大数据处理学习笔记1.1 搭建Scala开发环境
Posted howard2005
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据处理学习笔记1.1 搭建Scala开发环境相关的知识,希望对你有一定的参考价值。
文章目录
零、本讲学习目标
- 了解Scala语言的特点
- 学会搭建Scala开发环境
- 了解命令行模式与编译模式
一、Scala简介
(一)Scala概述
- Scala是Scalable Language的简写,是一门多范式的编程语言,由联邦理工学院洛桑(EPFL)的Martin Odersky于2001年基于Funnel的工作开始设计,设计初衷是要集成面向对象编程和函数式编程的各种特性。
- Scala是一种将面向对象和函数式编程结合在一起的高级语言,旨在以简洁、优雅和类型安全的方式表达通用编程模式。Scala功能强大,不仅可以编写简单脚本,还可以构建大型系统。
- Scala运行于Java平台,Scala程序会通过JVM被编译成class字节码文件,然后在操作系统上运行。其运行时候的性能通常与Java程序不分上下,并且Scala代码可以调用Java方法、继承Java类、实现Java接口等,几乎所有Scala代码都大量使用了Java类库。
- Scala 是完全兼容Java的,其实Scala就是在Java语言的基础上增加了一层编码的 “壳”,让程序人员可以通过函数式编程的方式来开发程序。由于Scala最终被编译为.class,所以其实本质上还是Java,所以在Scala中可以任意的调用Java的API。好处显而易见:让Jva程序员可以更无障碍的转到Scala;让原先Java的API仍然可以在Scala中使用;公司中的Java平台不用替换就可以使用Scala。
(二)函数式编程
-
函数式编程:将所有复杂的问题的解决,拆分为若干函数的处理。每一个函数可以去实现一部分功能,利用很多次函数的处理,最终解决问题。
-
函数式编程相对于面向对象编程,更加抽象,好处是,代码可以非常简洁,更多采用常量而不是变量来解决问题,这样额外带来的好处:在线程并发时,可以减少甚至杜绝多线程并发安全问题,特别适合于应用在处理高并发场景、分布式场景下的问题。函数式编程可以使用高阶函数,函数是一等公民,可以更加灵活的进行程序的编写。
-
函数式编程并不是面向对象编程的发展,而是另外一种解决问题的思路,两者之间也并没有绝对的好坏之分,在不同的场景中各有各的优缺点。
(三)Scala特性
- 在很多地方
Scala都很像Java,也是静态类型语言,但是比Java更为函数式编程,这句话主要从三句话就可以理解“一切都是对象”,“一切都是函数”以及“一切都是表达式”三方面理解。
1、一切都是对象
Scala里一切都是对象,这大概和Python很像,因为即便是数字1都有一系列的方法,所以我们可以调用1.toDouble将Int类型的1转换为Double类型的1。
2、一切都是函数
- 表现为可以重载操作符,跟
Python很像,在一定程度上Scala是Java和Python生的孩子,只不过遗传基因比较大的卵子是Java提供的,而比较小的那颗精子则是Python提供的。
3、一切都是表达式
- 在
Scala里,一切都是表达式,即使像if()else这样的语句块也是有返回值的。
(四)在线运行Scala
- 通过浏览器访问:Scala在线工具
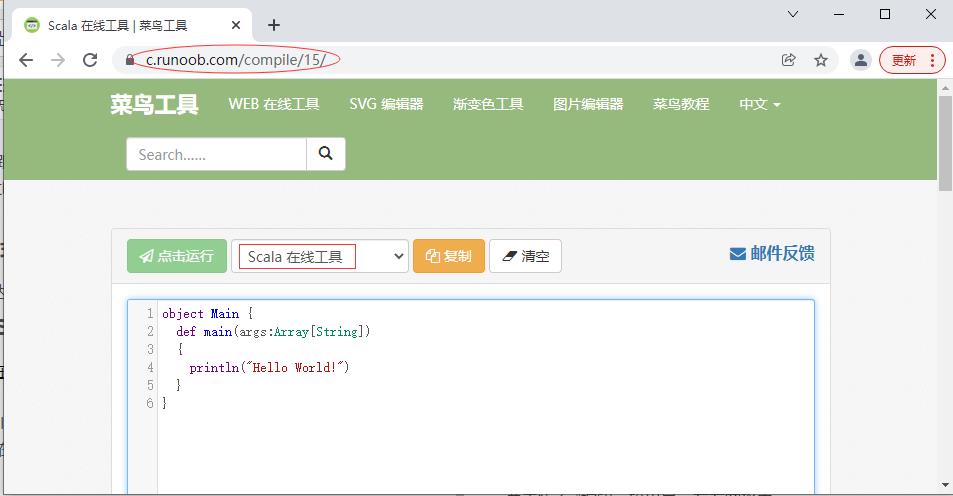
- 单击【点击运行】按钮,可以查看代码运行结果
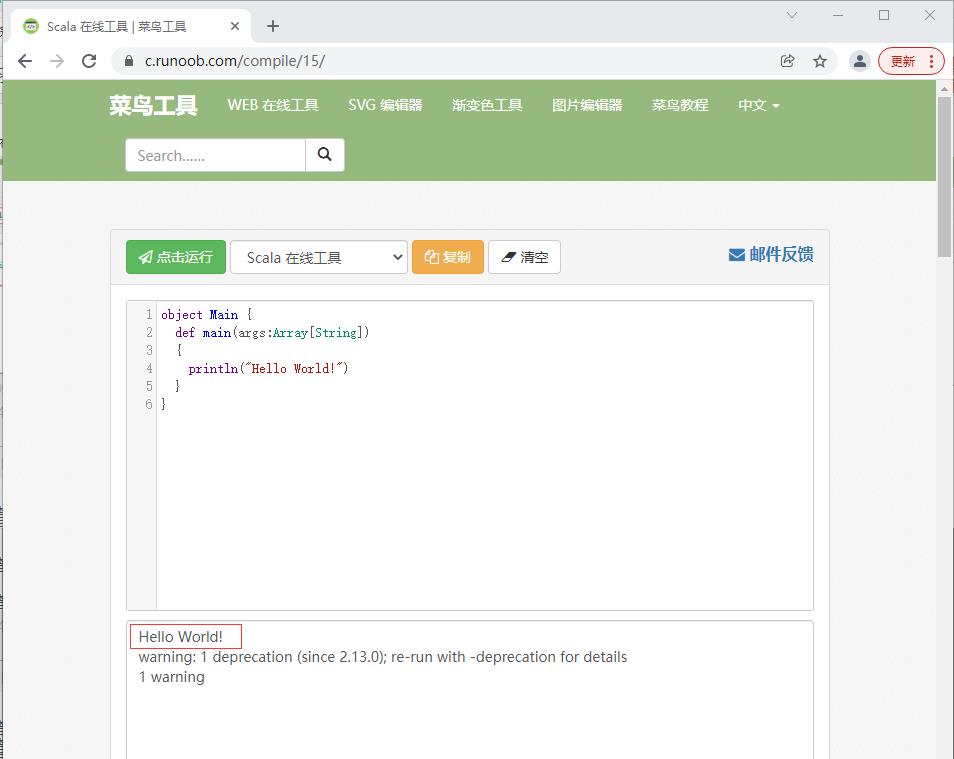
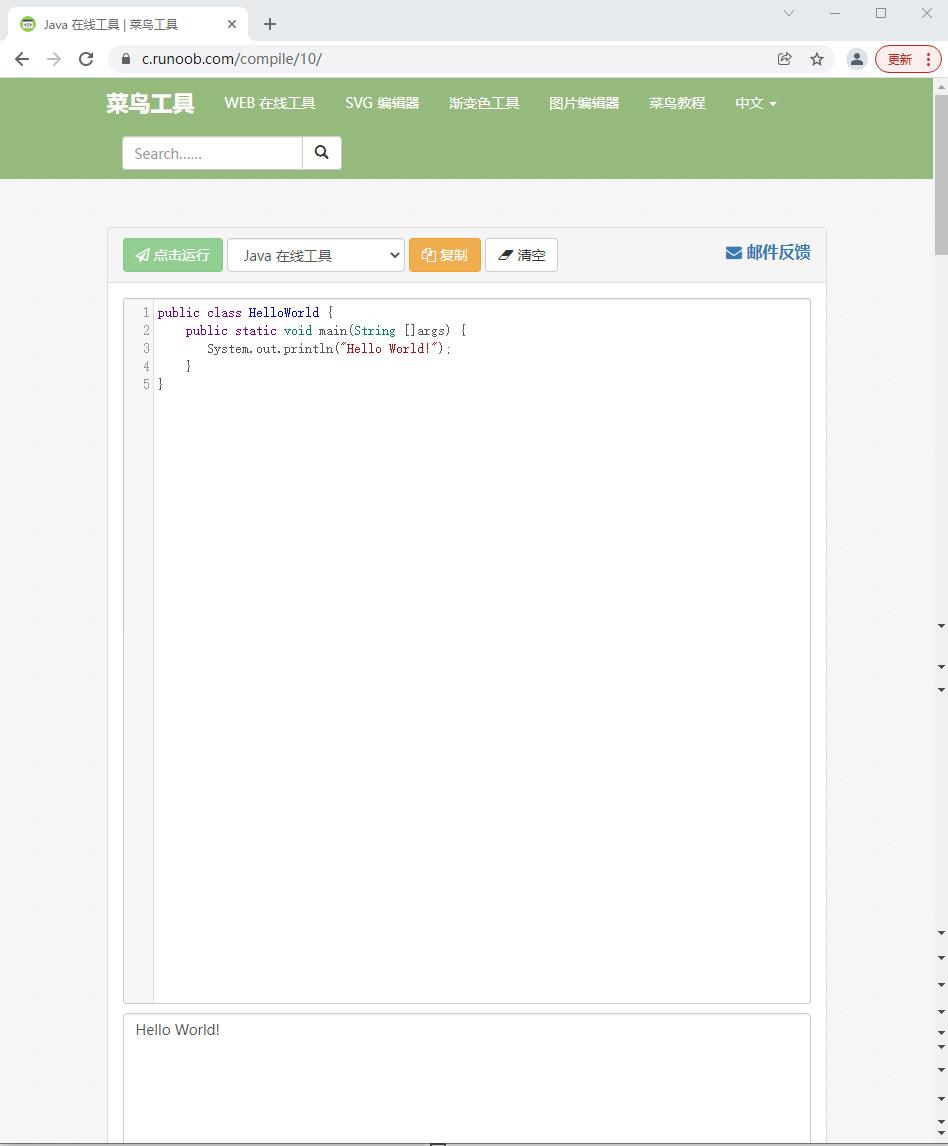
- 大家可以对照一下
Java的HelloWorld程序,两者完全一一对应,相似度极高
二、选择Scala版本
- 本次学习我们准备采用Spark3.3.1,为了后续操作不出现任何匹配方面的问题,建议采用跟Spark版本匹配的Scala。
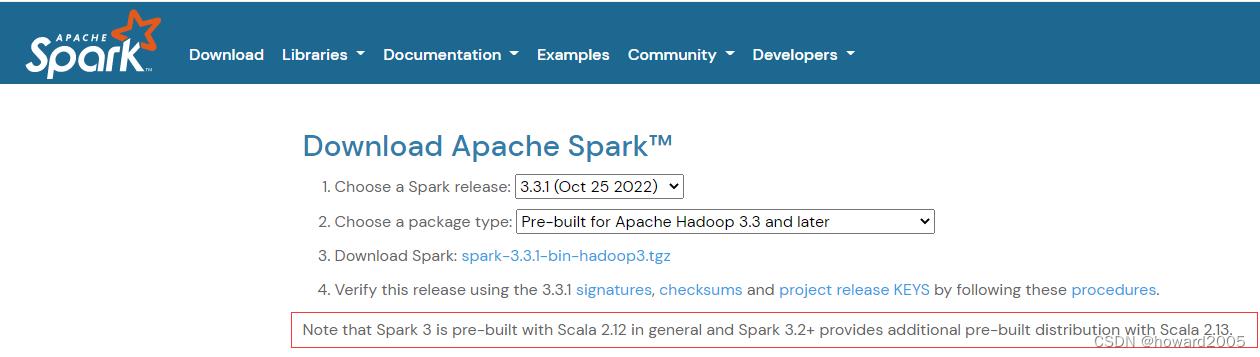
- 根据Spark官网建议,我们最好下载Scala 2.13版本
三、Windows上安装Scala
(一)到Scala官网下载Scala
-
Scala2.13.10下载网址:https://www.scala-lang.org/download/2.13.10.html
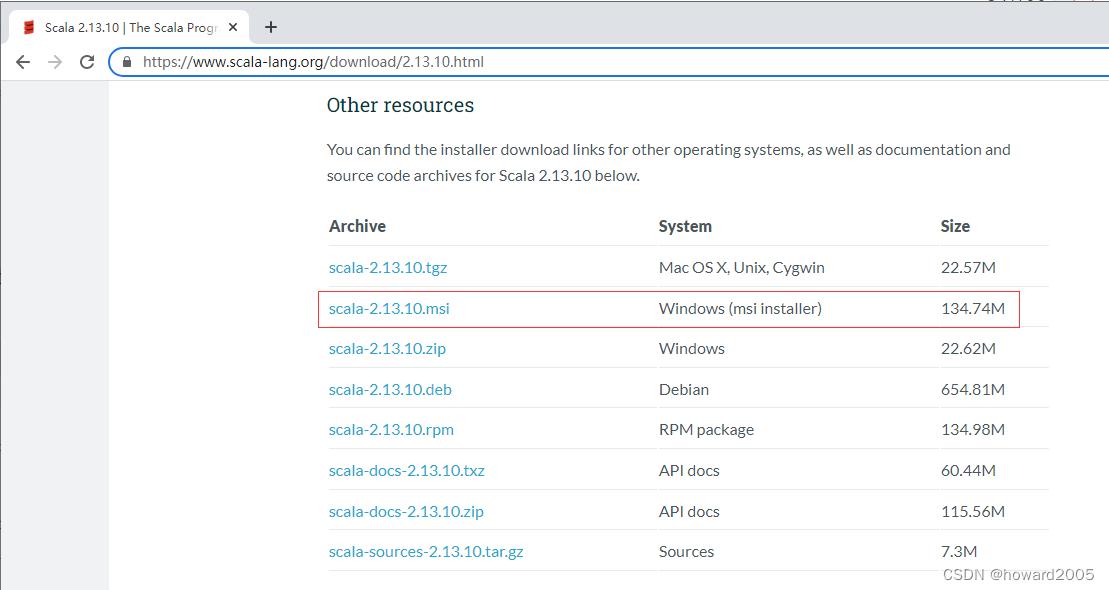
-
单击【scala-2.13.10.msi】超链接,将scala安装程序下载到本地
(二)安装Scala
- 双击安装程序图标,进入安装向导,按提示进行操作,完成Scala的安装

- 安装到默认的位置:
C:\\Program Files (x86)\\scala,当然你也可以安装到其它位置
(三)配置Scala环境变量
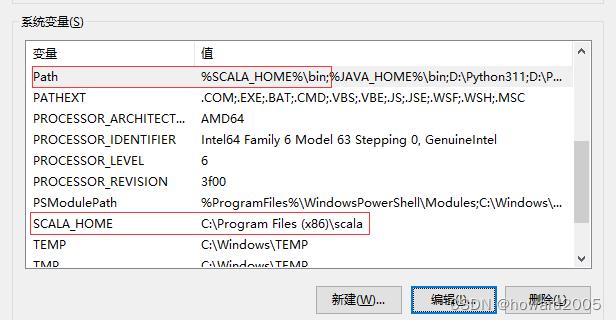
- 设置Windows系统的环境变量
| 变量名 | 变量值 |
|---|---|
| SCALA_HOME | C:\\Program Files (x86)\\scala |
| Path | %SCALA_HOME%\\bin |
- 通常Scala安装完成后会自动将Scala的bin目录的路径添加到系统Path变量中。若Path变量中无该路径,则需要手动添加。
(四)测试Scala是否安装成功
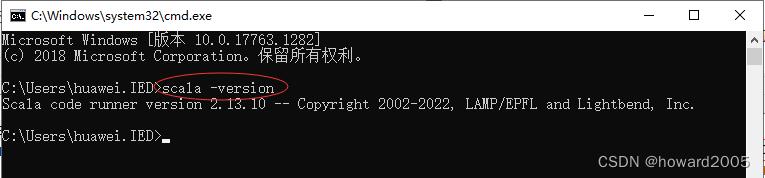
1、查看Scala版本
- 启动命令行窗口,执行
scala -version命令,若能正确输出当前Scala版本信息,则说明安装成功
2、启动Scala,执行语句
-
在命令行提示后输入
scala,则会进入Scala的命令行模式,在此可以编写Scala表达式和程序
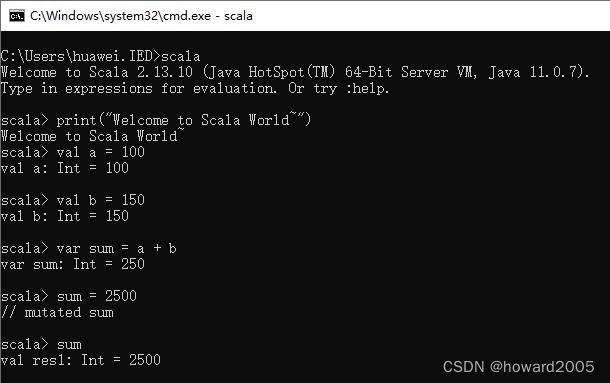
-
val -
value:用于定义Scala常量 -
var -
variable:用于定义Scala变量 -
常量只能赋值一次,再次赋值是不允许的
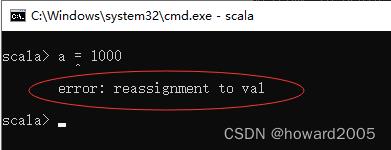
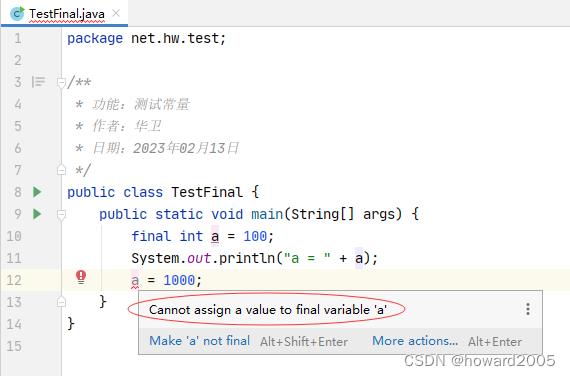
-
Scala里
val定义的变量相当于Java里用final定义的变量,其实都是常量,不能再给它赋值
四、Linux上安装Scala
(一)到Scala官网下载Scala
- Scala2.13.10下载网址:https://www.scala-lang.org/download/2.13.10.html
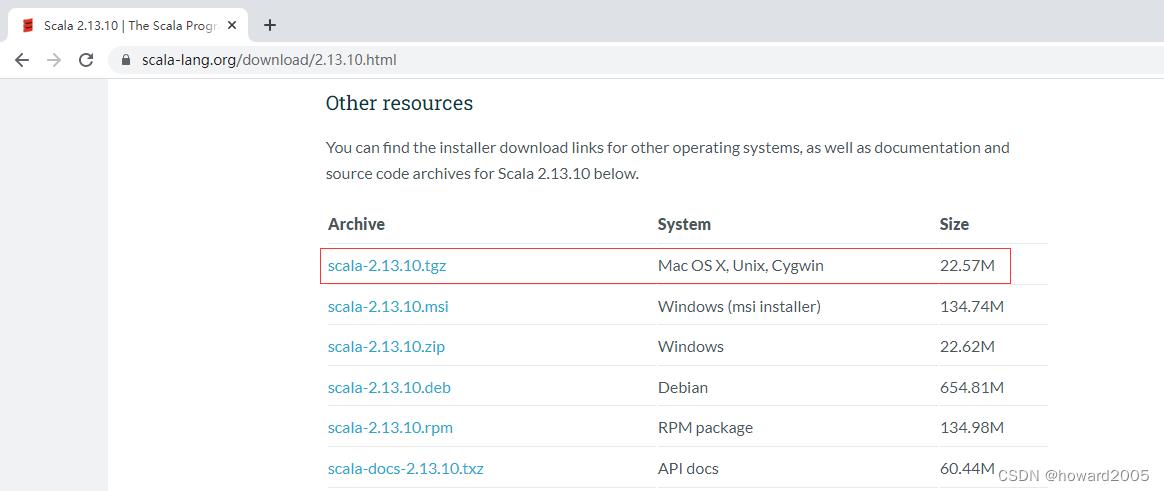
- 单击【scala-2.13.10.tgz】超链接,将scala安装包下载到本地
(二)安装Scala
1、登录ied虚拟机
- 利用FinalShell登录ied虚拟机

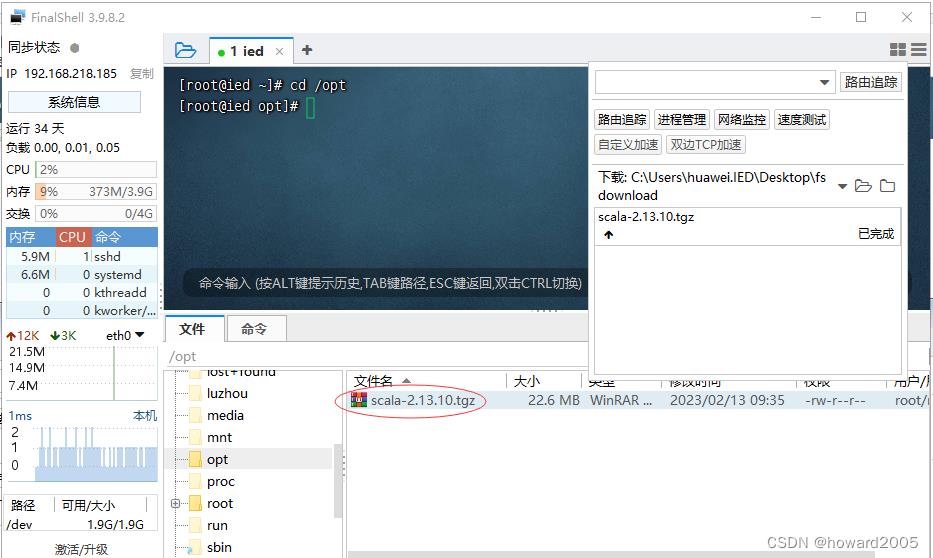
2、上传scala安装包到ied虚拟机
- 进入
/opt目录,将scala安装包上传到该目录
3、解压scala安装包到指定目录
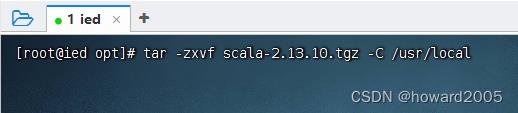
- 执行命令:
tar -zxvf scala-2.13.10.tgz -C /usr/local
(三)配置Scala环境变量
- 执行命令:
vim /etc/profile
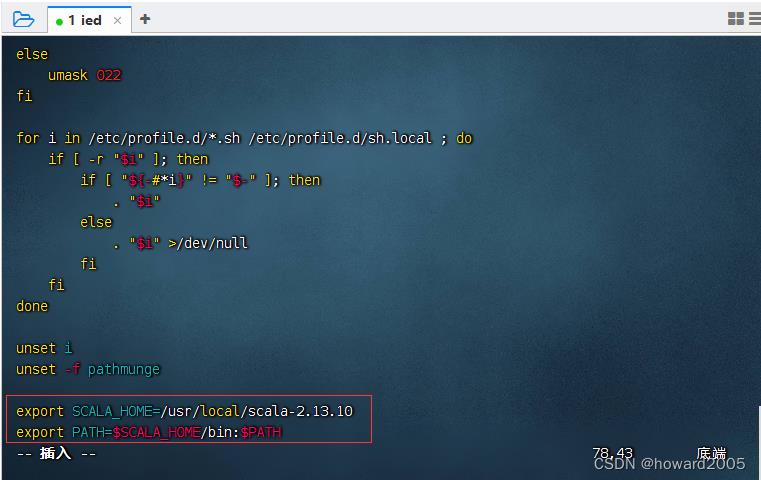
export SCALA_HOME=/usr/local/scala-2.13.10
export PATH=$SCALA_HOME/bin:$PATH
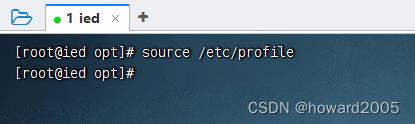
- 存盘退出后,执行命令:
source /etc/profile,让环境配置生效
(四)测试Scala是否安装成功
1、查看Scala版本
- 执行
scala -version命令,若能正确输出当前Scala版本信息,则说明安装成功
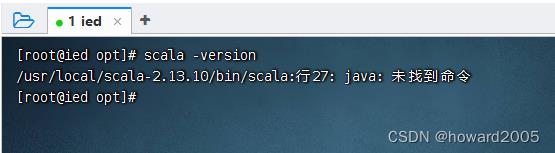
- 报错,原因在于没有安装JDK(运行Scala要用到Java虚拟机)
- 上传、安装、配置JDK



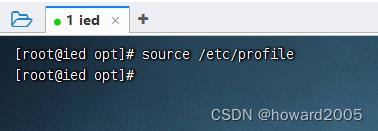
- 配置好JDK之后,查看Scala版本

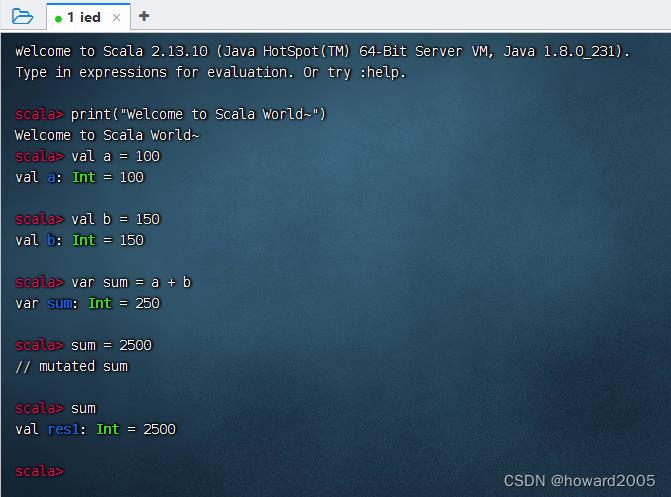
2、启动Scala,执行语句
-
在命令行提示后输入
scala,则会进入Scala的命令行模式,在此可以编写Scala表达式和程序
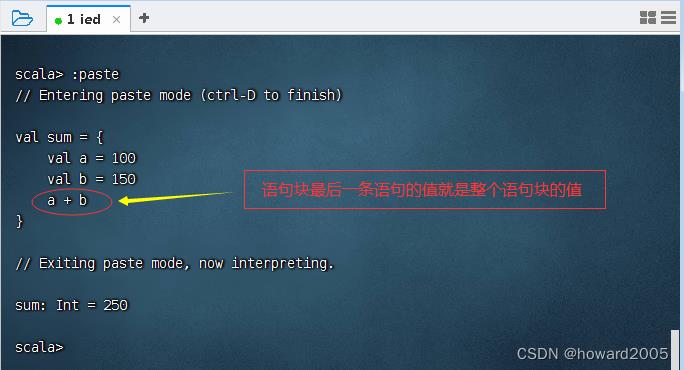
-
演示语句块的返回值
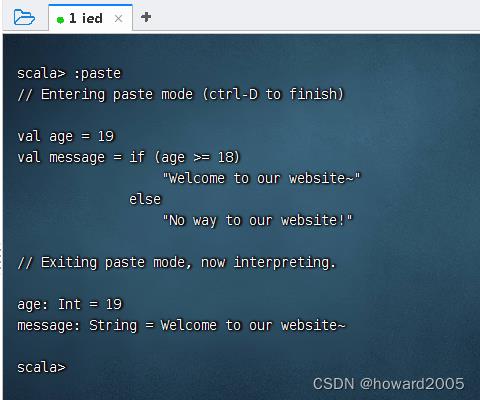
-
演示if结构的返回值
五、Scala的使用
- Scala可以在
交互模式和编译模式两种方式下运行
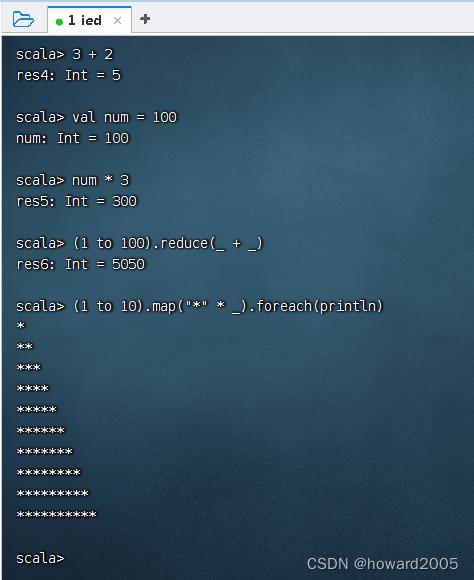
(一)交互模式
- 在命令行下直接敲命令或通过命令直接执行程序文件
1、命令行方式
- 直接在
scala>提示符后敲代码执行
- 在
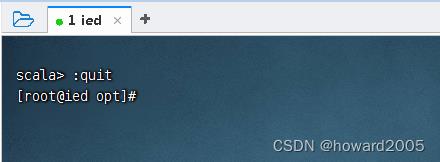
scala>提示符之后输入:quit,退出scala交互模式
2、文件方式
- 将代码写在
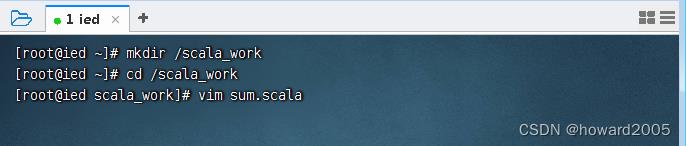
xxx.scala文件中,通过scala xxx.scala执行文件中的代码 - 创建
/scala_work目录,进入该目录,执行命令:vim sum.scala

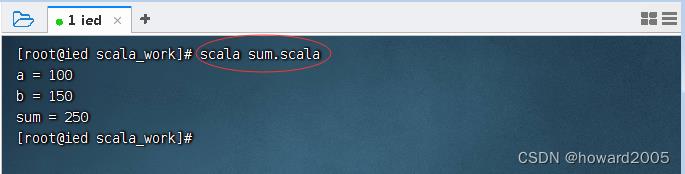
- 执行命令:
scala sum.scala
(二)编译模式
- 将代码写在
.scala文件中,通过编译命令将.scala编译为.class,然后去解释执行。在.scala文件中编写好代码,创建对象,包含入口函数。通过scalac或fsc命令进行编译,产生对应的.class文件。再通过scala命令来解释执行对象。scalac和fsc都可以进行编译工作,区别是fsc会启动后台服务常驻系统后台,这样后续再进行编译的时候,速度就可以很快。
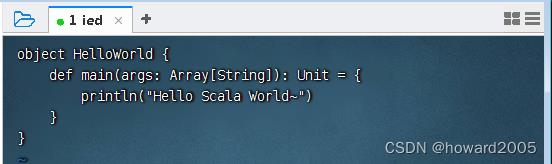
1、创建源程序
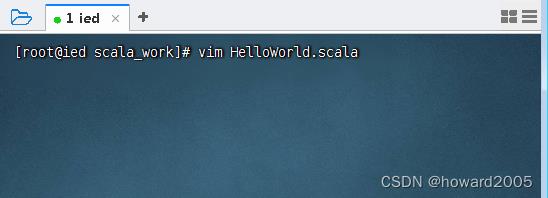
- 在
\\scala_work目录里创建文件HelloWorld.scala
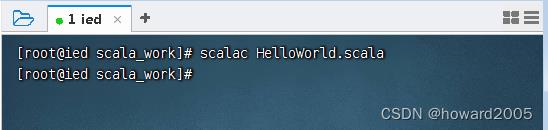
2、编译成字节码
- 利用
scalac将HelloWorld.scala编译成字节码文件HelloWorld.class
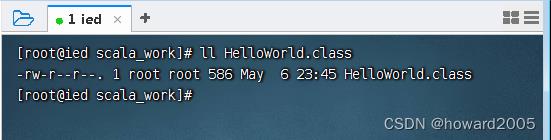
- 查看生成的同名字节码文件
3、解释执行对象
- 执行命令:
scala HelloWorld,运行程序,查看结果

六、课后作业
任务1、在你的笔记本上安装Windows版的Scala
任务2、在你的私有云虚拟机上安装Linux版的Scala
任务3、练习命令行模式与编译模式运行Scala
以上是关于大数据处理学习笔记1.1 搭建Scala开发环境的主要内容,如果未能解决你的问题,请参考以下文章