from dwd.fact_machine_learning_data order by machine_record_id limit 1
错误:
8. insert失败出现:
Can’t fetch tasklog: TaskLogServlet is not supported in MR2 mode.:
解决办法:
set hive.exec.mode.local.auto=true;
9. hive的list获取大小用size(name) length是获取字符串长度 split(name,‘,’)按照逗号分割
10. for(i <- 0 to 18)
11.case class ClassName(name1:Type,name2:Type)lazy val time=name1*60+name2
11. org.apache.spark.SparkException: Task not serializable 在使用udf的时候出错是因为scala版本要是2.12.8以上!
- hive转换类型cast(name as double) 别名
- ListBuffer是可变数组 ,用+=添加元素
- hive的list类型用name[i]获取元素,split可以转为list
完整代码
import org.apache.log4j.Level, Logger
import org.apache.spark.sql.SparkSession
import java.util.Properties
import scala.collection.mutable.ListBuffer
import scala.xml.XML
object workOne extends Serializable
def main(args: Array[String]): Unit =
//设置系统用户为root,防止出现访问hdfs没有权限
System.setProperty("HADOOP_USER_NAME","root")
//去掉INFO日志,只保留ERROR
Logger.getLogger("org").setLevel(Level.ERROR)
//spark初始化
val spark = new SparkSession.Builder()
.master("local[*]")
.config("spark.sql.warehouse.dir", "hdfs://master:9000/user/hive/warehouse")
.appName("test")
.enableHiveSupport()
.getOrCreate()
//连接数据库
//if是为了能调试
if(1==1)
val url = "jdbc:mysql://mysql:3306/shtd_industry?useSSL=false"
val mysqlTable = "MachineData"
val prop = new Properties()
prop.setProperty("driver", "com.mysql.jdbc.Driver")
prop.setProperty("user", "root")
prop.setProperty("password", "123456")
spark.read.jdbc(url, mysqlTable, prop).createTempView("MachineData")
val table="dwd.fact_machine_learning_data"
//创建数据库
if(1==1)
// create table test_table2(id int, dt timestamp default current_timestamp());
spark.sql(
s"""
|create table if not exists $table(
|machine_record_id int,
|machine_id double,
|machine_record_state double,
|machine_record_mainshaft_speed double,
|machine_record_mainshaft_multiplerate double,
|machine_record_mainshaft_load double,
|machine_record_feed_speed double,
|machine_record_feed_multiplerate double,
|machine_record_pmc_code double,
|machine_record_circle_time double,
|machine_record_run_time double,
|machine_record_effective_shaft double,
|machine_record_amount_process double,
|machine_record_use_memory double,
|machine_record_free_memory double,
|machine_record_amount_use_code double,
|machine_record_amount_free_code double,
|machine_record_date timestamp,
|dwd_insert_user string,
|dwd_insert_time timestamp,
|dwd_modify_user string,
|dwd_modify_time timestamp
|)
|""".stripMargin)
spark.sql(s"desc $table").show()
//hql的xpath_string处理数据
//废弃,以后再看
if(0==1)
spark.udf.register("compilerXML", (s: String) =>
val xml = XML.loadString("<div>" + s + "</div>")
(xml \\\\ "col").foreach(x =>
println(x \\ "@ColName")
)
)
spark.sql(
s"""
|insert overwrite table $table
| select * from (
| select MachineRecordID,MachineID,if(MachineRecordState='报警',1,0),
| xpath_string('<div>'+MachineRecordData+'</div>',"//col[@ColName='主轴转速']/text()"),
| xpath_string('<div>'+MachineRecordData+'</div>',"//col[@ColName='主轴倍率']/text()"),
| xpath_string('<div>'+MachineRecordData+'</div>',"//col[@ColName='主轴负载']/text()"),
| xpath_string('<div>'+MachineRecordData+'</div>',"//col[@ColName='进给倍率']/text()"),
| xpath_string('<div>'+MachineRecordData+'</div>',"//col[@ColName='进给速度']/text()"),
| xpath_string('<div>'+MachineRecordData+'</div>',"//col[@ColName='PMC程序号']/text()"),
| xpath_string('<div>'+MachineRecordData+'</div>',"//col[@ColName='循环时间']/text()"),
| xpath_string('<div>'+MachineRecordData+'</div>',"//col[@ColName='运行时间']/text()"),
| xpath_string('<div>'+MachineRecordData+'</div>',"//col[@ColName='有效轴数']/text()"),
| xpath_string('<div>'+MachineRecordData+'</div>',"//col[@ColName='总加工个数']/text()"),
| xpath_string('<div>'+MachineRecordData+'</div>',"//col[@ColName='已使用内存']/text()"),
| xpath_string('<div>'+MachineRecordData+'</div>',"//col[@ColName='未使用内存']/text()"),
| xpath_string('<div>'+MachineRecordData+'</div>',"//col[@ColName='可用程序量']/text()"),
| xpath_string('<div>'+MachineRecordData+'</div>',"//col[@ColName='注册程序量']/text()"),
| MachineRecordDate,
| "root",
| current_timestamp(),
| "root",
| MachineRecordDate
| from $table
| ) a
|""".stripMargin)
//scala的XML解析数据
if(1==1)
//udf要求必须是scala必须是 2.12.8以上,不然用不了
spark.udf.register("xmlCompile", str: String =>
//减少计算量,提前分离出来
val xml = XML.loadString("<div>" + str + "</div>") \\\\"col"
// (xml \\\\ "col" ).map(_\\"@ColName").asInstanceOf[]
//数据结果为list,也可以用mkString(",") ==>xml.map().mkString(",")
val result=new ListBuffer[Double]()
val lis=List("主轴转速","主轴倍率","主轴负载","进给倍率","进给速度","PMC程序号","循环时间","循环时间","有效轴数","总加工个数","已使用内存","未使用内存","可用程序量","注册程序量")
for(i <- 0 to lis.length-1)
val a=xml.filter(_.attribute("ColName").exists(_.text.equals(lis(i)))).text
result += (if (a=="null"|a=="") 0.0 else a.toDouble)
println(result.toList)
result.mkString(",")
)
//提前分出来建表语句的一部分,可以用idea快捷键快速完成
val lists=
"""
|cast(myData[0] as decimal(1,0)) machine_record_mainshaft_speed,
|cast(myData[1] as double) machine_record_mainshaft_multiplerate,
|cast(myData[2] as double) machine_record_mainshaft_load,
|cast(myData[3] as double) machine_record_feed_speed,
|cast(myData[4] as double) machine_record_feed_multiplerate,
|cast(myData[5] as double) machine_record_pmc_code,
|cast(myData[6] as double) machine_record_circle_time,
|cast(myData[7] as double) machine_record_run_time,
|cast(myData[8] as double) machine_record_effective_shaft,
|cast(myData[9] as double) machine_record_amount_process,
|cast(myData[10] as double) machine_record_use_memory,
|cast(myData[11] as double) machine_record_free_memory,
|cast(myData[12] as double) machine_record_amount_use_code,
|cast(myData[13] as double) machine_record_amount_free_code,
|""".stripMargin
if(0==1)
//测试xmlCompile的udf功能能不能用
val xml="<col ColName=\\"设备IP\\">192.168.2.27</col><col ColName=\\"进给速度\\">null</col><col ColName=\\"急停状态\\">null</col><col ColName=\\"加工状态\\">null</col><col ColName=\\"刀片相关信息\\">null</col><col ColName=\\"切削时间\\">null</col><col ColName=\\"未使用内存\\">null</col><col ColName=\\"循环时间\\">null</col><col ColName=\\"报警信息\\">null</col><col ColName=\\"主轴转速\\">null</col><col ColName=\\"上电时间\\">null</col><col ColName=\\"总加工个数\\">null</col><col ColName=\\"班次信息\\">null</col><col ColName=\\"运行时间\\">null</col><col ColName=\\"正在运行刀具信息\\">null</col><col ColName=\\"有效轴数\\">0</col><col ColName=\\"主轴负载\\">null</col><col ColName=\\"PMC程序号\\">null</col><col ColName=\\"进给倍率\\">0</col><col ColName=\\"主轴倍率\\">null</col><col ColName=\\"已使用内存\\">null</col><col ColName=\\"可用程序量\\">null</col><col ColName=\\"刀补值\\">null</col><col ColName=\\"工作模式\\">null</col><col ColName=\\"机器状态\\">离线</col><col ColName=\\"连接状态\\">faild</col>"
spark.sql(s"select xmlCompile('$xml')").show()
val xml2="<col ColName=\\"班次信息\\">早班</col><col ColName=\\"报警信息\\">null</col><col ColName=\\"MachineID\\">8</col><col ColName=\\"State\\">离线</col>"
//测试插入语句能不能用
spark.sql("insert overwrite table test.test_table3 values(10,'张三',1)")
//最后插入sql
spark.sql(s"""
|insert overwrite table $table
|select machine_record_id,machine_id,if(machine_record_state=="报警",1,0) machine_record_state,$listsmachine_record_date,"root",machine_record_date,"root",current_timestamp()
|from
|(
|select cast(MachineRecordID as double) machine_record_id,MachineID machine_id,MachineRecordState machine_record_state,split(xmlCompile(MachineRecordData),",") myData,MachineRecordDate machine_record_date from MachineData
|)a
|
|""".stripMargin).show()
//https://blog.csdn.net/hutao_ljj/article/details/109023490
//https://blog.csdn.net/qq_34105362/article/details/80408621
spark.stop()
报警预测
- 导入数据
- 数据转换,转成libsvm格式
- 建立模型
- 评估模型
- 保存数据
数据格式:
0 128:73 129:253 130:227 131:73 132:21 156:73 157:251 158:251 159:251 160:174 182:16 183:166 184:228 185:251 186:251 187:251 188:122 210:62 211:220 212:253 213:251 214:251 215:251 216:251 217:79 238:79 239:231 240:253 241:251 242:251 243:251 244:251 245:232 246:77 264:145 265:253 266:253 267:253 268:255 269:253 270:253 271:253 272:253 273:255 274:108 292:144 293:251 294:251 295:251 296:253 297:168 298:107 299:169 300:251 301:253 302:189 303:20 318:27 319:89 320:236 321:251 322:235 323:215 324:164 325:15 326:6 327:129 328:251 329:253 330:251 331:35 345:47 346:211 347:253 348:251 349:251 350:142 354:37 355:251 356:251 357:253 358:251 359:35 373:109 374:251 375:253 376:251 377:251 378:142 382:11 383:148 384:251 385:253 386:251 387:164 400:11 401:150 402:253 403:255 404:211 405:25 410:11 411:150 412:253 413:255 414:211 415:25 428:140 429:251 430:251 431:253 432:107 438:37 439:251 440:251 441:211 442:46 456:190 457:251 458:251 459:253 460:128 461:5 466:37 467:251 468:251 469:51 484:115 485:251 486:251 487:253 488:188 489:20 492:32 493:109 494:129 495:251 496:173 497:103 512:217 513:251 514:251 515:201 516:30 520:73 521:251 522:251 523:251 524:71 540:166 541:253 542:253 543:255 544:149 545:73 546:150 547:253 548:255 549:253 550:253 551:143 568:140 569:251 570:251 571:253 572:251 573:251 574:251 575:251 576:253 577:251 578:230 579:61 596:190 597:251 598:251 599:253 600:251 601:251 602:251 603:251 604:242 605:215 606:55 624:21 625:189 626:251 627:253 628:251 629:251 630:251 631:173 632:103 653:31 654:200 655:253 656:251 657:96 658:71 659:20
1 155:178 156:255 157:105 182:6 183:188 184:253 185:216 186:14 210:14 211:202 212:253 213:253 214:23 238:12 239:199 240:253 241:128 242:6 266:42 267:253 268:253 269:158 294:42 295:253 296:253 297:158 322:155 323:253 324:253 325:158 350:160 351:253 352:253 353:147 378:160 379:253 380:253 381:41 405:17 406:225 407:253 408:235 409:31 433:24 434:253 435:253 436:176 461:24 462:253 463:253 464:176 489:24 490:253 491:253 492:176 517:24 518:253 519:253 520:176 545:24 546:253 547:253 548:162 573:46 574:253 575:253 576:59 601:142 602:253 603:253 604:59 629:142 630:253 631:253 632:59 657:142 658:253 659:202 660:8 685:87 686:253 687:139
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.feature.VectorIndexer
import org.apache.spark.ml.regression.RandomForestRegressionModel,RandomForestRegressor
//准备数据
val data=spark.read.format("libsvm").load("/opt/module/spark/data/mllib/sample_libsvm_data.txt")
val featureIndexer=new VectorIndexer()
.setInputCol("features")
.setOutputCol("indexedFeatures")
.setMaxCategories(4).fit(data)
val Array(trainingData,testData)=data.randomSplize(Array(0.7,0.3))
trainingData.show()
//建立随机森林模型new RandomForestRegressor
val rf=new RandomForestRegressor().setLabelCol("label").setFeaturesCol("indexedFeatures")
//使用管道pipeline进行随机森林同步训练
val pipeline=new Pipeline().setStages(Array(featureIndexer,rf))
//训练
val model=pipeline.fit(trainingData)
//预测
val predictions=model.transform(testData)
predictions.show(5)
//评测new RegressionEvaluator()
val evaluator=new RegressionEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("rmse")
val rmse=evaluator.evaluate(predictions)
println(s"")
//TODO 随机森林模型建立
if(0==1)
//hive数据转为LabeldPointed
import spark.implicits._
val data1 = spark.sql(s"""select * from $table""")
.rdd.map(x =>
//double的df转为labeledPoint的df
LabeledPoint(x.getDouble(2), Vectors.dense(x.getDouble(3)
, x.getDouble(4)
, x.getDouble(5)
, x.getDouble(6)
, x.getDouble(7)
, x.getDouble(8)
, x.getDouble(9