Elasticsearch 笔记 |快速使用
Posted 小鲸鱼大梦想
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 笔记 |快速使用相关的知识,希望对你有一定的参考价值。
文章目录
Elasticsearch 快速安装
-
Elasticsearch 基于 Java 语言开发的,需要安装 JDK环境,Elasticsearch 7要求安装 JDK1.8以上版本。
-
支持安装的平台:Linux、Windows操作系统,支持使用 Docker直接启动,一般可以直接使用官方提供的免安装压缩包(ZIP和tar.gz文件包),直接解压就可完成安装,官网还提供了 Linux 下的 DEB 和 RPM 安装包,以及windows下的MSI安装包。
-
支持历史版本下载
-
官网下载地址:https://www.elastic.co/cn/downloads/elasticsearch
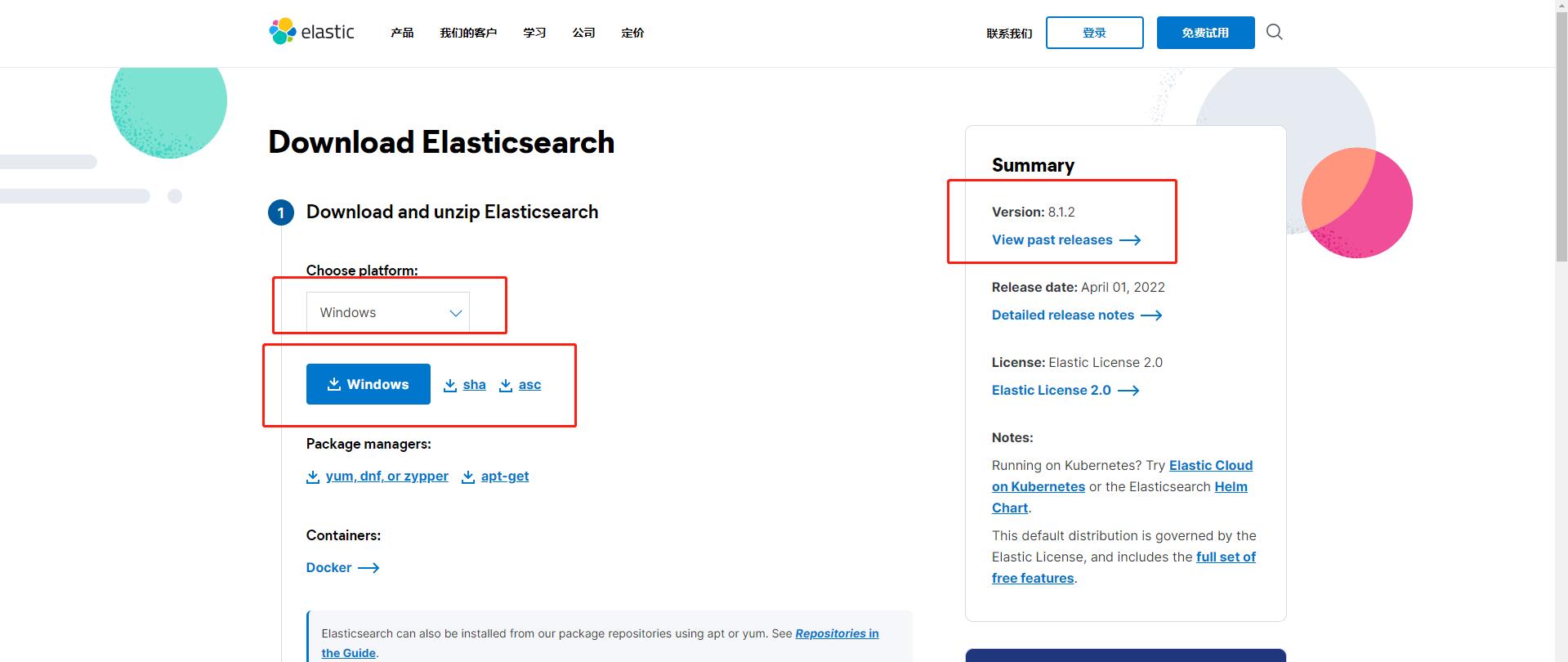
安装启动
官网下载对应版本的软件包:https://www.elastic.co/cn/downloads/elasticsearch;如果要下载历史版本,页面右侧可提供下载
下载版本:8.1.2
Linux环境:centos 7.9
下载地址:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.1.2-linux-x86_64.tar.gz

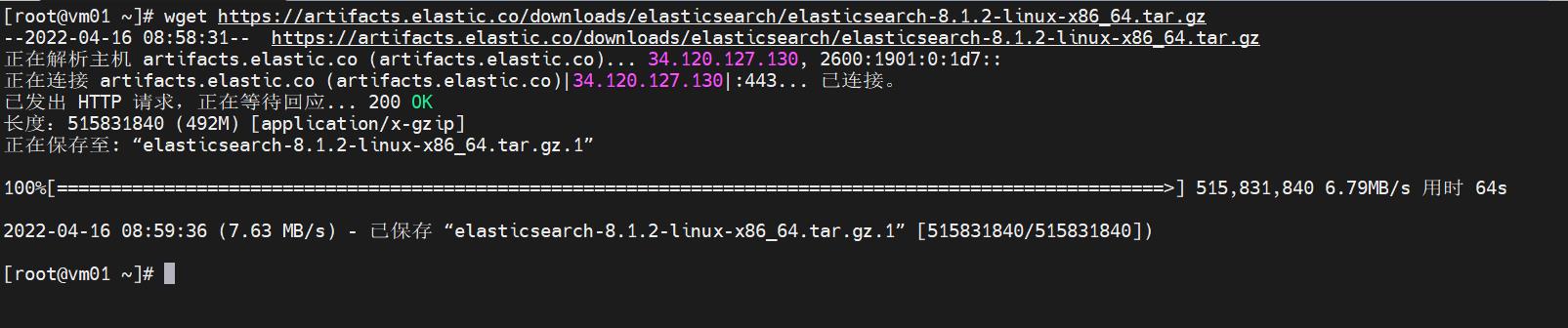
- 下载安装包:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.1.2-linux-x86_64.tar.gz
- 解压安装包:
# 把软件包放在/usr/local/路径下,不过放哪里都无所谓的
mv elasticsearch-8.1.2-linux-x86_64.tar.gz /usr/local/
# 解压软件包
tar -xf elasticsearch-8.1.2-linux-x86_64.tar.gz

- 创建elasticsearch用户:不可以以root用户启动
# root用户下执行
# 创建用户 es
useradd es
# 授权
chown -R es elasticsearch-8.1.2

- 重要的目录结构
bin:存放执行文件,例如启动脚本、密钥工具等。
config:Elasticsearch所有的配置文件都在这个目录下。
logs:默认的日志存放位置,实际中一般需要自行更改。
data:默认的索引数据存储位置,运行后自动生成此文件夹,实际中一般需要自行更改。
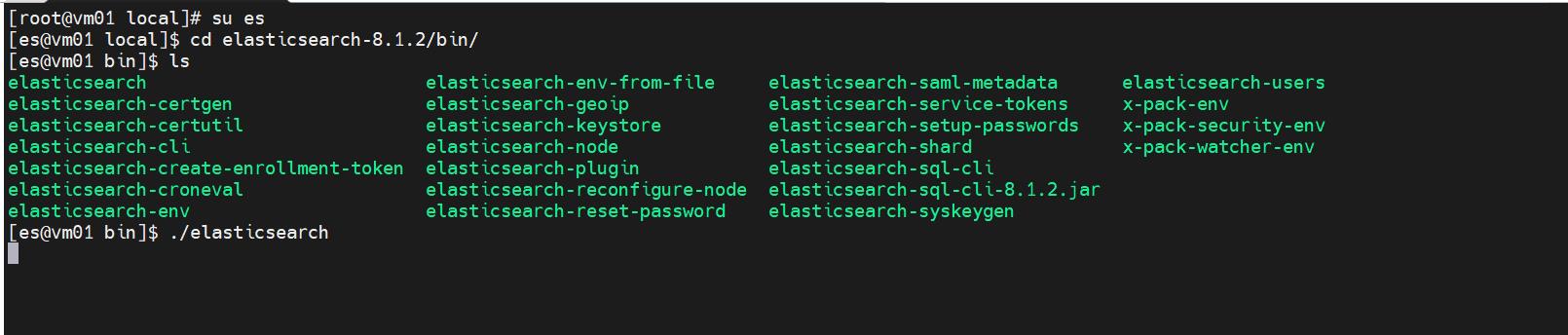
- 切换用户后运行
# 切换到es用户
su es
# 进入/bin运行程序
cd elasticsearch-8.1.2/bin/
./elasticsearch
# 也可后台以守护进程方式运行
./elasticsearch -d
- 查看输出日志
# 进入logs
cd logs
# 实时查看启动日志
tail -f elasticsearch.log
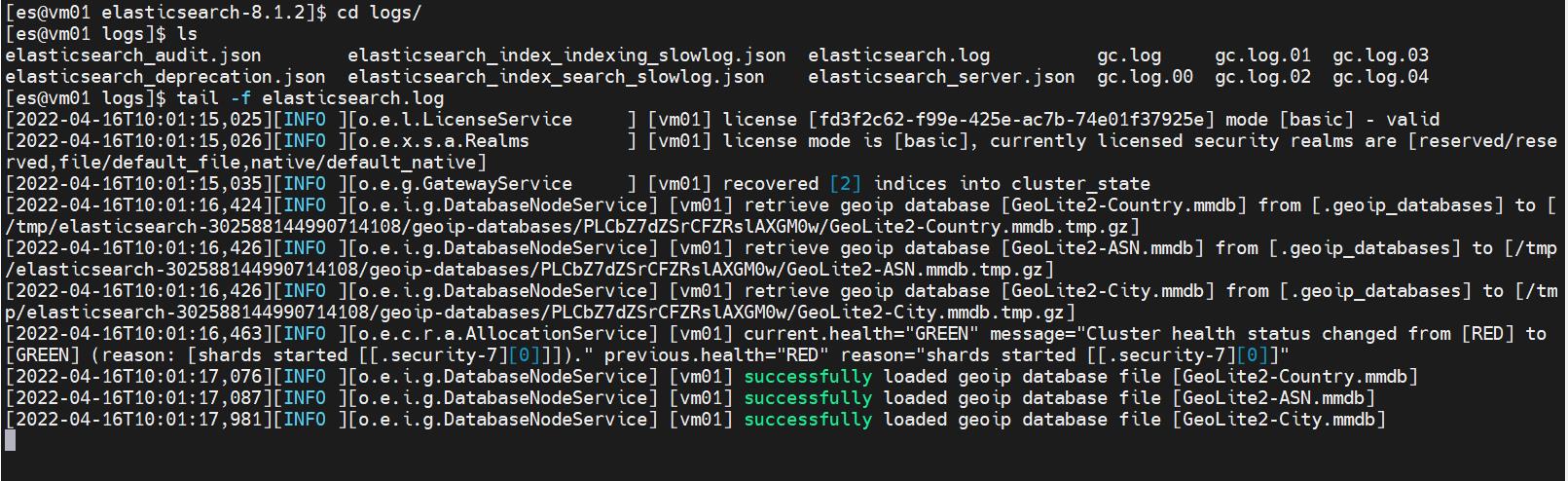
问题踩坑
- 日志输出:received plaintext http traffic on an https channel, closing connection Netty4HttpChannel
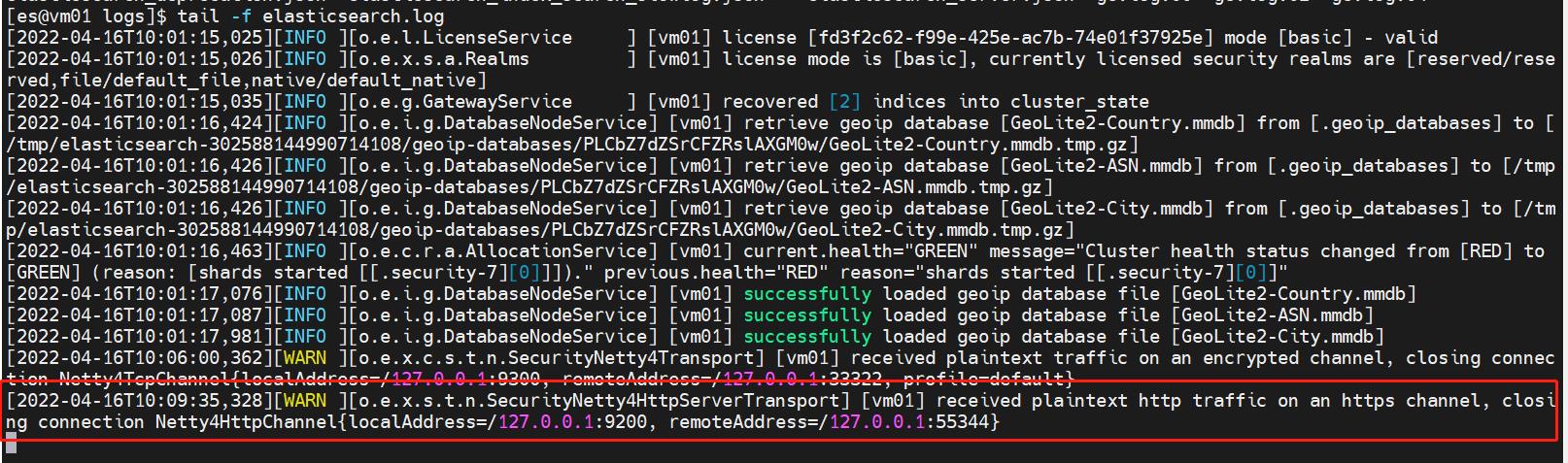
解决办法:开启了SSL认证,需要将此配置关闭
修改elasticsearch.yml 文件配置,将xpack.security.http.ssl:enabled值设置成false后重新启动

- 访问9200端口需要输入账号密码
解决办法:elasticsearch内置了一些用户和角色,用以提供认证功能,默认情况下这些用户是没有设置密码的,在设置密码前无法访问,既然无法访问,我们就关闭吧。修改elasticsearch.yml 文件配置,将xpack.security.enabled值设置成false后重新启动。

再次访问一下验证就OK了,
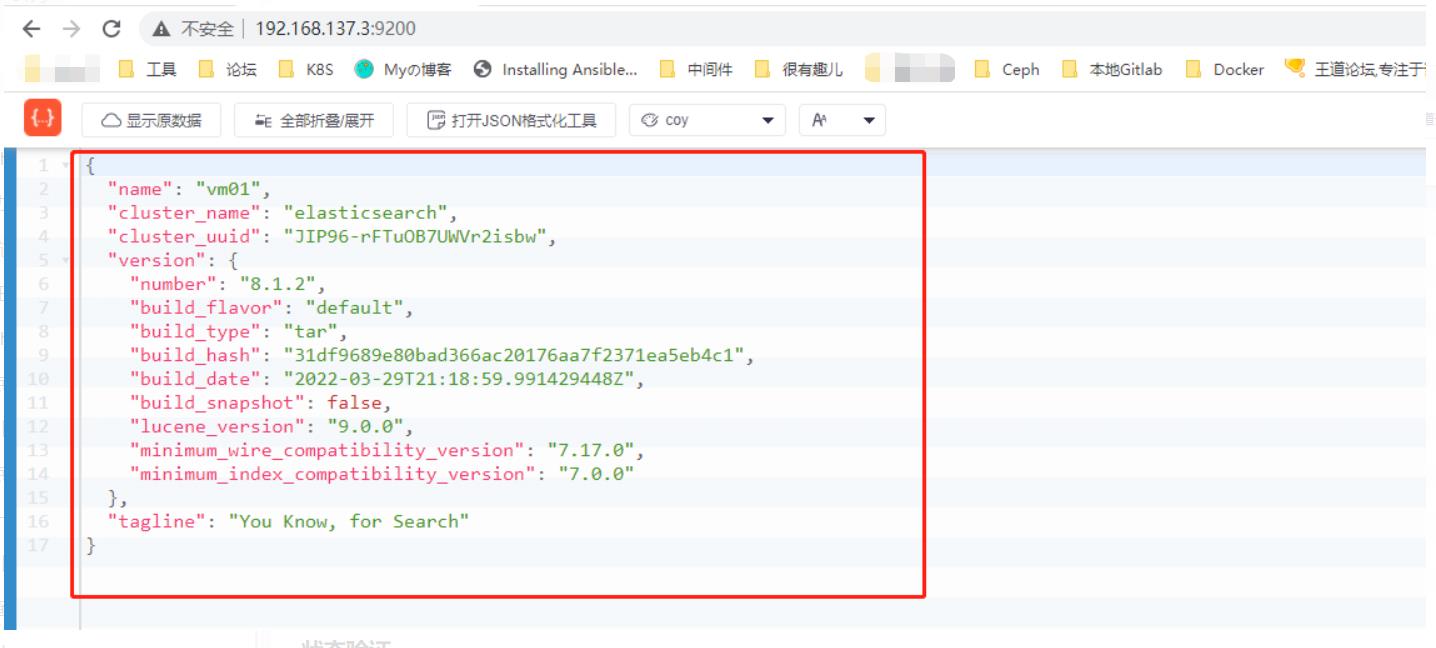
状态验证
得益于Elasticsearch强大的REST API,可以使用它与集群进行交互,
命令行键入:curl -X GET "http://localhost:9200/_cat/health?v"
- 检查集群、节点和索引 的运行状况、状态和统计信息
- 管理集群、节点和索引数据和元数据
- 对索引执行CRUD和搜索操作
- 执行高级搜索操作,分页、过滤、排序等

-
集群健康信息:集健康状态有绿色(green)、黄色(yellow),红色(red)三种
绿色:一切正常(集群功能全部可用)
黄色:所有数据都可用,但某些副本尚未分配(集群完全正常工作)
红色:由于某些原因,某些数据不可用(集群只有部分功能正常工作):可用的分片可以继续提供搜索请求,但是需要尽快修复它,因为存在未分配的分片
-
以上信息的输出含义:
epoch:时间戳
timestamp:时间戳
cluster:集群名称
status: green代表健康;yellow代表分配了所有主分片,但至少缺少一个副本,此时集群数据仍旧完整;red代表部分主分片不可用,可能已经丢失数据。
node.total:代表在线的节点总数量
node.data:代表在线的数据节点的数量
shardsactive_shards:存活的分片数量
pri:active_primary_shards 存活的主分片数量 正常情况下 shards的数量是pri的两倍。
relo:relocating_shards 迁移中的分片数量,正常情况为 0
init:initializing_shards 初始化中的分片数量 正常情况为 0
unassign:unassigned_shards 未分配的分片 正常情况为 0
pending_tasks:准备中的任务,任务指迁移分片等 正常情况为 0
max_task_wait_time:任务最长等待时间
active_shards_percent:正常分片百分比 正常情况为 100%
Elasticsearch 基础使用
查看节点列表
对于GET /_cat/nodes?v 输出信息的解读:
- ip:节点的IP地址
- heap.percent:堆内存占用百分比
- ram.percent:内存占用百分比
- cpu:CPU占用百分比
- load_1m:1分钟的系统负载
- load_5m:5分钟的系统负载
- load_15m:15分钟的系统负载
- node.role:节点的角色
- master:是否是主节点
- name:节点名称
curl -X GET "http://localhost:9200/_cat/nodes?v"
# 以下输出表示这个集群只有一个节点,名称为vm01

# 举其他集群环境的一个例子
curl -X GET "http://xx.xx.xx.xx:xxxx/_cat/nodes?v"

列出索引信息
列出环境中的索引信息:GET /_cat/indices?v
返回信息解读:
-
health:索引健康状态
-
status:索引开启状态
-
index:索引名称
-
uuid:索引的UUID
-
pri:索引主分片数
-
rep:索引副分片数
-
docs.count:索引文档总数
-
docs.deleted:索引中删除状态的文档
-
store.size:主分片+副本分片的大小
-
pri.store.size:主分片的大小
curl -X GET http://localhost:9200/_cat/indices?v
# 以下表示集群中还没有索引

# 举一个其他环境的例子
curl -X GET "http://xx.xx.xx.xx:xxxx/_cat/indices?v"

查看节点分片信息
显示每个节点的分片信息:GET _cat/allocation?v
- shards:节点承载的分片数量
- disk.indices:索引占用的空间大小
- disk.used:节点所在机器已使用的磁盘空间大小
- disk.avail:节点可用空间大小
- disk.total:节点总空间大小
- disk.percent:节点磁盘占用百分比
- host:节点host
- ip:节点ip
- node:节点名称
# 查看初始环境的节点分片信息
curl -X GET http://localhost:9200/_cat/allocation?v

# 集群环境一些例子
curl -X GET "http://xx.xx.xx.xx:xxxx/_cat/allocation?v"

其他的一些信息查询
除以上常用的之外,还提供了aliases、count、health、master、nodeattrs、pending_tasks、plugins、recovery、segments、shards、thread_pool、templates的查看,用户和上述一致的。
创建索引
使用PUT方法创建索引,末尾调用pretty可进行友好返回显示。
# 创建一个名为index1的索引,然后再次列出所有索引
curl -XPUT "http://localhost:9200/index1?pretty"
curl -XGET "http://localhost:9200/_cat/indices?v"
# 查看索引信息:一个名为index1的索引,他有一个分片和一个副本,里面有0个文档(默认的规则)
# 为什么会是黄色状态:默认分片有一个副本,但是副本为了高可用,是不能和主分片在一个节点上的,且只有一个节点运行,所以健康状态是黄色的

索引和查询文档
我们将一些数据放在index1的索引中,可以通过postman工具,这样方便一点:
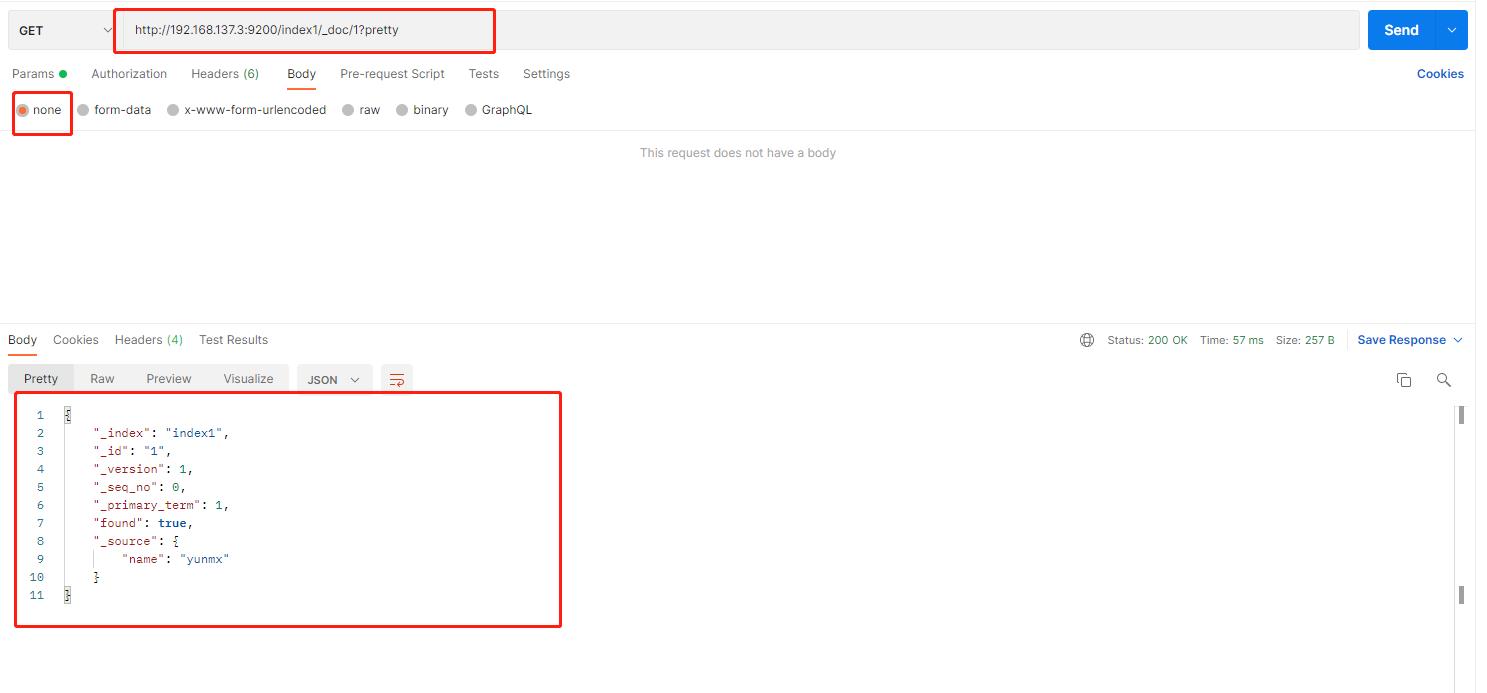
- 这就在index1索引中成功创建了一个新的文档,这个文档的ID是1,如果index1索引不存在,那么它会自动创建该索引

- 检索一下刚才创建的索引:不用传递任何参数哈
删除索引
使用DELETE删除刚才创建的索引:返回true

再查看所有的索引:没有索引了

修改数据
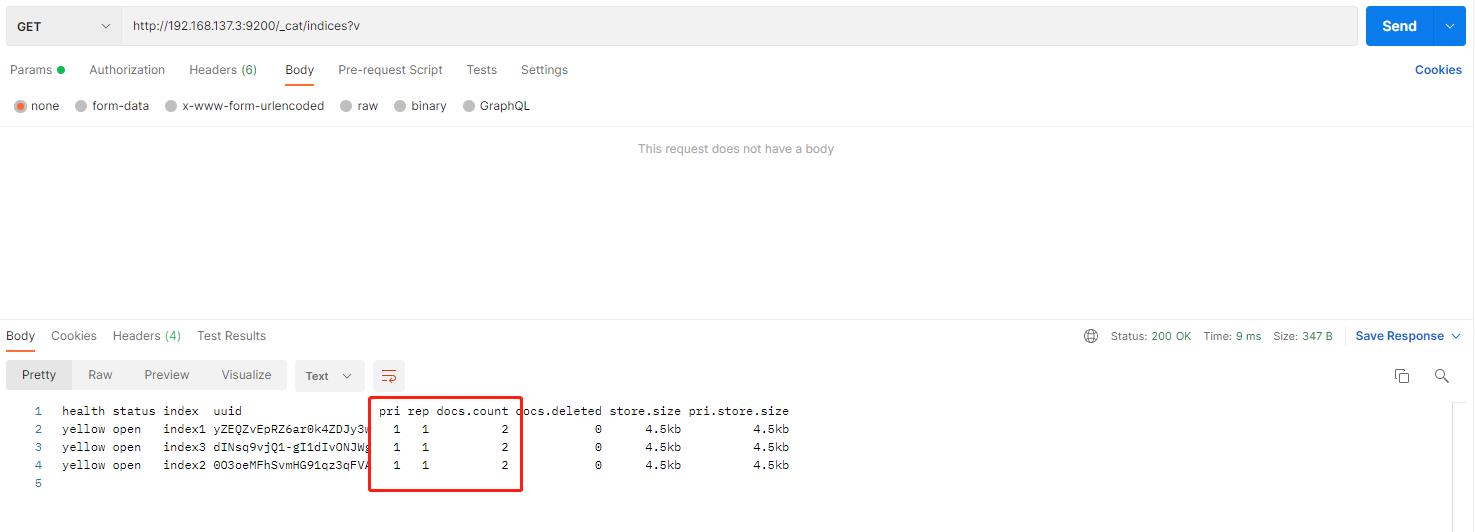
前提:先创建一个index1的索引,然后加一些数据进去测试:3个索引,每个索引有2个文档
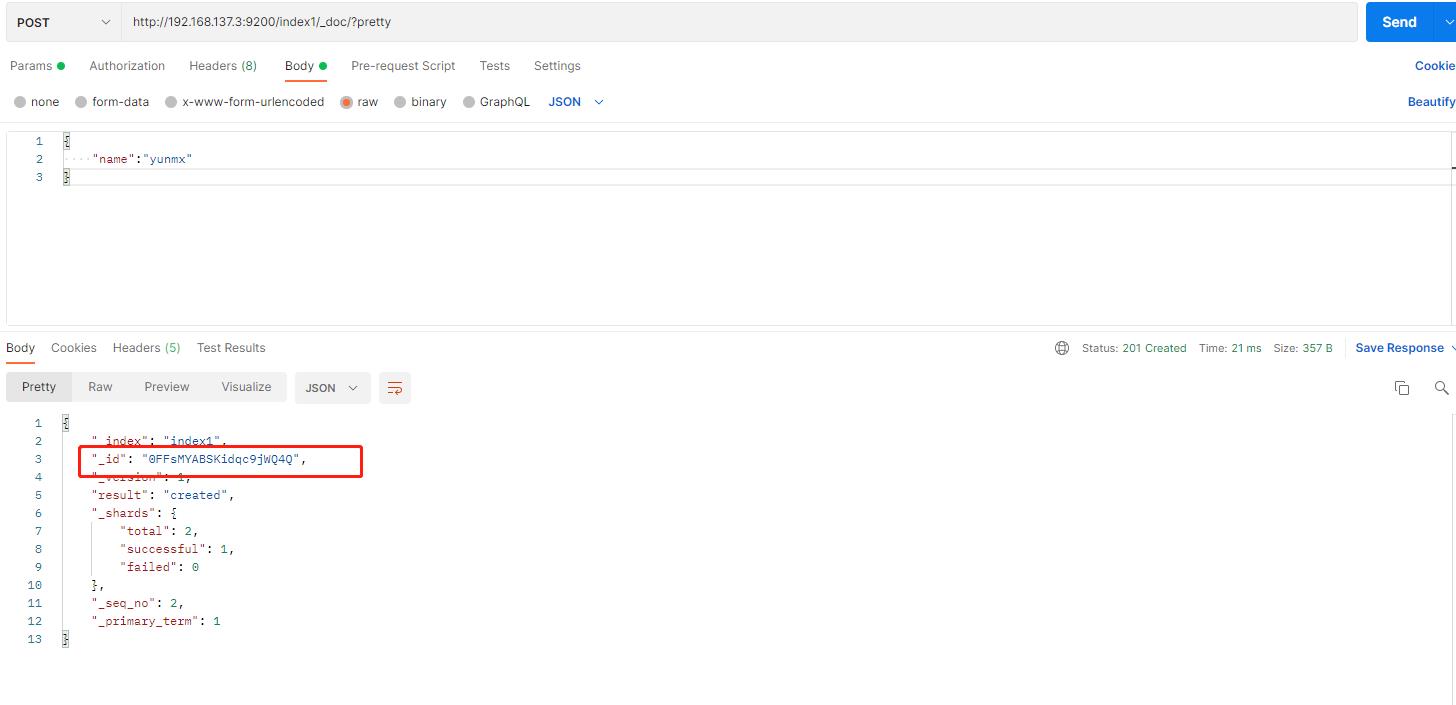
- 如果PUT指定ID的文档到相关索引里面,将替换该ID的文档,即重新索引;如果是不同的ID,则新增一个文档
- 新增文档时候,ID是可选的,如果没有指定ID,则生成一个随机ID
-
更新文档:并不是就地更新,而是删除旧的文档,然后索引一个新的文档,但对我们程序调用来说,只调用一次,由于底层数据结构决定了所有的更新操作都是先删除就文档,再插入一条新的文档,和关系型数据库不一样,无法做到字段级别的更新
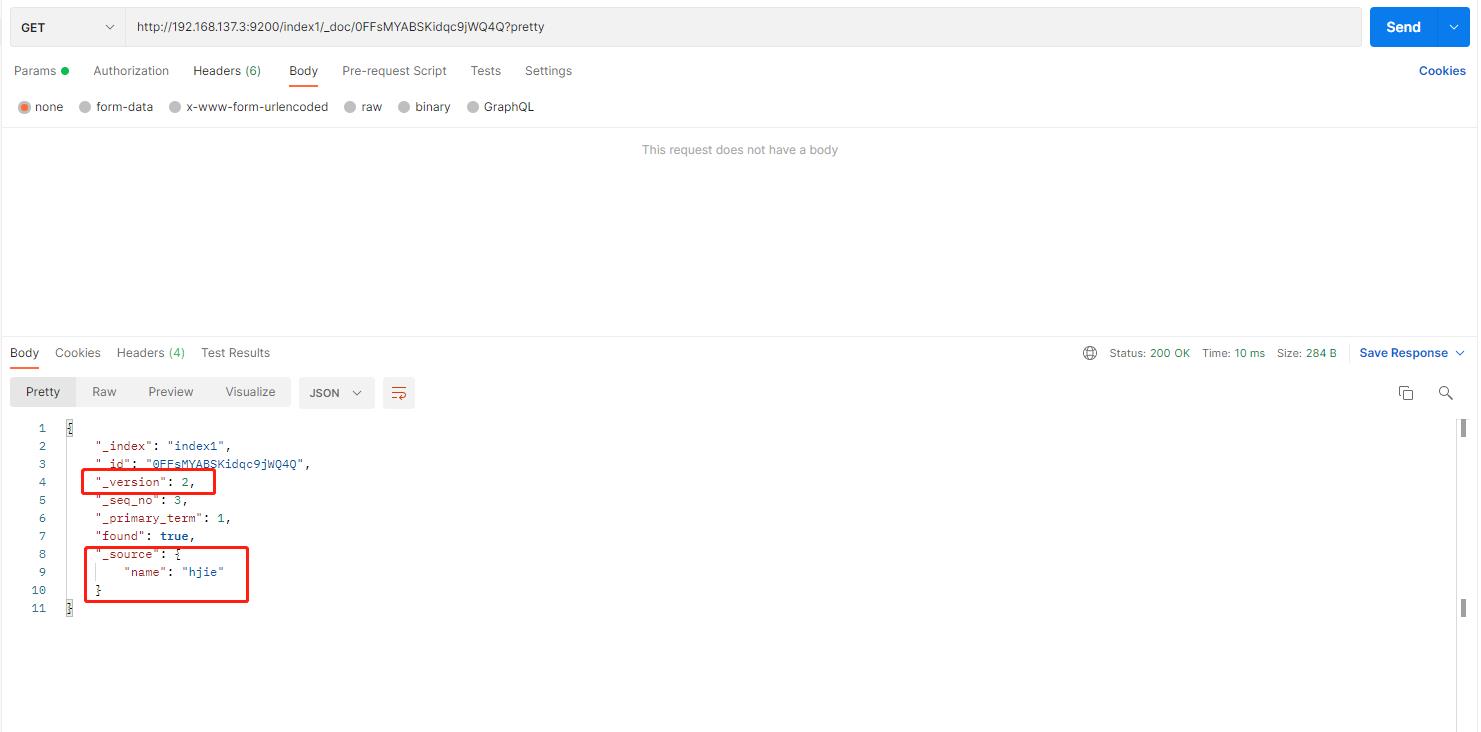
举例:就拿上面随机新增的ID进行操作:更新一下文档内容:name的值等于hjie

查询最新的文档信息内容:
-
删除文档:删除上述随机生成ID的文档,使用DELETE方法

-
批量操作:除了能够索引、更新和删除单个文档外,Elasticsearch还提供了使用批量API批量执行上述任何操作的功能,非常棒!
不过对于我来说,就不演示了,主要是演示了没成功了,应该是格式问题,不经常用觉得挺复杂的,批量操作的API可以参考资料:https://www.jianshu.com/p/7928678cc230/

扩展:对于删除操作,并不会立即删除对应的源文档,删除只是删除了文档的ID,
批量操作:不会因为其中一个操作失败而失败,返回时候会给予一个状态值,看批量操作是否失败
探索数据
从网上搞的示例数据:accounts.json导入到系统中

查看导入的索引情况:索引名称test:包含了1000个文档

搜索API
通过REST请求URL搜索参数;通过REST请求主体发送搜索参数。
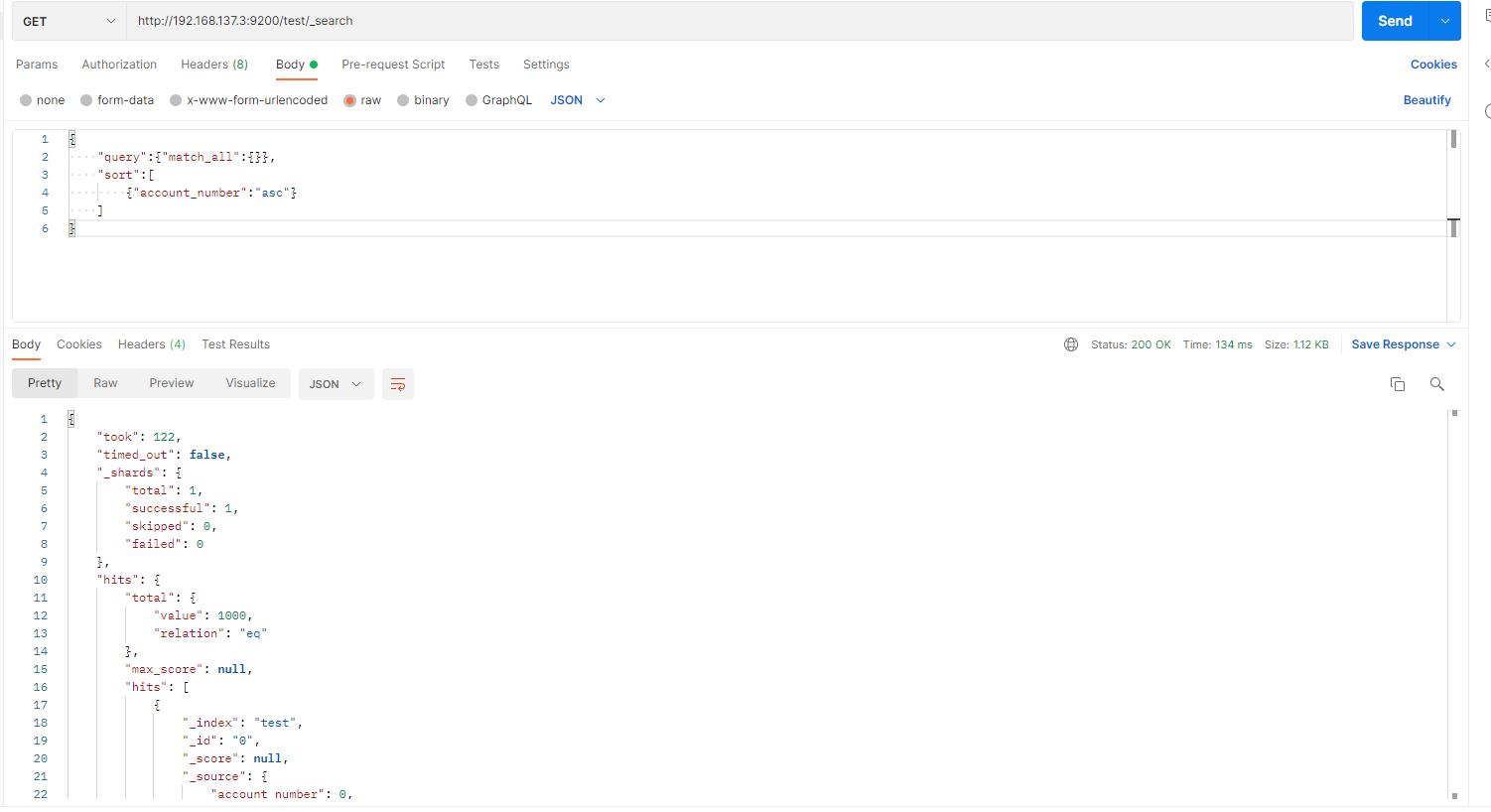
测试:返回test索引中的所有文档
方式:通过主体body形式搜索
部分数据结果如下:
另一种URL参数搜索:curl -X GET "http://localhost:9200/test/_search?q=*&sort=account_number:asc&pretty"
说明:test参数指明了所用的索引,_search指示这是一个搜索请求(_search endpoint),q=*参数指Elasticsearch匹配指定索引中的所有文档。
sort=account_number:asc参数指示使用每个文档的account_number字段按升序对结果进行排序,pretty参数告诉Elasticsearch返回漂亮打印的JSON结果。

结果说明:
-
第2行,took表示Elasticsearch执行搜索所用的时间,单位是ms。
-
第3行,timed_out用来指示搜索是否超时。
-
第4行,_shards指示搜索了多少分片,以及搜索成功和失败的分片的计数。
-
第10行,hits用来实际搜索结果集。
-
第11行,hits.total是包含与搜索条件匹配的文档总数信息的对象。
-
第12行,hits.total.value表示总命中计数的值(必须在hits.total.relation上下文中解释)。
-
第13行,确切来说,默认情况下,hits.total.value是不确切的命中计数,在这种情况下,当hits.total.relation的值是eq时,hits.total.value的值是准确计数。当hits.total.relation的值是gte时,hits.total.value的值是不准确的。
-
第16行,hits.hits是存储搜索结果的实际数组(默认为前10个文档)。
-
第35行,hits.sort表示结果排序键(如果请求中没有指定,则默认按分数排序)。
-
hits.total的准确性由请求参数track_total_hits控制,当设置为true时,请求将准确跟踪总命中数(“relation”:“eq”)。它默认为10000,这意味着总命中数精确跟踪多达10000个文档,当结果集大于10000时,hits.total.value的值将是10000,也就是不准确的。可以通过将track_total_hits显式设置为true强制进行精确计数,但这会增大集群资源的开销。
-
搜索一旦返回结果,将完全完成请求,不会再消耗服务器资源。
查询语言
提供了一种JSON风格的语言来执行查询,被成为Query DSL。

上述搜索表明:query指明了查询定义是什么,匹配部分是想要运行的查询类型,match_all表示搜索指定索引中的所有文档,也可以传递其他参数来影响搜索结果,不指定size,默认值是10

搜索文档
-
返回特定字段
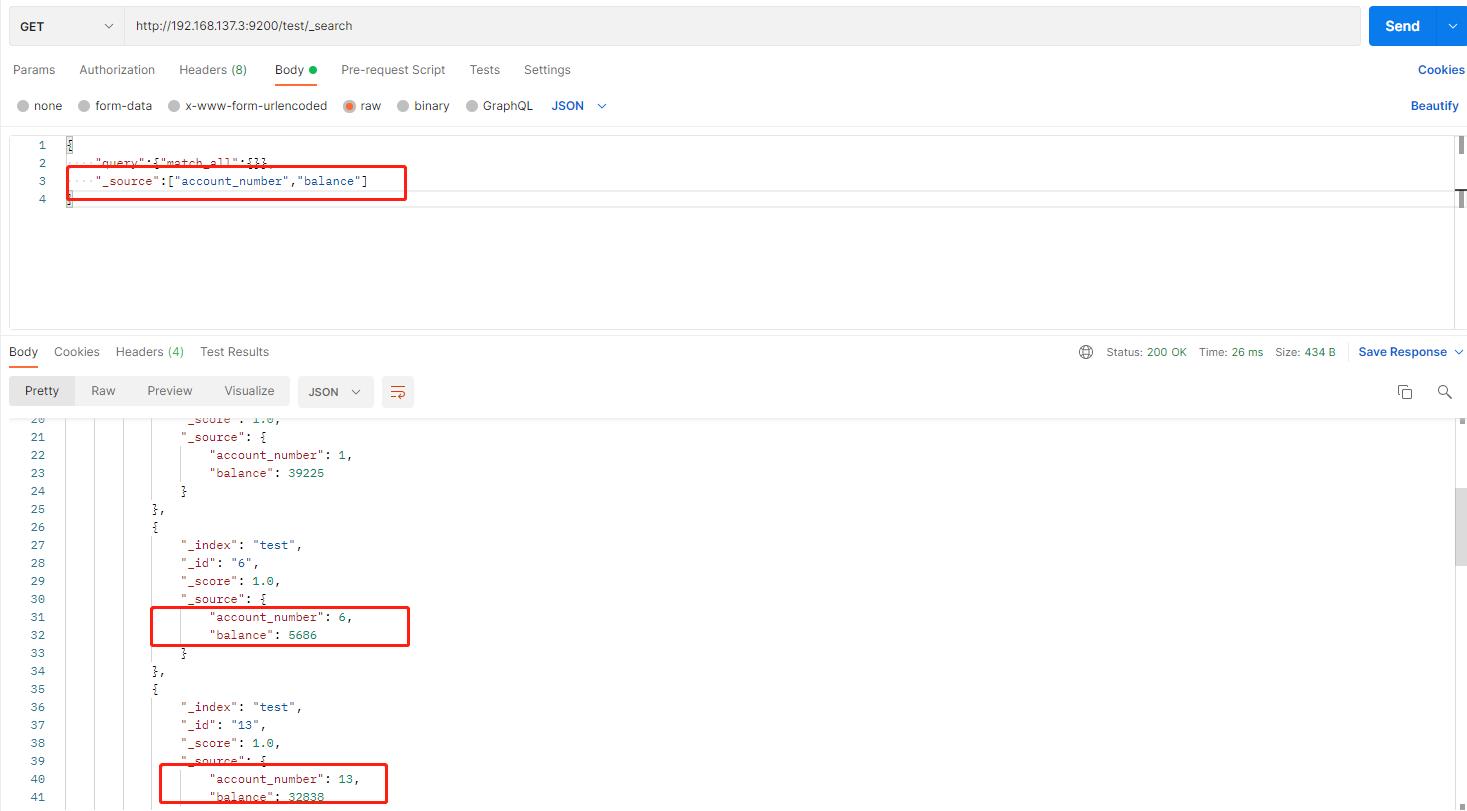
-
匹配查询
atch query的查询,它可以被视为基本的字段化搜索查询(即针对特定字段或一组字段进行的搜索)
以下查询只返回账户为20的一条数据

-
布尔查询
布尔查询是指使用布尔逻辑的方式把基本的查询组合成复杂的查询。
以下例子解读:
- must子句指定文档被视为匹配项时必须为真的所有查询:地址中必须同时包括词mill和lane。

以下例子解读:
- should子句指定一个查询列表,其中任何一个查询为真,文档即被视为匹配,也就是只需满足其中一个条件即可。

以下例子解读:
- ust_not子句指定一个查询列表,其中任何一个查询都不能为真,文档才能被视为匹配。
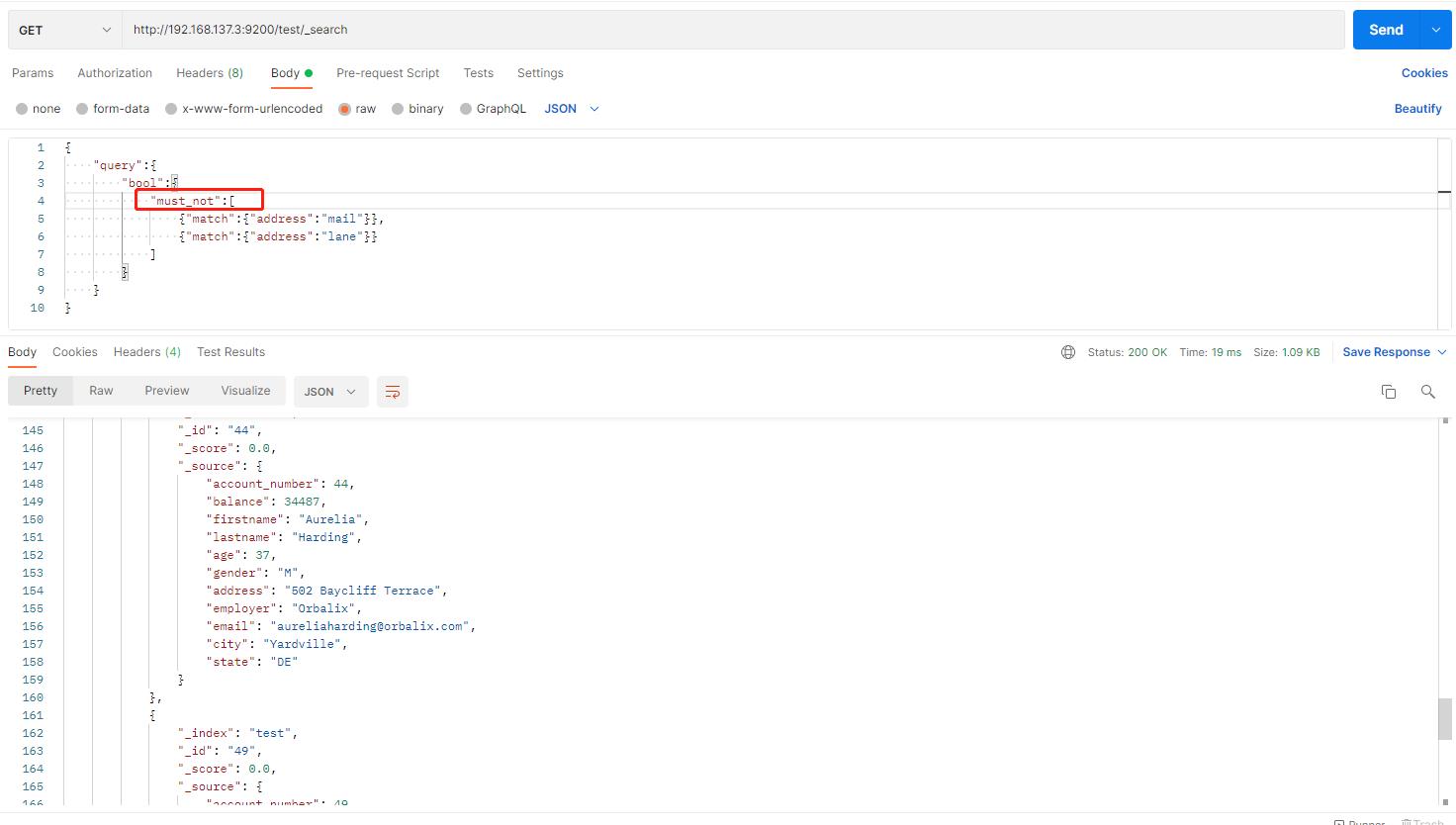
bool查询中同时组合must、should和must_not子句;还可以在这些bool子句中嵌套bool查询,以模拟任何复杂的多级布尔逻辑。(太复杂了,我是不会)

-
条件过滤
导入的数据中有个 balance字段(返回余额),请看下面的例子:
-
找到余额大于或等于20000且小于或等于30000的账户
-
bool查询包含一个match_all查询(查询部分)和一个range查询(过滤部分)。可以将任何其他查询替换为查询和过滤部分。在上述情况下,范围查询是完全有意义的,因为属于范围的文档都是“相等”匹配的,即没有文档比其他文档更相关。
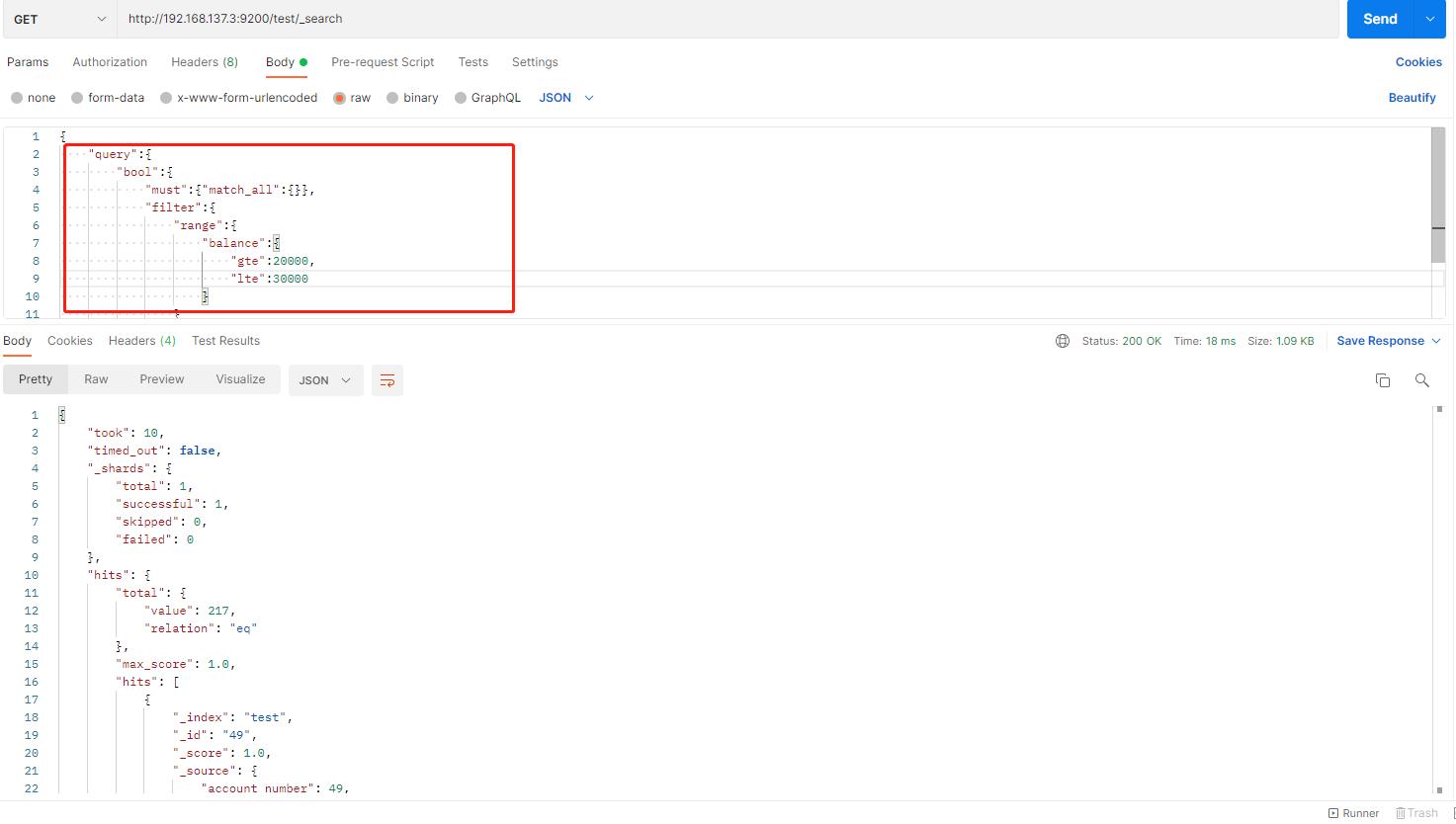
-
-
聚合查询
聚合(aggregation)提供了对数据分组和提取统计信息的能力。聚合功能可以理解为大致等同于SQL中的Group By和SQL聚合函数的功能。在Elasticsearch
中,可以执行返回命中文档的搜索,同时返回与搜索结果分离的聚合结果。从某种意义上说,这是非常强大和高效的,可以同时运行和查询多个聚合,并一次
性获得两个(或多个)操作的结果,避免使用单一的API进行多次网络往返。
请看下面例子:
- size=0,表示不显示搜索结果,在响应中看到聚合结果。

总得来说,得益于REST风格的API,使用上非常简单,我们无需知道内部的任何逻辑,直接拿来用就行
以上是关于Elasticsearch 笔记 |快速使用的主要内容,如果未能解决你的问题,请参考以下文章