文本分类《融合注意力和剪裁机制的通用文本分类模型》
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本分类《融合注意力和剪裁机制的通用文本分类模型》相关的知识,希望对你有一定的参考价值。
·阅读摘要:
针对实际场景中长短文本大量的情况,提出了双通道注意力机制与长文本裁剪机制来改进文本分类模型,最终提高了精度。
·参考文献:
[1] 融合注意力和剪裁机制的通用文本分类模型
参考论文信息
论文名称:《融合注意力和剪裁机制的通用文本分类模型》
发布期刊:《计算机应用》
期刊信息:CSCD扩展

本文主要是针对数据集中长文本和短文本互相混和的情况,设计了一些改进。主要有六:
·词向量表示模块
·卷积神经网络模块
·双通道注意力模块
·长文本裁剪模块
·循环神经网络模块
·融合分类模块
其中,值得说的是双通道注意力模块与长文本裁剪模块,其他的模块都是比较基础的。
模型结构
模型结构如下:
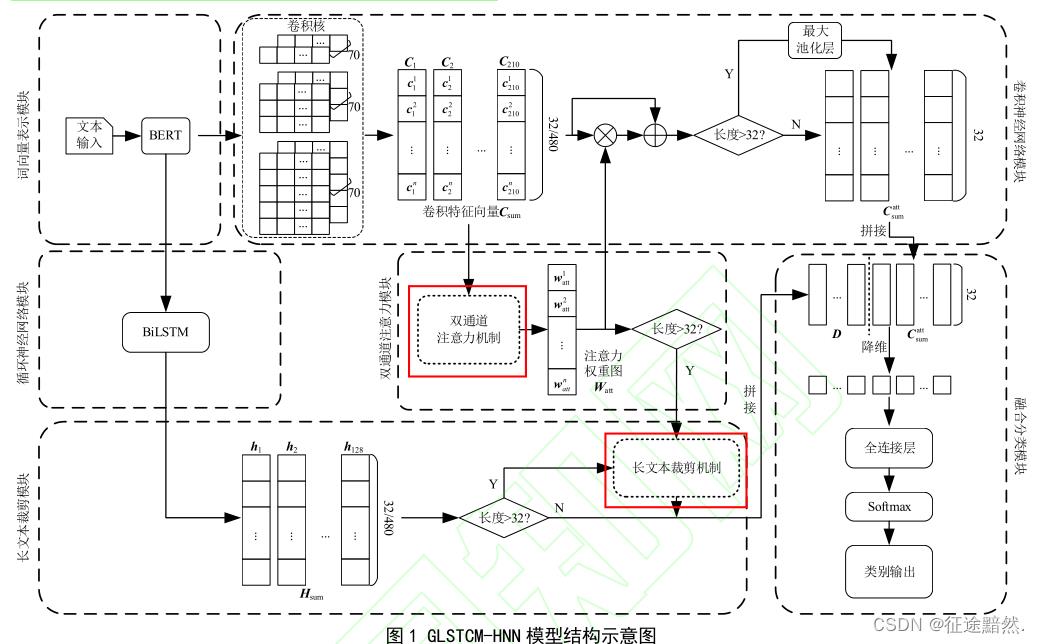
【注】:这个网络结构,我只能说是“简单的复杂”。纯把数据倒来倒去,然后拼接在一起,做个分类。它做了这么多工作,其实很有可能会产生debuff,甚至不如直接在BERT后面接个分类结果好。但是实践出真知,我持保留意见。
【注】:上面的模型除了数据倒来倒去,原理还是较为简单的,双通道注意力模块与长文本裁剪模块值得看一下。
·双通道注意力模块
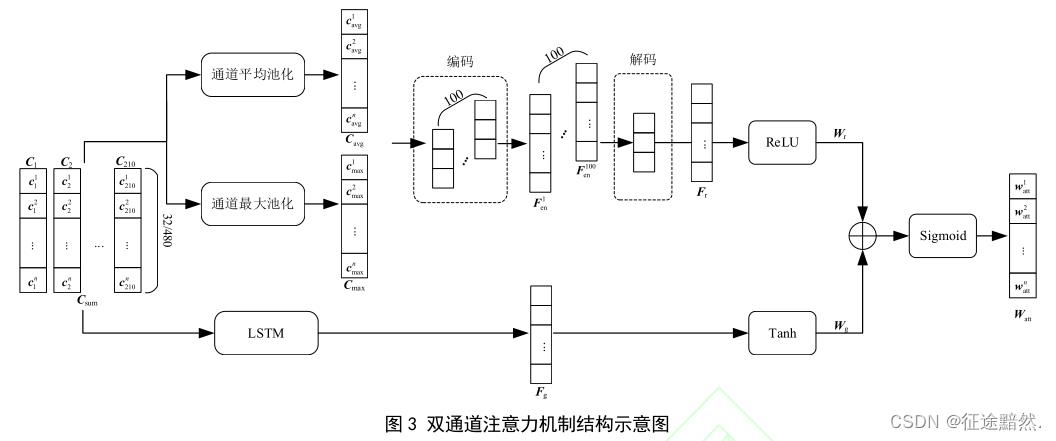
比较好理解,平均池化、最大池化、LSTM、激活、拼接……
【注】:1、我感觉“注意力”这个词,已经被用的完全背离它原始的定义了,现在什么都叫注意力;2、再说一次,步骤搞的这么多,真的不会产生负效果吗。
·长文本裁剪模块
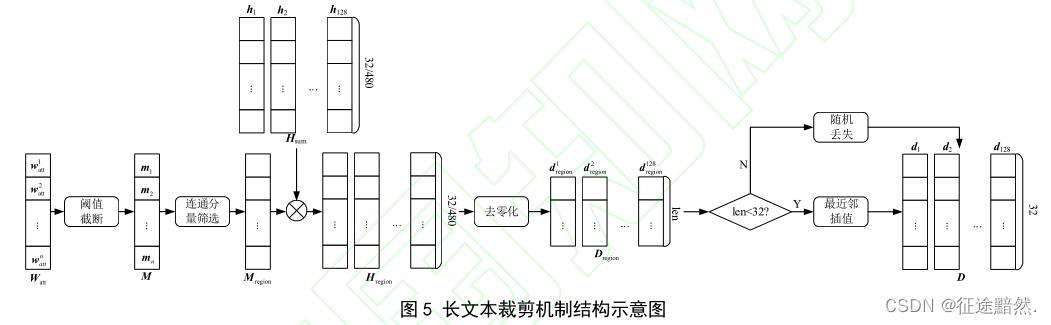
对于双通道注意力机制的输出,根据一定的阈值,把它们变成0-1值(二值化),这叫做阈值阶段。
连通分量筛选没看懂,如下:

最后把连通分量筛选的结果和BERT+LSTM的结果点乘,最后再结果一系列操作……
【注】:这么多乱七八糟的操作,真的不会影响文本的实际表示吗…………
以上是关于文本分类《融合注意力和剪裁机制的通用文本分类模型》的主要内容,如果未能解决你的问题,请参考以下文章