Hadoop工作原理
Posted Xiayebuliang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop工作原理相关的知识,希望对你有一定的参考价值。
目录
一、hadoop三大核心组件
- HDFS(Hadoop Distribute File System):hadoop的数据存储工具。
- YARN(Yet Another Resource Negotiator,另一种资源协调者):Hadoop 的资源管理器。
- Hadoop MapReduce:分布式计算框架
二、HDFS文件系统的读写原理
在HDFS中,关键的三大角色为:NameNode(命名节点)、DataNode(数据节点)、Client(客户端)
2.1、 HDFS架构
HDFS采用Master/slave架构模式,1一个Master(NameNode/NN) 带 N个Slaves(DataNode/DN)。
从内部来看,数据块存放在DataNode上。
NameNode :执行文件系统的命名空间,如打开、关闭、重命名文件或目录等,也负责数据块到具体DataNode的映射。
DataNode :负责处理文件系统客户端的文件读写,并在NameNode的统一调度下进行数据库的创建、删除和复制工作。
NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode。
NN:
1)负责客户端请求的响应
2)负责元数据(文件的名称、副本系数、Block存放的DN)的管理
DN:
1)存储用户的文件对应的数据块(Block)
2)要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况
2.2、HDFS写入过程:
- 客户端Client向远程的Namenode发起RPC请求
- Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件创建一个记录, 否则会让客户端抛出异常;
- 当客户端开始写入文件的时候, 客户端会将文件切分成多个packets, 并在内部以数据队列“data queue( 数据队列) ”的形式管理这些packets, 并向Namenode申请blocks, 获取用来存储replications的合适的datanode列表, 列表的大小根据Namenode中replication的设定而定;
- 开始以pipeline( 管道) 的形式将packet写入所有的replications中。 客户端把packet以流的方式写入第一个datanode, 该datanode把该packet存储之后, 再将其传递给在此pipeline中的下一个datanode, 直到最后一个datanode, 这种写数据的方式呈流水线的形式。
- 最后一个datanode成功存储之后会返回一个ack packet( 确认队列) , 在pipeline里传递至客户端, 在客户端的开发库内部维护着”ack queue”, 成功收到datanode返回的ack packet后会从”ack queue”移除相应的packet。
- 如果传输过程中, 有某个datanode出现了故障, 那么当前的pipeline会被关闭, 出现故障的datanode会从当前的pipeline中移除, 剩余的block会继续剩下的datanode中继续以pipeline的形式传输, 同时Namenode会分配一个新的datanode, 保持replications设定的数量。
- 客户端完成数据的写入后, 会对数据流调用close()方法, 关闭数据流;
- 只要写入了dfs.replication.min的副本数( 默认为1),写操作就会成功, 并且这个块可以在集群中异步复制, 直到达到其目标复本数(replication的默认值为3),因为namenode已经知道文件由哪些块组成, 所以它在返回成功前只需要等待数据块进行最小量的复制。

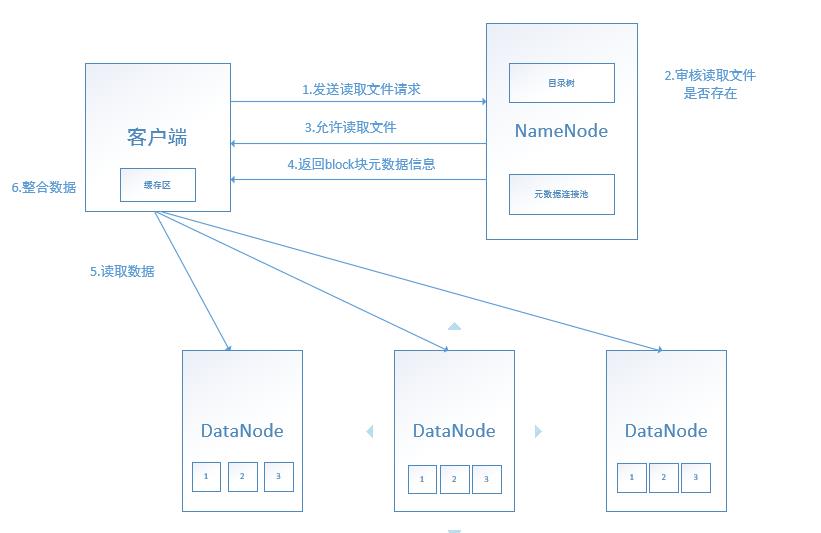
2.3、HDFS读取过程
- 使用HDFS提供的客户端Client, 向远程的Namenode发起RPC请求;
- Namenode会视情况返回文件的部分或者全部block列表, 对于每个block, Namenode都会返回有该block拷贝的DataNode地址;
- 客户端Client会选取离客户端最近的DataNode来读取block; 如果客户端本身就是DataNode, 那么将从本地直接获取数据;
- 读取完当前block的数据后, 关闭当前的DataNode链接, 并为读取下一个block寻找最佳的DataNode;
- 当读完列表block后, 且文件读取还没有结束, 客户端会继续向Namenode获取下一批的block列表;
- 读取完一个block都会进行checksum验证, 如果读取datanode时出现错误, 客户端会通知Namenode, 然后再从下一个拥有该block拷贝的datanode继续读。
hdfs的组成
1:Client:就是客户端。
a:文件切分文件上传 HDFS 的时候,Client 将文件切分成一个个的Block,然后进行存储。
b:与 NameNode 交互,获取文件的位置信息。
c:与 DataNode 交互,读取或者写入数据。
d:Client 提供一些命令来管理 和访问HDFS(hdfs dfs -put a.txt /)
2:NameNode:就是 master,它是一个主管、管理者。
a:管理 HDFS 的名称空间,对外提供一个统一的访问路径
b:管理数据块(Block)映射信息,告诉客户端,一个文件的每一个切片(block)所在的位置
c:配置副本策略,每个副本存放在哪台主机
d:处理客户端读写请求
3:DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
a:存储实际的数据块。
b:执行数据块的读/写操作
c:不断的向namenode发送心跳包和汇报自己的block信息
4:Secondary NameNode
a:对namenode做辅助性的操作,不能替代namenode
b:SecondaryNameNode可以定期的将fsimage文件和edits文件进行合并,合并一个新的fsimage,并且
替换原来的fsimage,减轻namenode的压力
合并的触发条件
1: 时间 一个小时
2: 文件大小 edits文件达到64M三、mapreduce工作原理
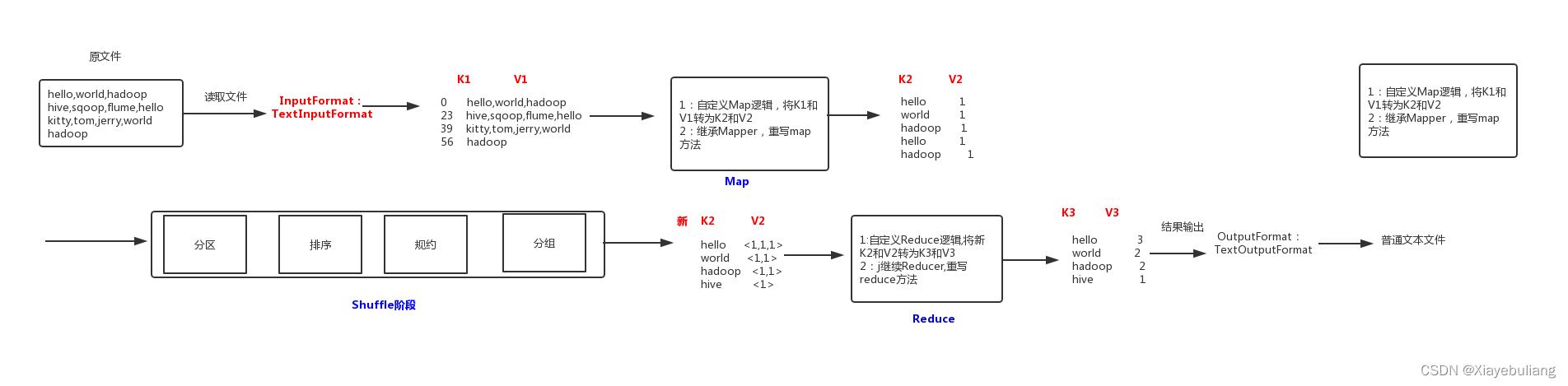
MapRecuce工作原理:
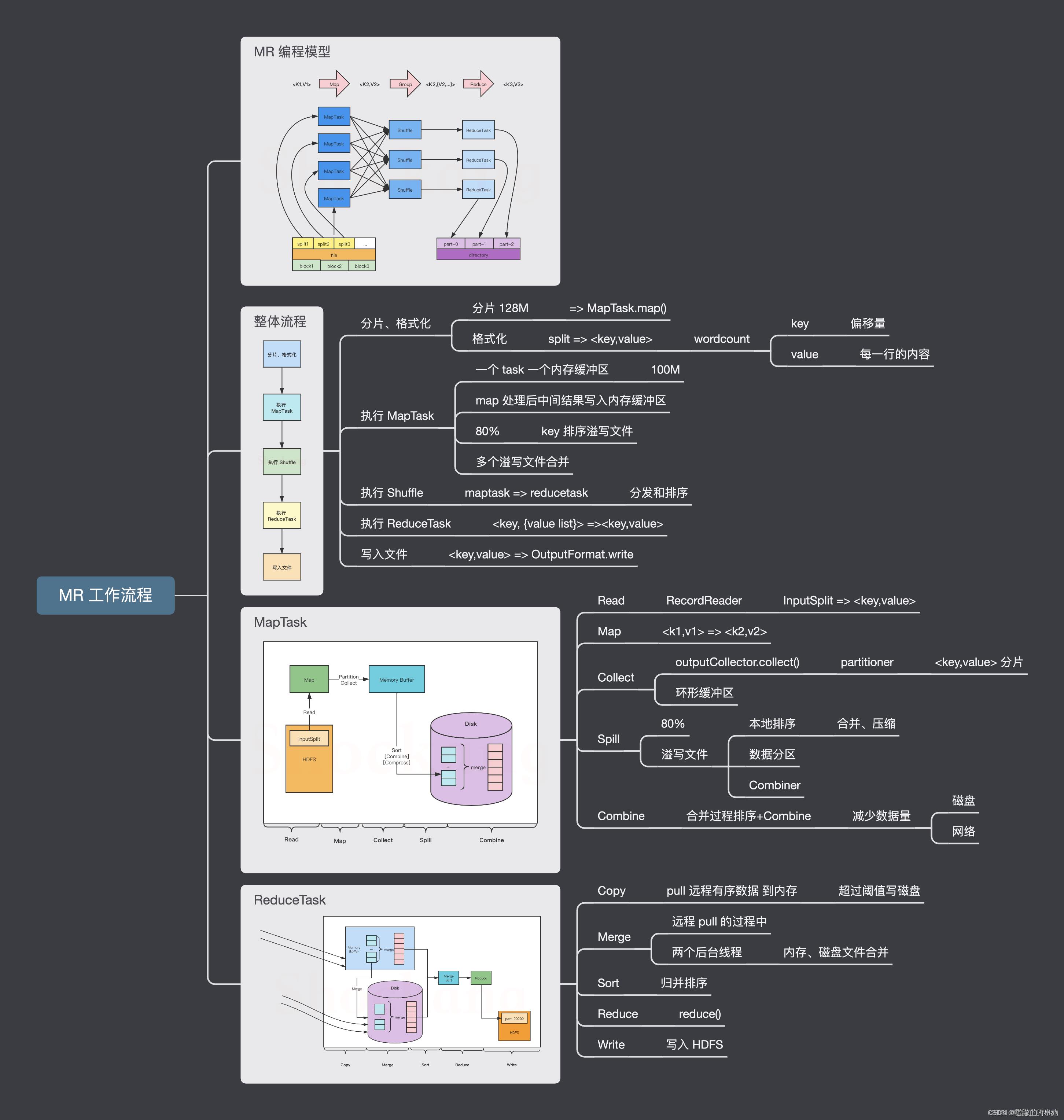
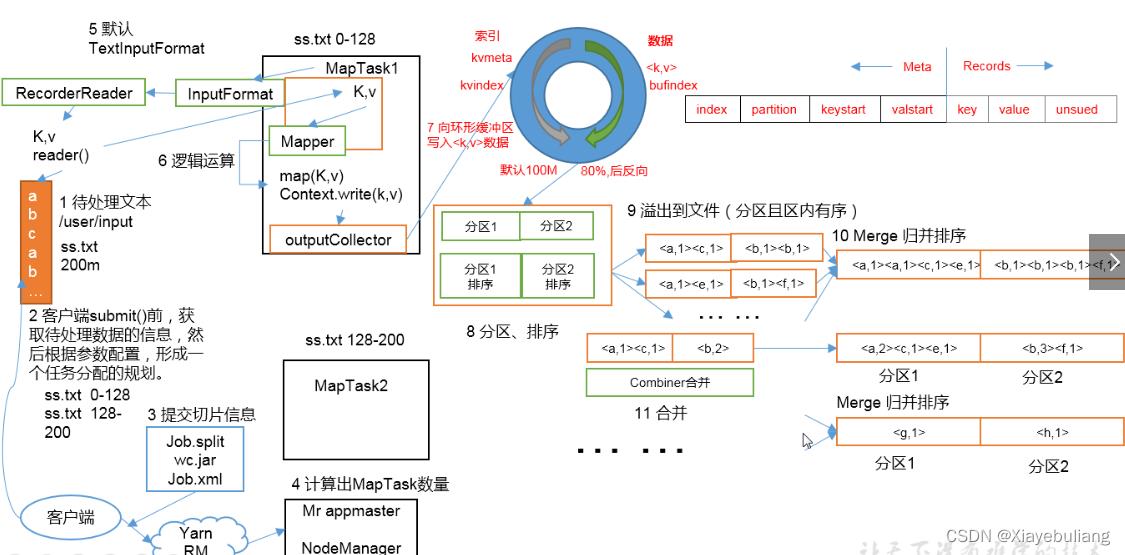
1、分片操作:FileInputstream,首先要计算切片大小,FileInputstream是一个抽象类,继承InputFormat接口,真正完成工作的是它的实现类,默认为是TextInputFormat,TextInputFormat是读取文件的,默认为一行一行读取,将输入文件切分为逻辑上的多个input split,input split是MapReduce对文件进行处理和运算的输入单位,只是一个逻辑概念,在进行Map计算之前,MapReduce会根据输入文件计算的切片数开启map任务,一个输入切片对应一个maptask,输入分片存储的并非数据本身,而是一个分片长度和一个记录数据位置的集合,每个input spilt中存储着该分片的数据信息如:文件块信息、起始位置、数据长度、所在节点列表等,并不是对文件实际分割成多个小文件,输入切片大小往往与hdfs的block关系密切,默认一个切片对应一个block,大小为128M;注意:尽管我们可以使用默认块大小或自定义的方式来定义分片的大小,但一个文件的大小,如果是在切片大小的1.1倍以内,仍作为一个片存储,而不会将那多出来的0.1单独分片。
2、数据格式化操作:
TextInputFormat 会创建RecordReader去读取数据,通过getCurrentkey,getCurrentvalue,nextkey,value等方法来读取,读取结果会形成key,value形式返回给maptask,key为偏移量,value为每一行的内容,此操作的作用为在分片中每读取一条记录就调用一次map方法,反复这一过程直到将整个分片读取完毕。
3、map阶段操作:
此阶段就是程序员通过需求偏写了map函数,将数据格式化的<K,V>键值对通过Mapper的map()方法逻辑处理,形成新的<k,v>键值对,通过Context.write输出到OutPutCollector收集器
map端的shuffle(数据混洗)过程:溢写(分区,排序,合并,归并)
溢写:由map处理的结果并不会直接写入磁盘,而是会在内存中开启一个环形内存缓冲区,先将map结果写入缓冲区,这个缓冲区默认大小为100M,并且在配置文件里为这个缓冲区设了一个阀值,默认为0.8,同时map还会为输出操作启动一个守护线程,如果缓冲区内存达到了阀值0.8,这个线程会将内容写入到磁盘上,这个过程叫作spill(溢写)。
分区Partition
当数据写入内存时,决定数据由哪个Reduce处理,从而需要分区,默认分区方式采用hash函数对key进行哈布后再用Reduce任务数量进行取模,表示为hash(key)modR,这样就可以把map输出结果均匀分配给Reduce任务处理,Partition与Reduce是一一对应关系,类似于一个分片对应一个map task,最终形成的形式为(分区号,key,value)
排序Sort:
在溢出的数据写入磁盘前,会对数据按照key进行排序,默认采用快速排序,第一关键字为分区号,第二关键字为key。
合并combiner:
程序员可选是否合并,数据合并,在Reduce计算前对相同的key数据、value值合并,减少输出量,如(“a”,1)(“a”,1)合并之后(“a”,2)
归并menge
每块溢写会成一个溢写文件,这些溢写文件最终需要被归并为一个大文件,生成key对应的value-list,会进行归并排序<"a",1><"a",1>归并后<"a",<1,1>>。
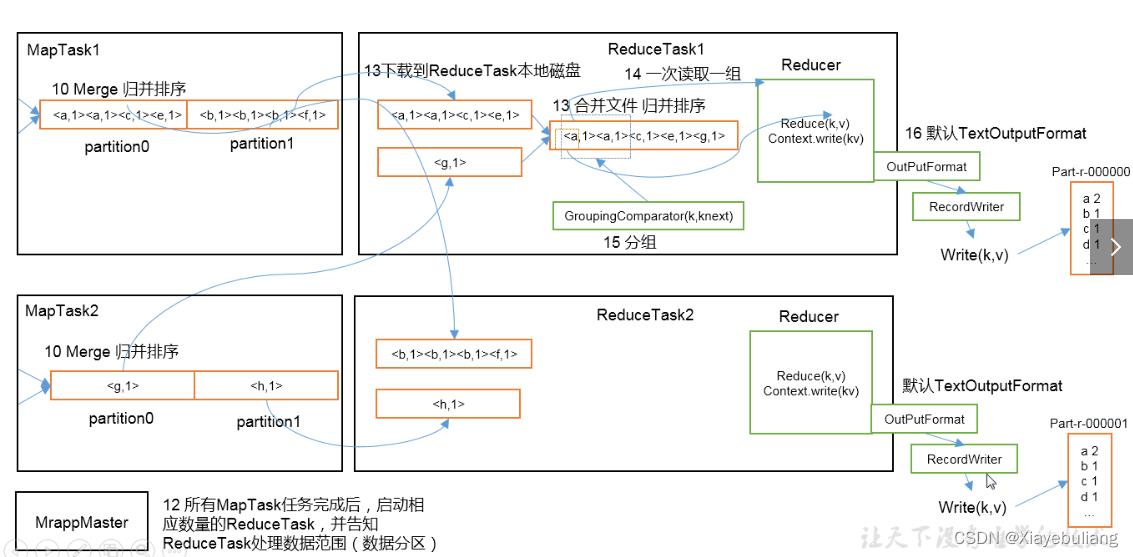
Reduce 端的shffle:
数据copy:map端的shffle结束后,所有map的输出结果都会保存在map节点的本地磁盘上,文件都经过分区,不同的分区会被copy到不同的Recuce任务并进行并行处理,每个Reduce任务会不断通过RPC向JobTracker询问map任务是否完成,JobTracker检测到map位务完成后,就会通过相关Reduce任务去aopy拉取数据,Recluce收到通知就会从Map任务节点Copy自己分区的数据此过程一般是Reduce任务采用写个线程从不同map节点拉取
归并数据:
Map端接取的数据会被存放到 Reduce端的缓存中,如果缓存被占满,就会溢写到磁盘上,缓存数据来自不同的Map节点,会存在很多合并的键值对,当溢写启动时,相同的keg会被归并,最终各个溢写文件会被归并为一个大类件归并时会进行排序,磁盘中多个溢写文许归并为一个大文许可能需要多次归并,一次归并溢写文件默认为10个,
Reduce阶段:Reduce任务会执行Reduce函数中定义的各种映射,输出结果存在分布式文件系统中。
四、HDFS操作命令
HDFS命令
hdfs dfs -ls /
hdfs dfs -put a.txt / #将文件复制到hdfshdfs dfs -put /root/a.txt /root/
hdfs dfs -mkdir /dir1
hdfs dfs -mkdir -p /dir1/dir11 #递归创建文件夹
hdfs dfs -moveFromLocal a.txt /dir1/dir11 #将文件移动到hdfshdfs dfs -get /a.txt ./ #将文件下载到当前目录
hdfs dfs -mv /dir1/a.txt /dir2 #将hdfs的文件移动到hdfs的另外一个路径
hdfs dfs -rm /a.txt #删除一个文件(删除文件之后移动到hdfs的垃圾桶,七天之后自动删除)
hdfs dfs -rm -r /dir1 #递归删除一个文件夹(删除文件之后移动到hdfs的垃圾桶)
hdfs dfs -cp -p /dir1/a.txt /dir2/b.txt #将hdfs的某个文件拷贝到hdfs的另外一个路径(深度拷贝)
hdfs dfs -cat /a.txt #查看hdfs文件的内容
hdfs dfs -chmod -R 777 / #修改hdfs文件或者文件夹(加-R参数)权限
hdfs dfs -appendToFile a.xml b.xml /big.xml #将linux本地的文件合并之后上传到hdfs
以上是关于Hadoop工作原理的主要内容,如果未能解决你的问题,请参考以下文章