paddleseg学习记录——模型预测
Posted weightOneMillion
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了paddleseg学习记录——模型预测相关的知识,希望对你有一定的参考价值。
1预测命令格式
predict.py脚本是专门用来可视化预测案例的,命令格式如下所示:
python predict.py \\
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \\
--model_path output/iter_1000/model.pdparams \\
--image_path dataset/optic_disc_seg/JPEGImages/H0003.jpg \\
--save_dir output/result
其中image_path也可以是一个目录,这时候将对目录内的所有图片进行预测并保存可视化结果图。
同样的,可以通过--aug_pred开启多尺度翻转预测, --is_slide开启滑窗预测。
2准备预测数据
在执行预测时,仅需要原始图像。你应该准备好 test.txt 的内容,如下所示:
images/image1.jpg
images/image2.jpg
…
在调用predict.py进行可视化展示时,**文件列表中可以包含标注图像。**在预测时,模型将自动忽略文件列表中给出的标注图像。因此,你也可以直接使用训练、验证数据集进行预测。也就是说,如果你的train.txt的内容如下:
images/image1.jpg labels/label1.png
images/image2.jpg labels/label2.png
…
此时你可以在预测时将image_list指定为train.txt,将image_dir指定为训练数据所在的目录。PaddleSeg的鲁棒性允许你这样做,输出的结果将是对原始训练数据的预测结果。
3预测入口文件predict.py
3.1参数说明
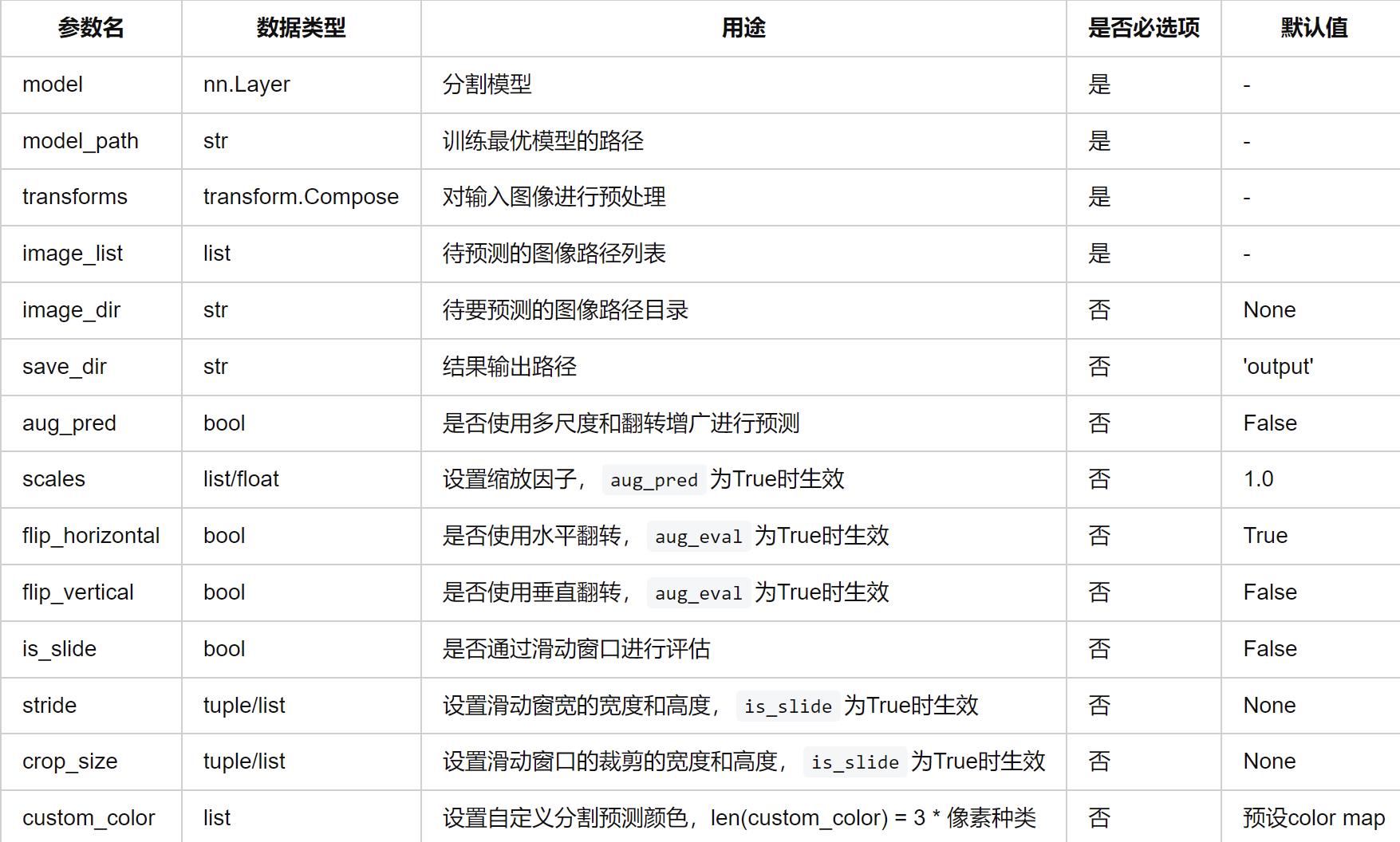
3.2paddleseg/predict.py
import os
import math
import cv2
import numpy as np
import paddle
from paddleseg import utils
from paddleseg.core import infer
from paddleseg.utils import logger, progbar, visualize
def mkdir(path):
sub_dir = os.path.dirname(path)
if not os.path.exists(sub_dir):
os.makedirs(sub_dir)
def partition_list(arr, m):
"""split the list 'arr' into m pieces"""
n = int(math.ceil(len(arr) / float(m)))
return [arr[i:i + n] for i in range(0, len(arr), n)]
def predict(model,
model_path,
transforms,
image_list,
image_dir=None,
save_dir='output',
aug_pred=False,
scales=1.0,
flip_horizontal=True,
flip_vertical=False,
is_slide=False,
stride=None,
crop_size=None,
custom_color=None):
"""
predict and visualize the image_list.
"""
utils.utils.load_entire_model(model, model_path)
model.eval()
nranks = paddle.distributed.get_world_size()
local_rank = paddle.distributed.get_rank()
if nranks > 1:
img_lists = partition_list(image_list, nranks)
else:
img_lists = [image_list]
added_saved_dir = os.path.join(save_dir, 'added_prediction')
pred_saved_dir = os.path.join(save_dir, 'pseudo_color_prediction')
logger.info("Start to predict...")
progbar_pred = progbar.Progbar(target=len(img_lists[0]), verbose=1)
color_map = visualize.get_color_map_list(256, custom_color=custom_color)
with paddle.no_grad():
for i, im_path in enumerate(img_lists[local_rank]):
im = cv2.imread(im_path)
ori_shape = im.shape[:2]
im, _ = transforms(im)
im = im[np.newaxis, ...]
im = paddle.to_tensor(im)
if aug_pred:
pred = infer.aug_inference(
model,
im,
ori_shape=ori_shape,
transforms=transforms.transforms,
scales=scales,
flip_horizontal=flip_horizontal,
flip_vertical=flip_vertical,
is_slide=is_slide,
stride=stride,
crop_size=crop_size)
else:
pred = infer.inference(
model,
im,
ori_shape=ori_shape,
transforms=transforms.transforms,
is_slide=is_slide,
stride=stride,
crop_size=crop_size)
pred = paddle.squeeze(pred)
pred = pred.numpy().astype('uint8')
# get the saved name
if image_dir is not None:
im_file = im_path.replace(image_dir, '')
else:
im_file = os.path.basename(im_path)
if im_file[0] == '/' or im_file[0] == '\\\\':
im_file = im_file[1:]
# save added image
added_image = utils.visualize.visualize(
im_path, pred, color_map, weight=0.6)
added_image_path = os.path.join(added_saved_dir, im_file)
mkdir(added_image_path)
cv2.imwrite(added_image_path, added_image)
# save pseudo color prediction
pred_mask = utils.visualize.get_pseudo_color_map(pred, color_map)
pred_saved_path = os.path.join(
pred_saved_dir,
os.path.splitext(im_file)[0] + ".png")
mkdir(pred_saved_path)
pred_mask.save(pred_saved_path)
# pred_im = utils.visualize(im_path, pred, weight=0.0)
# pred_saved_path = os.path.join(pred_saved_dir, im_file)
# mkdir(pred_saved_path)
# cv2.imwrite(pred_saved_path, pred_im)
progbar_pred.update(i + 1)
4自定义color map
经过预测后,我们得到的是默认color map配色的预测分割结果。
如果你想要使用其他颜色,可以参考如下命令:
python predict.py \\
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \\
--model_path output/iter_1000/model.pdparams \\
--image_path data/optic_disc_seg/JPEGImages/H0003.jpg \\
--save_dir output/result \\
--custom_color 0 0 0 255 255 255
参数解析
可以看到我们在最后添加了 --custom_color 0 0 0 255 255 255,这是什么意思呢?在RGB图像中,每个像素最终呈现出来的颜色是由RGB三个通道的分量共同决定的,因此该命令行参数后每三位代表一种像素的颜色,位置与label.txt中各类像素点一一对应。
如果使用自定义color map,输入的color值的个数应该等于3 * 像素种类(取决于你所使用的数据集)。比如,你的数据集有 3 种像素,则可考虑执行:
python predict.py \\
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \\
--model_path output/iter_1000/model.pdparams \\
--image_path data/optic_disc_seg/JPEGImages/H0003.jpg \\
--save_dir output/result \\
--custom_color 0 0 0 100 100 100 200 200 200
我们建议你参照RGB颜色数值对照表来设置--custom_color。
4.2 常见的自定义颜色rgb
白色:rgb(255,255,255)
黑色:rgb(0,0,0)
红色:rgb(255,0,0)
绿色:rgb(0,255,0)
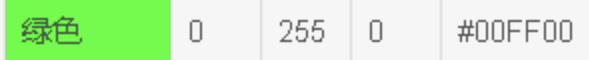
蓝色:rgb(0,0,255)

青色:rgb(0,255,255)

紫红色:rgb(255,0,255)

黄色:rgb(255,255,0)
紫色:rgb(160,32,240)

以上是关于paddleseg学习记录——模型预测的主要内容,如果未能解决你的问题,请参考以下文章