RabbitMQ-高级
Posted 啵萝蜜多斩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RabbitMQ-高级相关的知识,希望对你有一定的参考价值。
消息队列 MQ 使用时 存在的问题:
消息可靠性(如何确保发送的消息至少被消费一次)
延迟消息(如何实现消息的延迟投递)
高可用问题(如何避免单点的MQ故障而导致的不可用问题)
消息堆积问题(如何解决百万消息堆积,无法及时消费的问题)
消息可靠性的原因及解决方案
原因:
消息发送时丢失
生产者发送的消息未送达交换机
交换机的消息未送达队列
MQ 服务宕机,队列中的消息丢失
消费者接收到消息后还没来得及消费,MQ就宕机了
解决方案:
生产者确认机制 (publisher confirm)
publisher confirm 机制必须给每个消息这是一个全局唯一ID,消息发送到MQ之后,会返回一个结果给publisher,表示是否成功
返回结果的两种方式:
1, publisher-confirm,发送者确认
消息成功发送给交换机,返回 ack
消息未发送到交换机,返回 nack
2, publisher-return 发送者回执
消息发送到交换机了,但是没有路由给队列,返回 ack,以及路由失败的原因
项目中,配置 发送者 的application.yml
spring:
rabbitmq:
publisher-confirm-type: correlated
publisher-returns: true
template:
mandatory: true配置说明:
publisher-confirm-type: 开启 publisher-confirm,有两种类型
①,simple :同步等待 confirm 结果,直到超时
②,correlated :异步回调,定义ConfirmCallback ,MQ 返回结果是,会回调这个 ConfirmCallback
publish-returns:开启 publish-return ,基于回调机制,定义ReturnCallback
template.mandatory:定义消息路由失败的策略,
①,true:调用 ReturnCallback
②,false:直接丢弃消息
MQ 持久化
消息发送到队列后,如果MQ突然宕机,也可能导致消息丢失,所以为确保消息安全保存,需开启持久化机制,(三种持久化机制都开启之后,才能保证消息的完整安全性)
交换机持久化
RebbitMQ 中的交换机默认不持久,重启之后就会丢失
SpringAMQP 中声明的交换机 默认是 持久化的
队列持久化
RebbitMQ 中的队列默认不持久,重启之后就会丢失
SpringAMQP 中声明的队列 默认是 持久化的
消息持久化
SpringAMQP 发送的任何消息 默认是 持久化的
消费者确认机制
RebbitMQ 消息是阅后即焚机制,MQ 确认消息被消费者消费后会立刻删除,所以MQ也可以通过获取消费者返回的 ACK 来确认消费者是否已经处理消息
SpringAMQP 提供了三种确认模式
manual : 手动ACK,根据业务情况,调用 API 发送 ACK
auto : 自动 ACK ,由Spring 检测 istener 代码是否出现异常,无异常返回ACK ,有异常则返回 NACK
none : 关闭ACK ,MQ 认为消息每次都成功 处理,因此消息投递之后,立即被删除
一般情况下,使用 auto 就可以了
在 消费者 服务 的application.yml 中配置
spring:
rabbitmq:
listener:
simple:
acknowledge-mode: none / manual / auto # 模式失败重试机制
问题 : 当消费者出现异常后,消息会不断requeue(重入队)到队列,再重新发送给消费者,然后再次异常,再次requeue,无限循环,导致mq的消息处理飙升,带来不必要的压力
解决:
本地调试(基于Spring Retry 机制),
在消费者服务 的 application.yml配置
spring:
rabbitmq:
listener:
simple:
retry:
enabled: true # 开启消费者失败重试
initial-interval: 1000 # 初识的失败等待时长为1秒
multiplier: 1 # 失败的等待时长倍数,下次等待时长 = multiplier * last-interval
max-attempts: 3 # 最大重试次数,达到最大次数后,返回ACK,丢弃消息
stateless: true # true无状态;false有状态。如果业务中包含事务,这里改为false重试失败策略:
问题:失败重试机制中,如果达到最大重试次数后,依然失败,消息就会被丢弃,无法真正保证消息可靠性,
解决: RepublishMessageRecoverer,失败的消息投递到一个指定的队列,由人工处理
@Bean
public MessageRecoverer republishMessageRecoverer(RabbitTemplate rabbitTemplate)
return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");
可靠性总结:
如何确保RabbitMQ消息的可靠性?
开启生产者确认机制,确保生产者的消息能到达队列
开启持久化功能,确保消息未消费前在队列中不会丢失
开启消费者确认机制为auto,由spring确认消息处理成功后完成ack
开启消费者失败重试机制,并设置MessageRecoverer,多次重试失败后将消息投递到异常交换机,交由人工处理
死信交换机
什么是死信?
当一个队列中的信息满足下列情况之一时,就可以称为死信(dead letter)
消费者使用basic.reject 或 basic.nack声明消费失败,并且消息的requeue 参数设置为false
消息是一个过期消息,超时无人消费
要投递的消息队列消息满了,无法投递
如果这个半酣私信的队列配置了 dead-letter-exchange 属性,指定了一个交换机,那么队列中的死信就会投递到这个交换机中,而这个交换机称之为死信交换机(dead letter exchange 简称DLX)
在失败重试策略中,默认的 RejectAndDontRequeueRecoverer 会在本地重试次数耗尽后,发送 reject 给RebbitMQ 消息变成死信, 可以给消息队列添加一个死信交换机,并绑定一个队列,用来存放死信,这样可以防止死信被丢弃
投递死信到死信交换机时,必须声明 死信交换机的名称,死信交换机与死信队列绑定的RoutingKey
死信总结
什么样的消息会成为死信?
消息被消费者reject或者返回nack
消息超时未消费
队列满了
死信交换机的使用场景是什么?
如果队列绑定了死信交换机,死信会投递到死信交换机;
可以利用死信交换机收集所有消费者处理失败的消息(死信),交由人工处理,进一步提高消息队列的可靠性。
TTL (消息超时时间)
超时未消费的消息会成为死信,超时的两种情况:
消息所在的队列设置了超时时间
消息本身设置了超时时间
消息超时的两种方式:
给队列设置 ttl 属性,进入队列后超过ttl 时间的消息变成死信
给消息设置ttl 属性,队列接收到消息超过ttl 事件后变成死信
实现发送一个消费者20秒后才能收到的消息的流程:
给消息的目标队列指定死信交换机
将消费者监听的队列绑定到死信交换机
发送消息时,给消息设置超时时间为20 秒
延迟队列 ( Delay Queue)
对消息设置 ttl 属性,并结合死信交换机,实现了消息延迟发送,这种消息模式称为延迟队列模式
常见的场景:
延迟发送短信,
用户下单,如果用户在指定时间内欸支付,则自动取消
预约工作会议,指定时间后自动通知所有参会人员
DelayExchange (延迟消息插件 )
DelayExchange 需要将一个交换机 声明为 delayed 类型,当我们发送消息到delayExchange 时,
流程:
接收消息
判断消息是否具有 x-delay 属性
如果有 x-delay 属性,说明是延迟消息,持久化到硬盘,读取 x-delay 值,作为延迟时间
返回 routing not found 结果给消息发送者
x-delay 时间到期后,重新投递消息到指定队列
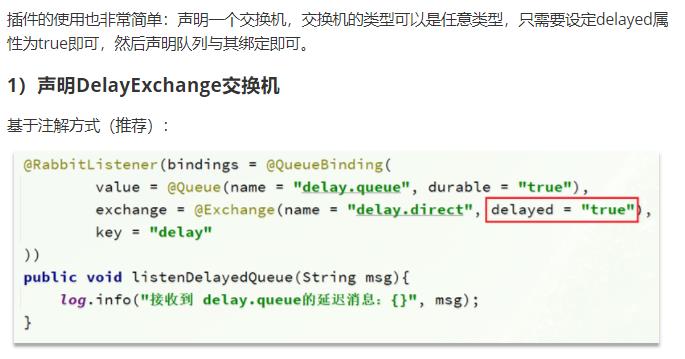
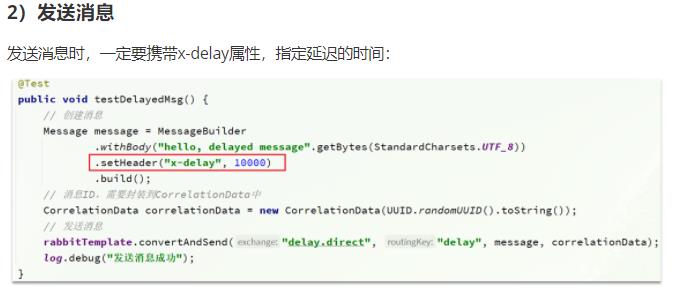
延迟队列的使用步骤:
声明一个交换机,添加 delayed 属性为true
发送消息时,添加 x-delay 头,值为 超时时间
惰性队列(lazy queue)
消息堆积:由于 消息的投递 > 消息的处理 ,导致队列存储达到上限,之后发送的消息就会成为死信,可能会被丢弃.
解决方案:
增加更多的消费者,提高消费速度,也就是 工作队列( work queue)
扩大队列的存储上限,提高消息的存储量
而提高队列的消息存储量,必然会对内存造成压力,所以开始有了 惰性队列
惰性队列 从 RabbitMQ 3.6 版本开始加入,特征如下:
接收到消息后直接存入磁盘,而不是内存
消费者要消费消息时,才会从磁盘中读取并加载到内存中,
支持数百万条的消息存储
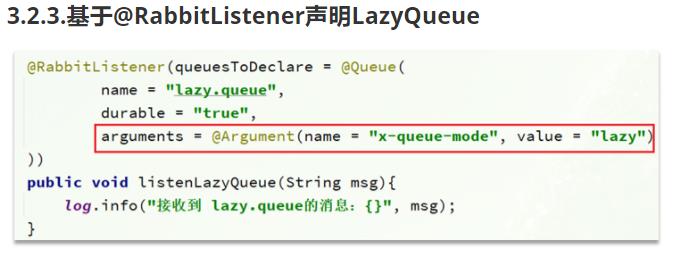
声明方式:
通过命令行的方式,将正在运行中的队列修改为惰性队列
基于@Bean 声明队列时,指定属性 lazy
惰性队列-总结
消息堆积的解决方式:
队列上绑定多个消费者,提高消费速度
使用惰性队列,可以在队列中保存更多的消息
惰性队列的优点:
基于磁盘存储,消息上限高
没有间歇性的 page-out ,性能比较稳定
缺点:
基于磁盘存储,消息的时效性会降低
性能受限于磁盘的IO
MQ 集群
基于 MQ的语种是面向并发的语言 Erlang ,其本身就支持集群模式
模式有:
普通集群
镜像集群
普通集群
这是一种分布式集群,将队列分散到集群的各个节点,从而提高整个集群的并发能力
特征:
会在集群的各个节点之间共享部分数据,包括交换机,队列辕信息,不包含队列中的消息
当访问集群某节点时,如果队列不再该节点,会从数据所在节点传递到当前节点并返回
队列所在的节点宕机,队列中的消息就会丢失
镜像集群
基于主从模式
特征:
交换机,队列,队列中的消息会在各个MQ的镜像节点之间同步备份
创建队列的节点被称为该队列的主节点,备份到的其他节点叫做该系列的镜像节点
一个队列的主节点可能是另一个队列的镜像节点
所有操作都是主节点完成,然后同步给镜像节点
主机宕机后,镜像节点hi代替成心的主节点
仲裁队列
3.8版本之后加入,用以代替镜像队列,
特征:
与镜像队列一样,基于主从模式,支持主从数据同步
使用简单,没有复杂的配置
主从同步基于 Raft 协议,强一致

消息幂等性
幂等性:同一个消息被消费一次 或 多次,结果一样
消息可能会被重复消费,所以我们要解决消息幂等性的问题
消息重复消费是怎样产生的:

1,发送端MQ-client将消息发送给服务端MQ-server
2,服务端MQ-server 将消息存入内存
3,服务端MQ-server返回ACK给发送端MQ-client
4,服务端MQ-server将消息发给接收端 MQ-client
5,接收端MQ-client返回ACK给服务端
6,服务端MQ-server将消费的消息删除
如果第3步,和第5步,出现了问题,导致接收者(MQ-server)没有收到ACK
那么第3步的接收者和第5步的接收者会重新发送(retry)同样的消息,导致重复消费
保证幂等性,要保证同样的消息消费一次或多次的效果一样
解决方案:
消息消费者根据消息的种类进行不同的处理
1,查询操作,天然幂等性,不需要做特殊处理
2,根据id 删除,天然幂等,不需要做特殊处理
3,
根据 id 做等值(name=张三)修改,天然幂等性,不需要特殊处理
如果时做增加或者减少的修改(库存+1,金额-100),不幂等,使用乐观锁,
发消息时携带一个版本号 version 要跟数据库里面的 version 字段值一致
做修改时根据id 和version作为条件进行修改,并且将 version +1
比如一个 id=1 version=1 的商品,需要增加2的库存,发消给商品服务,
商品服务接收到消息后,生成的sql:update goods set total=total +2,version=version+1 where version =1and id=1
4,新增
在消息生产者就生成数据的ID,然后再消费者新增之前先根据 id 去数据库中查询,如果没有则新增,如果有,则说明该消息是一个重复消息
用分布式锁:
发消息时将消息的id 存入redis
消费消息时,先去redis 查询有没有对应的 id ,如果没有则不消费,消费成功后删除 redis 中
合格消息的id
消息顺序消费
什么是消息顺序消费?
如果有一个业务场景一共有3个消息,需要按照顺序依次消费1,2,3号消息
1.消息生产者必须保证将有顺序的消息发到同一个队列
2.消息消费者必须是一个线程来消费消息
3.设置消费者每次取一个消息xiao
以上是关于RabbitMQ-高级的主要内容,如果未能解决你的问题,请参考以下文章