ClickHouse安装配置及表引擎使用
Posted ShenLiang2025
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ClickHouse安装配置及表引擎使用相关的知识,希望对你有一定的参考价值。
ClickHouse安装配置及表引擎使用案例
准备
-
- 集群安排
192.168.175.212 master
192.168.175.213 slave1
192.168.175.214 slave2
安装zookeeper
#1 切换到指定目录
cd /root/softwares/
# 2 下载二进制文件
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.5.9/apache-zookeeper-3.5.9-bin.tar.gz#3 解压
tar zxf apache-zookeeper-3.5.9-bin.tar.gz#4 配置
1 创建dataDir目录,比如:
mkdir –p /apps/zookeeper/data/zookeeper2 进入zookeeper的conf目录,拷贝zoo_sample.cfg为zoo.cfg。并在配置文件里加入如下内容:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/apps/zookeeper/data/zookeeper
clientPort=2182
autopurge.purgeInterval=0
globalOutstandingLimit=200
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
注:1 myid可以从0开始,当前演示的是从1开始。
3 配置myid
echo 1 >> /apps/zookeeper/data/zookeeper/myid注:同理配置其它节点。
4 配置环境变量 /etc/profile
export ZOOKEEPER_HOME=/apps/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/binsource /etc/profile5 启动zookeeper
每个节点上启动zookeeper,命令见下:
zkServer.sh start
6 查看zookeeper状态
zkServer.sh status
各节点安装clickhouse
在各个节点上安装clickhouse服务和客户端。
1 安装clickhouse
单节点安装clickhouse
# 安装dirmngr
sudo apt-get install dirmngr
# 加入key
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv E0C56BD4
# 更新clickhouse源
echo "deb http://repo.clickhouse.tech/deb/stable/ main/" | sudo tee \\
/etc/apt/sources.list.d/clickhouse.list
sudo apt-get update
# 安装clickhouse服务和客户端
sudo apt-get install -y clickhouse-server clickhouse-client
#启动服务
sudo service clickhouse-server start
# 客户端连接
clickhouse-client
- 创建数据目录、临时目录、用户文件
mkdir -p /data/clickhouse /data/clickhouse/tmp/ /data/clickhouse/user_files/- 配置config文件
在/etc/clickhouse-server/config.xml里进行如下配置:
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<path>/data/clickhouse/</path>
<tmp_path>/data/clickhouse/tmp/</tmp_path>
<user_files_path>/data/clickhouse/user_files/</user_files_path>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
修改IP 127.0.0.1为当前节点的IP
打开 <listen_host>::</listen_host> 的注释以使得客户端可以外部访问。
- 目录赋权
chown -R clickhouse:clickhouse /data
5 启动服务
/etc/init.d/clickhouse-server start
- 通过客户端连接
clickhouse-client --password --port 9000配置clickhouse集群
1 定义metrika.xml
在/etc/clickhouse-server/config.d内定义集群配置:
<yandex>
<clickhouse_remote_servers>
<!--集群名称,clickhouse支持多集群的模式-->
<clickhouse_cluster>
<!--定义分片节点,这里我指定3个分片,每个分片只有1个副本,也就是它本身-->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>server1</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<internal_replication>true</internal_replication>
<host>server2</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>server3</host>
<port>9000</port>
</replica>
</shard>
</clickhouse_cluster>
</clickhouse_remote_servers>
<!--zookeeper集群的连接信息-->
<zookeeper-servers>
<node index="1">
<host>server1</host>
<port>2181</port>
</node>
<node index="2">
<host>server1</host>
<port>2182</port>
</node>
<node index="3">
<host>server1</host>
<port>2183</port>
</node>
</zookeeper-servers>
<!--定义宏变量,后面需要用-->
<macros>
<replica>server1</replica>
</macros>
<!--不限制访问来源ip地址-->
<networks>
<ip>::/0</ip>
</networks>
<!--数据压缩方式,默认为lz4-->
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
注:这里的macros需要修改成每个节点的IP
2 配置引用
在config.xml里追加对metrika.xml的引用。
<!--引入metrika.xml-->
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
#引用Zookeeper配置的定义
<zookeeper incl="zookeeper-servers" optional="true" />
3 启动clickhouse集群
每个节点上启动clickhouse服务。
sudo clickhouse start
- 验证
#查询Zookeeper根目录
select * from system.zookeeper where path = '/'
#查询ClickHouse目录
select * from system.zookeeper where path = '/clickhouse'
表引擎简介
表引擎是clickhouse的一大特色。可以说, 表引擎决定了如何存储标的数据。包括:
1)数据的存储方式和位置,写到哪里以及从哪里读取数据
2)支持哪些查询以及如何支持。
3)并发数据访问。
4)索引的使用(如果存在)。
5)是否可以执行多线程请求。
6)数据复制参数。
使用
#1 ReplicatedMergeTree
#2 前置条件
在config里定义宏指令,即macros标签。
/etc/clickhouse-server/config.xml内打开注释或者定义如下标签:
vi /etc/clickhouse-server/config.xml
:set nu
:814
<macros>
<shard>01</shard>
<replica>host01</replica>
</macros>
注:如果不配置那么在引用宏指令建表时会报错,详见:
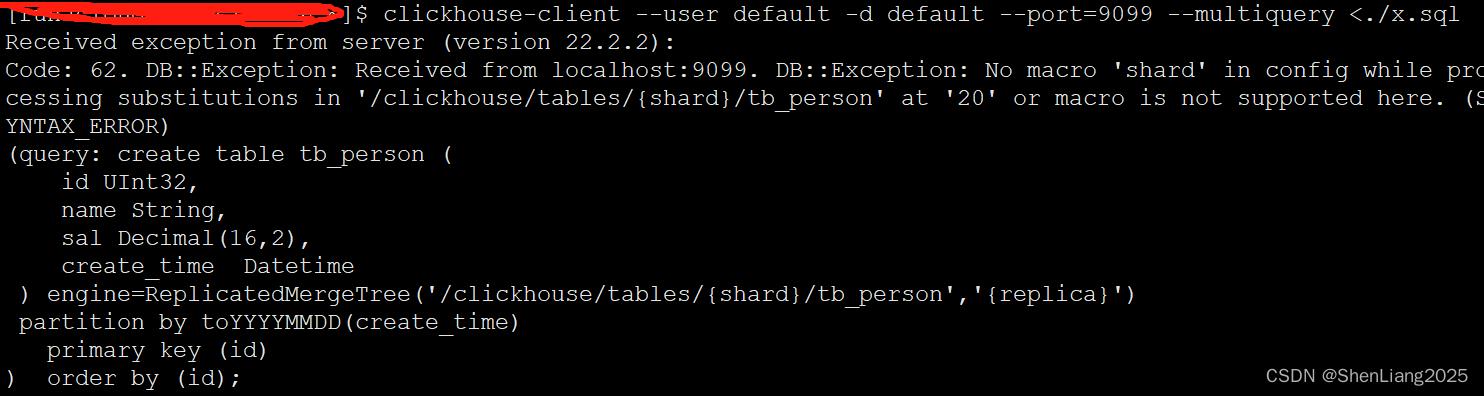
#3 准备建表语句
准备个建表语句,脚本内容见下:
create table tb_person (
id UInt32,
name String,
sal Decimal(16,2),
create_time Datetime
) engine=ReplicatedMergeTree('/clickhouse/tables/shard/tb_person','replica')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id);
注: shard里的“shard”和replica 里的“replica”必须和config.xml里的macros下标签名匹配上。
#4 执行建表语句
分别在各个节点里执行同样的建表语句(默认端口9000)
clickhouse-client --user default -d default --port=9099 --multiquery <./x.sql
#5 插入数据
在一个节点上插入数据。
INSERT INTO tb_person values(1,'Shenl',10000.50,now())
INSERT INTO tb_person values(2,'Liang',20000.85,now())
#6 其它节点上验证
启动客户端验证数据
clickhouse-client --user default -d default --port=9099
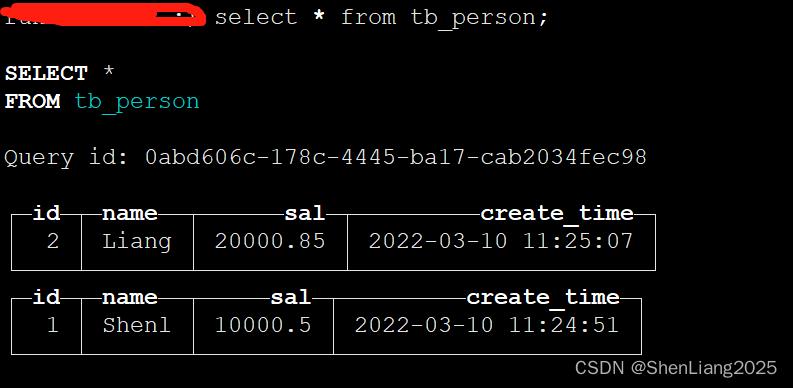
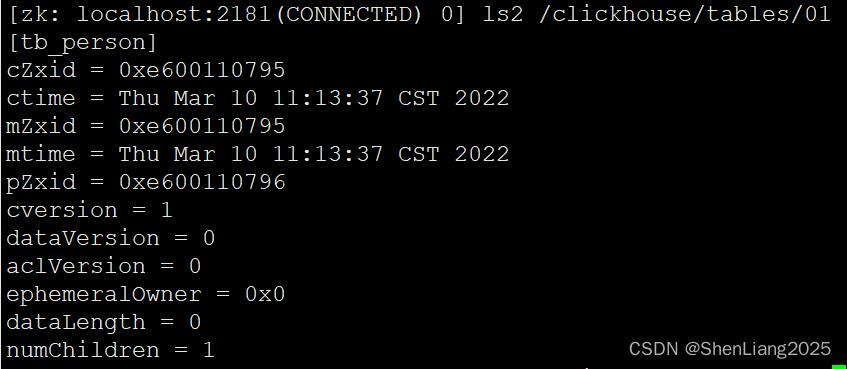
#7 zookeeper里验证
zookeeper客户端查看tb_person所在表节点
ls2 /clickhouse/tables/01
Tinylog
最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中。写入时,数据将附加到文件末尾。并发数据访问不受任何限制:
1 如果同时从表中读取并在不同的查询中写入,则读取操作将抛出异常
2如果同时写入多个查询中的表,则数据将被破坏。
这种表引擎的典型用法是 write-once:首先只写入一次数据,然后根据需要多次读取。查询在单个流中执行。换句话说,此引擎适用于相对较小的表(建议最多100万行)。
该表引擎不支持索引。
示例:
create table tb_person_tinylog ( id UInt32,name String,sal Decimal(16,2), create_time Datetime) engine=TinyLog;
注:该模式下不支持PARTITION、PRIMARY Key和ORDER BY
mysql表引擎
MySQL 引擎可以对存储在远程 MySQL 服务器上的数据执行 SELECT 查询。
#1 创建mysql表引擎
use default
CREATE TABLE default.department2 (deptno UInt32,dname String,loc String ) ENGINE = MySQL('192.168.0.101:3306', 'ShenLiang2025', 'dept', 'root', 'root1234');
#2 在clickhouse里查询
select * from department2;
Mysql物化表引擎
Clickhouse 22.2版本验证不通过。该参数是实验性,不建议生产里使用。
当前验证版本为Clickhouse 20.8.2.3,mysql5.7。
# 1 ck里查看版本
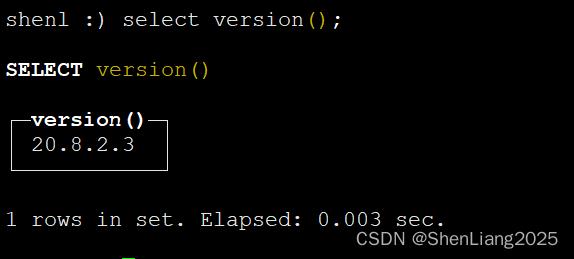
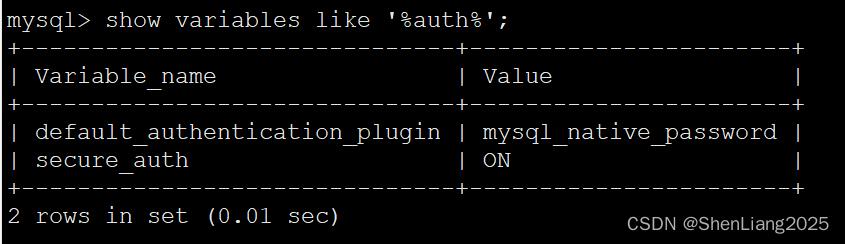
# 2 插件为mysql_native_password
show variables like '%auth%';
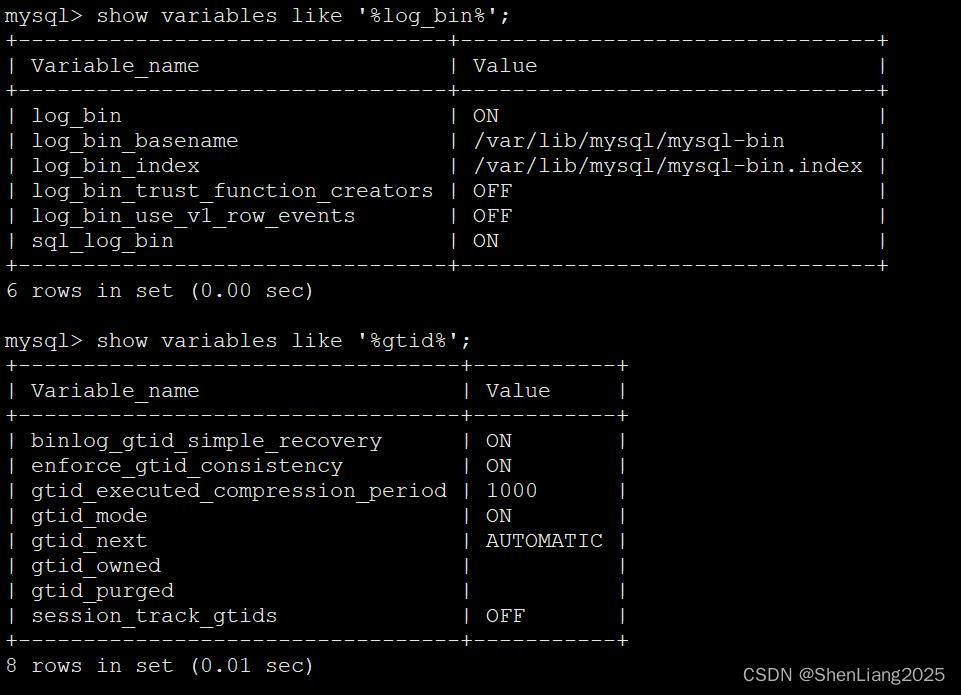
#3 Bin log相关参数打开
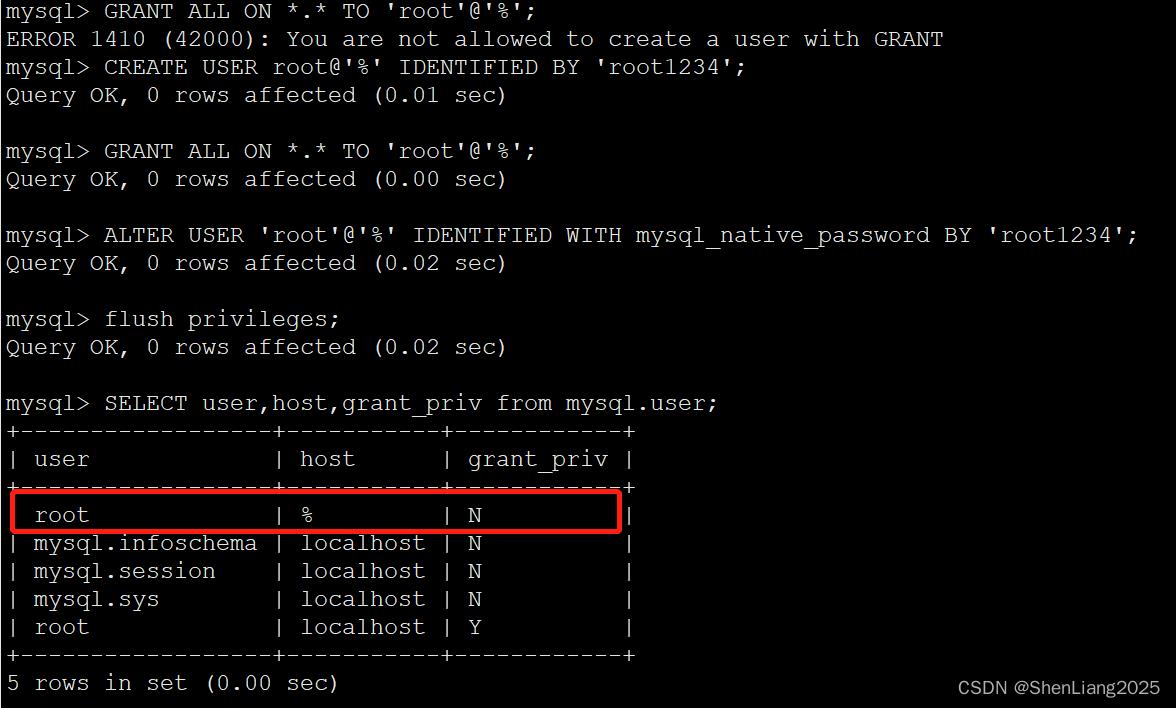
#4 用户开放访问权限,至少clickhouse所在的IP能访问,这里是所有机器都可以。
#5 开启物化视图参数(选项)。
SET allow_experimental_database_materialize_mysql = 1;
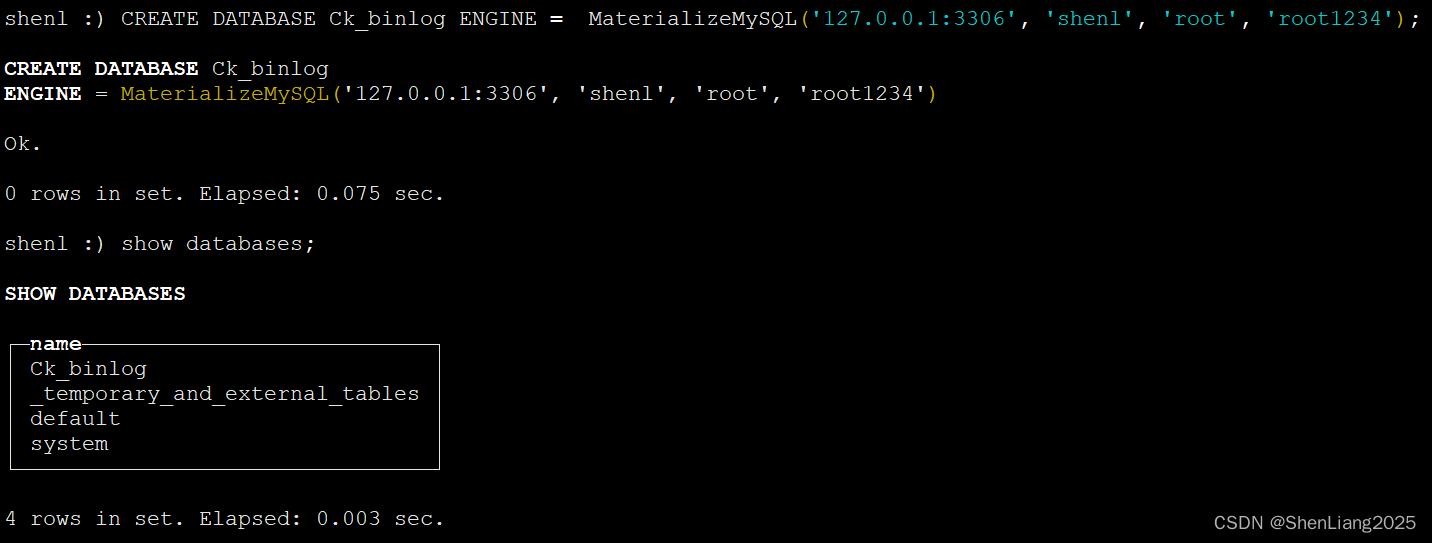
#5 clickhouse里创建MaterializeMySQL
CREATE DATABASE Ck_mysqlbinlog ENGINE = MaterializeMySQL('127.0.0.1:3306', 'shenl', 'root', 'root1234');
#5 验证
#1 插入 insert
Mysql里插入一条记录
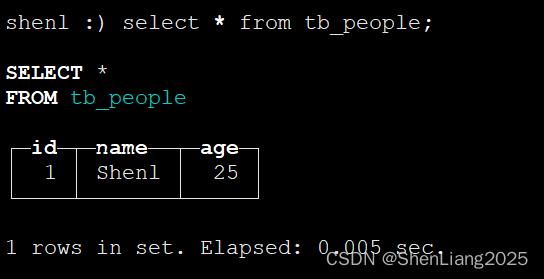
INSERT INTO tb_people values(1,'Shenl',25);
Ck里查询
select * from tb_people
#2 更新update
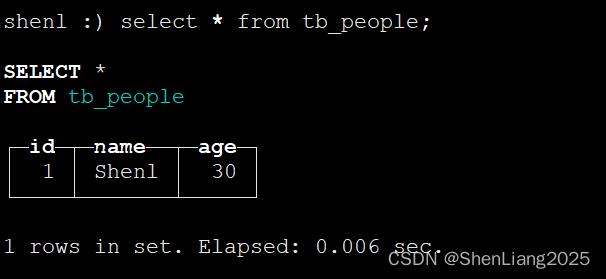
在mysql里再次将age更新为28,再进入ck里查询。
select a.*,_version,_sign from tb_people a where a.id = 1;
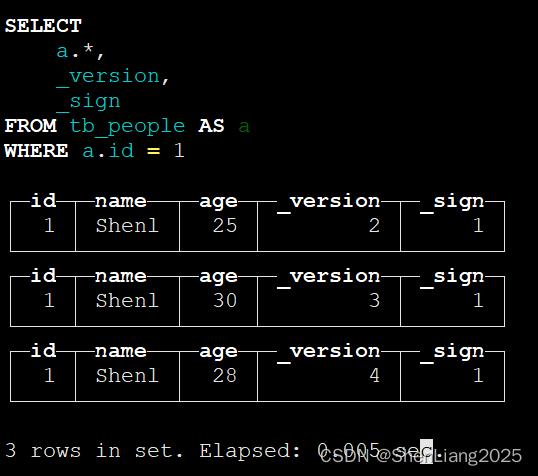
由此可见ck取版本号最大的。
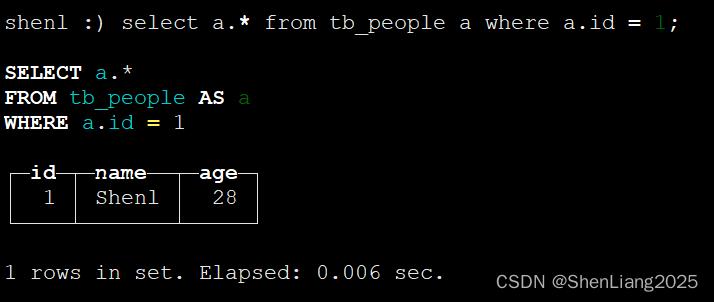
#3 删除 delete
Mysql里删除id为1的记录
delete from tb_people where id=1;
ck里查询:
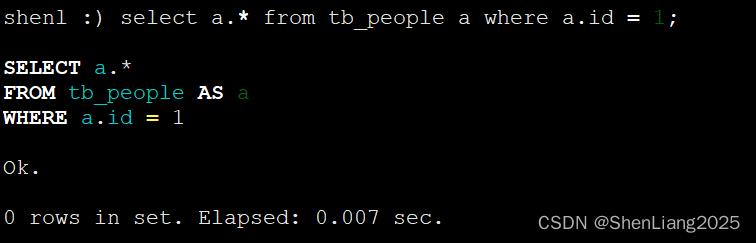
加_version,_sign查询时会发现age为28的那条记录的_sign被标记为-1,即删除。

#4 修改字段名
Mysql里修改name字段为fullname
alter table tb_people change name fullname varchar(30);
进入ck里查询,则会报错
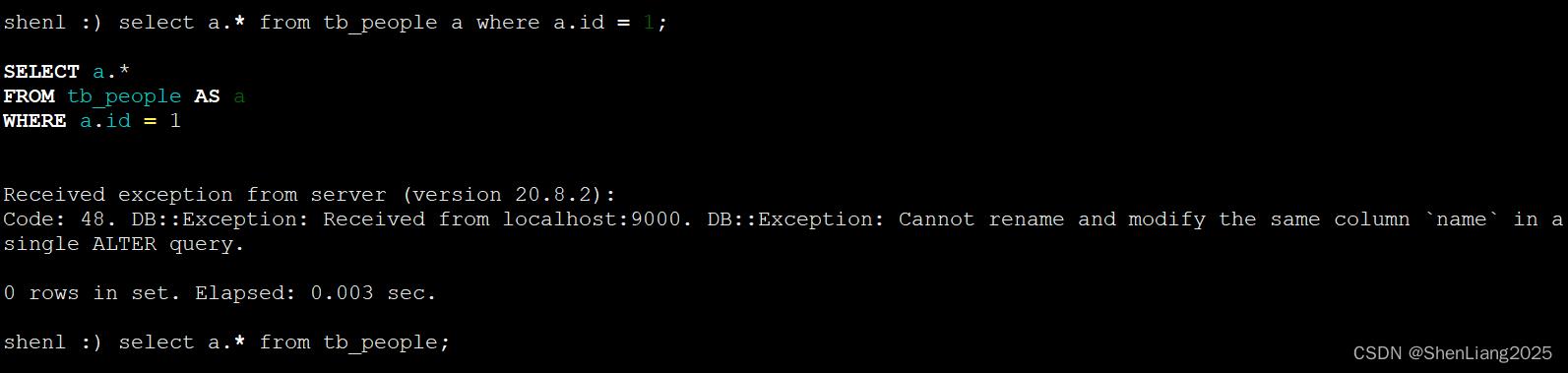
注:支持添加列与删除列,在mysql添加一列,随后再删除
以上是关于ClickHouse安装配置及表引擎使用的主要内容,如果未能解决你的问题,请参考以下文章