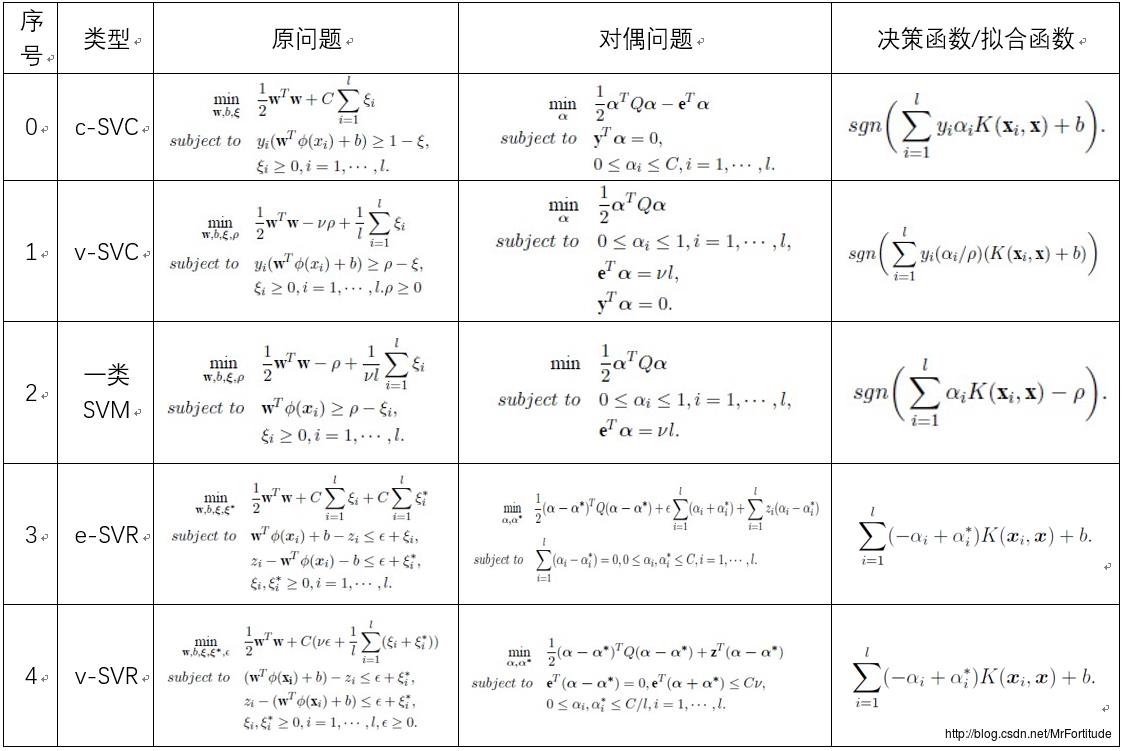
Libsvm使用笔记matlab
Posted 洋气月
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Libsvm使用笔记matlab相关的知识,希望对你有一定的参考价值。
根据以下教程配置:
(1038条消息) LIBSVM_繁拾简忆的博客-CSDN博客 https://blog.csdn.net/u014772862/category_6280683.html
https://blog.csdn.net/u014772862/category_6280683.html
一、libsvm使用
Libsvm 使用步骤:
1. 按照libsvm要求的数据格式,将要训练和预测的数据准备好;http://blog.csdn.net/u014772862/article/details/51828981
2. 使用svm-scale实现数据缩放,可有可没有,需要按照特征的相关性进行操作;
3. 考虑svm-train时是否使用核函数以及核函数的选择,建议首先考虑RBF核函数;
4. 采用grid.py选择最优参数c和g;http://blog.csdn.net/u014772862/article/details/51829727
5. 设置svm-train参数,对整个数据集训练获取svm模型;
6. 利用svm-predict加载训练好的模型进行测试与预测。
二、libsvm使用规范(四个函数)
2.89版本以前,都是svmscale、svmtrain和svmpredict
最新的是svm-scale、svm-train和svm-predict
1. libSVM的数据格式
Label 1:value 2:value ….
Label:是类别的标识,比如上节train.model中提到的1 -1,你可以自己随意定,比如-10,0,15。当然,如果是回归,这是目标值,就要实事求是了。
Value:就是要训练的数据,从分类的角度来说就是特征值,数据之间用空格隔开
比如: -15 1:0.708 2:1056 3:-0.3333
需要注意的是,如果特征值为0,特征冒号前面的(姑且称做序号)可以不连续。如:
-15 1:0.708 3:-0.3333
表明第2个特征值为0,从编程的角度来说,这样做可以减少内存的使用,并提高做矩阵内积时的运算速度。我们平时在matlab中产生的数据都是没有序号的常规矩阵,所以为了方便最好编一个程序进行转化。
2. svmscale的用法
svmscale是用来对原始样本进行缩放的,范围可以自己定,一般是[0,1]或[-1,1]。缩放的目的主要是
1)防止某个特征过大或过小,从而在训练中起的作用不平衡;
2)为了计算速度。因为在核计算中,会用到内积运算或exp运算,不平衡的数据可能造成计算困难。
用法:
svmscale [-l lower] [-u upper]
[-y y_lower y_upper]
[-s save_filename]
[-r restore_filename] filename
其中,[]中都是可选项:
-l:设定数据下限;lower:设定的数据下限值,缺省为-1
-u:设定数据上限;upper:设定的数据上限值,缺省为 1
-y:是否对目标值同时进行缩放;y_lower为下限值,y_upper为上限值;
-s save_filename:表示将缩放的规则保存为文件save_filename;
-r restore_filename:表示将按照已经存在的规则文件restore_filename进行缩放;
filename:待缩放的数据文件,文件格式按照libsvm格式。默认情况下,只需要输入要缩放的文件名就可以了:比如(已经存在的文件为test.txt)
svmscale test.txt
这时,test.txt中的数据已经变成[-1,1]之间的数据了。但是,这样原来的数据就被覆盖了,为了让规划好的数据另存为其他的文件,我们用一个dos的重定向符 > 来另存为(假设为out.txt):
svmscale test.txt > out.txt运行后,我们就可以看到目录下多了一个out.txt文件,那就是规范后的数据。假如,我们想设定数据范围[0,1],并把规则保存为test.range文件:
svmscale –l 0 –u 1 –s test.range test.txt > out.txt这时,目录下又多了一个test.range文件,可以用记事本打开,下次就可以用-r test.range来载入了。
3. svmtrain的用法
svmtrain我们在前面已经接触过,他主要实现对训练数据集的训练,并可以获得SVM模型。
用法: svmtrain [options] training_set_file [model_file]
其中,options为操作参数,可用的选项即表示的涵义如下所示:
-s设置svm类型:
0 – C-SVC
1 – v-SVC
2 – one-class-SVM
3 –ε-SVR
4 – n - SVR
-t设置核函数类型,默认值为2
0 --线性核:u'*v
1 --多项式核:(g*u'*v+coef0)degree
2 -- RBF核:exp(-γ*||u-v||2)
3 -- sigmoid核:tanh(γ*u'*v+coef0)
-d degree:设置多项式核中degree的值,默认为3
-gγ:设置核函数中γ的值,默认为1/k,k为特征(或者说是属性)数;
-r coef 0:设置核函数中的coef 0,默认值为0;
-c cost:设置C-SVC、ε-SVR、n - SVR中从惩罚系数C,默认值为1;
-n v:设置v-SVC、one-class-SVM与n - SVR中参数n,默认值0.5;
-pε:设置v-SVR的损失函数中的e,默认值为0.1;
-m cachesize:设置cache内存大小,以MB为单位,默认值为40;
-eε:设置终止准则中的可容忍偏差,默认值为0.001;
-h shrinking:是否使用启发式,可选值为0或1,默认值为1;
-b概率估计:是否计算SVC或SVR的概率估计,可选值0或1,默认0;
-wi weight:对各类样本的惩罚系数C加权,默认值为1;
-v n:n折交叉验证模式;
model_file:可选项,为要保存的结果文件,称为模型文件,以便在预测时使用。默认情况下,只需要给函数提供一个样本文件名就可以了,但为了能保存结果,还是要提供一个结果文件名,比如:test.model,则命令为:
svmtrain test.txt test.model4. svmpredict的用法
svmpredict是根据训练获得的模型,对数据集合进行预测。
用法:svmpredict [options] test_file model_file output_file其中,
options为操作参数,可用的选项即表示的涵义如下所示:
-b probability_estimates——是否需要进行概率估计预测,可选值为0或者1,默认值为0。
model_file ——是由svmtrain产生的模型文件;
test_file——是要进行预测的数据文件,格式也要符合libsvm格式,即使不知道label的值,也要任意填一个,svmpredict会在output_file中给出正确的label结果,如果知道label的值,就会输出正确率;
output_file ——是svmpredict的输出文件,表示预测的结果值。至此,主要的几个接口已经讲完了,满足一般的应用不成问题。对于要做研究的,还需要深入到svm.cpp文件内部,看看都做了什么。
三、代码详细流程
I. 清空环境变量
clear all
clcII. 导入数据
load BreastTissue_data.mat1. 随机产生训练集和测试集
n = randperm(size(matrix,1));2. 训练集——80个样本
train_matrix = matrix(n(1:80),:);
train_label = label(n(1:80),:);3. 测试集——26个样本
test_matrix = matrix(n(81:end),:);
test_label = label(n(81:end),:);III. 数据归一化
%% III. 数据归一化
[Train_matrix,PS] = mapminmax(train_matrix');
Train_matrix = Train_matrix';
Test_matrix = mapminmax('apply',test_matrix',PS);
Test_matrix = Test_matrix';IV. SVM创建/训练(RBF核函数)
这里使用的是交叉验证的方法 选出等距的多种c和g训练找到最合适的c和g,如果训练时间较长可以直接输入参数,跳过这一步
cmd = ' -t 2 -c 42.2243 -g 2.639' 参数设置:
SVM的主要思想是建立一个超平面作为决策曲面,使得正例和反例之间的距离边缘被最大化(其实,SVC与SVR在一定意义上,思想是完全统一的,都是最大化间隔,使得各自的损失函数值最小)SVM相对于目前相对较火的人工神经网络来讲,具有一定的优点,其中最为重要的是SVM获得模型理论上是全局最优的。而且,支持向量机复杂度与样本特征维度无关。
下面,简单记录一下学习使用libsvm过程中的第一步,了解各个参数的意义:
-s 选择SVM的类型
-d degree: 核函数中的degree设置(针对多项式核函数)(默认3)
-g r(gama): 核函数中的gamma函数设置(针对多项式/rbf/sigmoid核函数)(默认1/ k)
-r coef0: 核函数中的coef0设置(针对多项式/sigmoid核函数)((默认0)
-c cost: 设置C-SVC,e -SVR和v-SVR的参数(损失函数)(默认1) 一般可以选择10^t, t=-4, -3,…, 3, 4, 惩罚
过大容易造成过拟合
-n nu: 设置v-SVC,一类SVM和v- SVR的参数(默认0.5)
-p p: 设置e -SVR 中损失函数p的值(默认0.1)
-m cachesize: 设置cache内存大小,以MB为单位(默认40)
-e eps: 设置允许的终止判据(默认0.001)
-h shrinking: 是否使用启发式,0或1(默认1)
-wi weight: 设置第几类的参数C为weight*C(C-SVC中的C)(默认1)
-v n: n-fold交叉检验模式,n为fold的个数,必须大于等于2
[c,g] = meshgrid(-10:0.2:10,-10:0.2:10);
[m,n] = size(c);
cg = zeros(m,n);
eps = 10^(-4);
v = 5;
bestc = 1;
bestg = 0.1;
bestacc = 0;
for i = 1:m
for j = 1:n
cmd = ['-v ',num2str(v),' -t 2',' -c ',num2str(2^c(i,j)),' -g ',num2str(2^g(i,j))];
cg(i,j) = svmtrain(train_label,Train_matrix,cmd);
if cg(i,j) > bestacc
bestacc = cg(i,j);
bestc = 2^c(i,j);
bestg = 2^g(i,j);
end
if abs( cg(i,j)-bestacc )<=eps && bestc > 2^c(i,j)
bestacc = cg(i,j);
bestc = 2^c(i,j);
bestg = 2^g(i,j);
end
end
end
cmd = [' -t 2',' -c ',num2str(bestc),' -g ',num2str(bestg)];
创建/训练SVM模型
model = svmtrain(train_label,Train_matrix,cmd);V. SVM仿真测试
注意一定要 传入3个参数而不是两个, 且 测试lable 是m1的矩阵, 测试矩阵是mn的矩阵 m为样本个数, n为特征个数
[predict_label_1,accuracy_1,prob_estimates] = svmpredict(train_label,Train_matrix,model);
[predict_label_2,accuracy_2,prob_estimates2] = svmpredict(test_label,Test_matrix,model);
result_1 = [train_label predict_label_1];
result_2 = [test_label predict_label_2];
结果如下

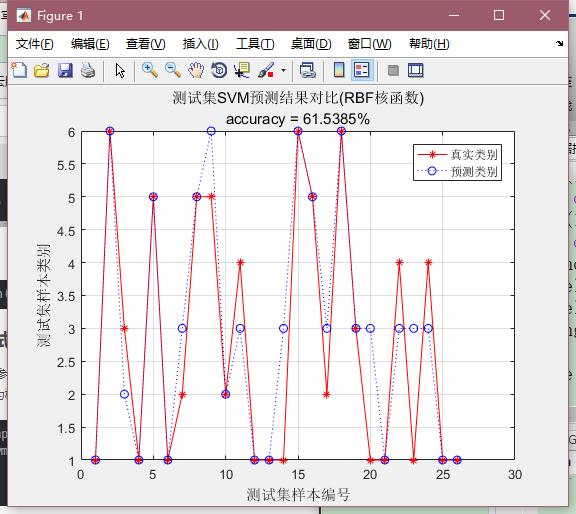
VI. 绘图
figure
plot(1:length(test_label),test_label,'r-*')
hold on
plot(1:length(test_label),predict_label_2,'b:o')
grid on
legend('真实类别','预测类别')
xlabel('测试集样本编号')
ylabel('测试集样本类别')
string = '测试集SVM预测结果对比(RBF核函数)';
['accuracy = ' num2str(accuracy_2(1)) '%'];
title(string)
以上是关于Libsvm使用笔记matlab的主要内容,如果未能解决你的问题,请参考以下文章