多标签文本分类《基于标签语义注意力的多标签文本分类》
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多标签文本分类《基于标签语义注意力的多标签文本分类》相关的知识,希望对你有一定的参考价值。
·阅读摘要:
为了建立标签的语义信息和文档的内容信息之间的联系并加以利用,文章提出了一种基于标签语义注意力的多标签文本分类(LAbel Semantic Attention Multi-label Classification,简称 LASA)方法。
·参考文献:
[1] 基于标签语义注意力的多标签文本分类
参考论文信息
论文名称:《基于标签语义注意力的多标签文本分类》
发布期刊:《软件学报》
期刊信息:CSCD

论文《融合注意力与CorNet的多标签文本分类》与此篇论文是同一个思路,值得参考。
模型结构
模型结构如下:
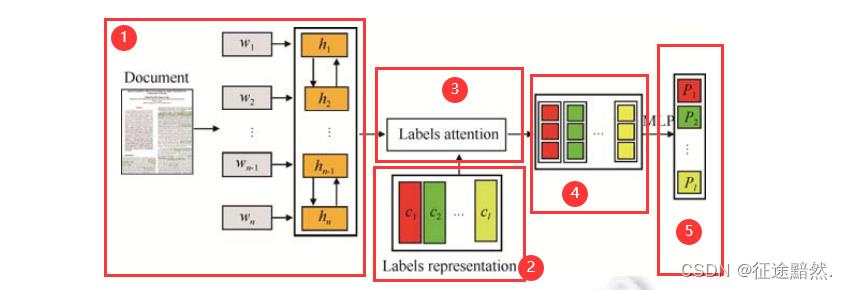
【注】:本篇论文的网络结构很简洁,论文写的也很干净利落。
1. 单词隐表示学习
这部分比较简单,对文本序列使用Bi-LSTM模型,最终得到正向与反向的文档表示向量 H → \\mathopH\\limits ^\\rightarrow H→与 H ← \\mathopH\\limits ^\\leftarrow H←。
2. 标签隐表示学习
这部分的工作是把标签转化为向量表示。文中使用的方法是,把标签中的每个词的向量表示相加取得平均。第i个标签的向量表示如下:
c i = 1 p ∑ j = 1 p w j c_i = \\frac1p\\sum_j=1^pw_j ci=p1j=1∑pwj
【例如】:某个标签为“love story”,那么这个标签的 p = 2 p=2 p=2, w 1 w_1 w1为"love", w 2 w_2 w2为"story"。然后把 w 1 w_1 w1、 w 2 w_2 w2送到Bi-LSTM模型里面得到向量,最后取平均值。
上述公式称之为:词向量平均函数。
3. 单词重要性学习
本模块的目的是,计算每个标签对某条文本中的每个词的“重要性”,即权重。
由于在“单词隐表示学习”中得到了正向与反向的文档表示向量 H → \\mathopH\\limits ^\\rightarrow H→与 H ← \\mathopH\\limits ^\\leftarrow H←。此处单词重要性权重也会有正向与反向的权重 A → \\mathopA\\limits ^\\rightarrow A→与 A ← \\mathopA\\limits ^\\leftarrow A←。其中: A → = C H → \\mathopA\\limits ^\\rightarrow=C\\mathopH\\limits ^\\rightarrow A→=CH→, A ← = C H ← \\mathopA\\limits ^\\leftarrow=C\\mathopH\\limits ^\\leftarrow A←=CH←。
得到所有标签针对当前文档中每个单词的匹配得分, 从匹配得分中可以获得文档中每个标签更关注的部分,从而更好地学习文档表示。
4. 文档表示学习
每个标签关注文档中的内容是不同的,所以本文提出为每个标签学习不同的文档表示,文档的表示是由每个单词的权重和单词的表示结合得到的,将上一层得到的单词和标签之间的匹配得分乘以每个单词的隐表示,得到每个标签对应的文档表示。
5. 标签预测
使用全连接层进行分类。
以上是关于多标签文本分类《基于标签语义注意力的多标签文本分类》的主要内容,如果未能解决你的问题,请参考以下文章