注解第二部分原理分析和注解处理器
Posted xzj_2013
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了注解第二部分原理分析和注解处理器相关的知识,希望对你有一定的参考价值。
注解的原理分析
简单的说,注解的底层实现原理就是反射;
根据上一篇我们知道,获取注解信息,我们是通过反射从从class结构中获取出,那说明在某个时候注解被加入到class结构中去了。
从java源码到class字节码是由编译器完成的,而注解也是在编译时由编译器进行处理,【编译器会对注解符号处理并附加到class结构中】;
根据jvm规范,class文件结构是严格有序的格式,唯一可以附加信息到class结构中的方式就是【保存到class结构的attributes属性中】;
我们知道对于类、字段、方法,在class结构中都有自己特定的表结构,而且各自都有自己的属性,而对于注解,作用的范围也可以不同,可以作用在类上,也可以作用在字段或方法上,这时编译器会对应将注解信息存放到类、字段、方法自己的属性上;
在我们的MainActivity 类被编译后,在对应的MainActivity .class文件中会包含一个
RuntimeVisibleAnnotations属性,由于这个注解是作用在类上,所以此属性被添加到类的属性集上。
即TestAnnotation注解的键值对value=test会被记录起来。而当JVM加载MainActivity .class文件字
节码时,就会将RuntimeVisibleAnnotations属性值保存到MainActivity 的Class对象中,
于是就可以通过MainActivity .class.getAnnotation(TestAnnotation.class)
获取到TestAnnotation注解对象,进而再通过TestAnnotation注解对象获取到TestAnnotation里面的
属性值。
如果我们跟踪Class,Method的获取注解的方法,直到native层,继续往下,就会发现,最终都是会调用AnnotationParser的parsexxxx(…)等一系列方法获取到Annotation的实例
而parsexxxx中又会调用parseAnnotation2(…);
private static Annotation parseAnnotation2(ByteBuffer var0, ConstantPool var1, Class<?> var2, boolean var3, Class<? extends Annotation>[] var4)
int var5 = var0.getShort() & '\\uffff';
Class var6 = null;
String var7 = "[unknown]";
try
try
var7 = var1.getUTF8At(var5);
var6 = parseSig(var7, var2);
catch (IllegalArgumentException var18)
var6 = var1.getClassAt(var5);
catch (NoClassDefFoundError var19)
if (var3)
throw new TypeNotPresentException(var7, var19);
skipAnnotation(var0, false);
return null;
catch (TypeNotPresentException var20)
if (var3)
throw var20;
skipAnnotation(var0, false);
return null;
if (var4 != null && !contains(var4, var6))
skipAnnotation(var0, false);
return null;
else
AnnotationType var8 = null;
try
var8 = AnnotationType.getInstance(var6);
catch (IllegalArgumentException var17)
skipAnnotation(var0, false);
return null;
Map var9 = var8.memberTypes();
LinkedHashMap var10 = new LinkedHashMap(var8.memberDefaults());
int var11 = var0.getShort() & '\\uffff';
for(int var12 = 0; var12 < var11; ++var12)
int var13 = var0.getShort() & '\\uffff';
String var14 = var1.getUTF8At(var13);
Class var15 = (Class)var9.get(var14);
if (var15 == null)
skipMemberValue(var0);
else
Object var16 = parseMemberValue(var15, var0, var1, var2);
if (var16 instanceof AnnotationTypeMismatchExceptionProxy)
((AnnotationTypeMismatchExceptionProxy)var16).setMember((Method)var8.members().get(var14));
var10.put(var14, var16);
return annotationForMap(var6, var10);
最终我们可以看到调用annotationForMap方法返回了一个Annotation对象
public static Annotation annotationForMap(final Class<? extends Annotation> var0, final Map<String, Object> var1)
return (Annotation)AccessController.doPrivileged(new PrivilegedAction<Annotation>()
public Annotation run()
return (Annotation)Proxy.newProxyInstance(var0.getClassLoader(), new Class[]var0, new AnnotationInvocationHandler(var0, var1));
);
看到这,很显然 获取Annotation最终是使用动态代理实例化了一个注解的接口返回;
而AnnotationInvocationHandler做的事情很简单,举上面的例子,当我们调用((Ann0tation)anno).attr()时,AnnotationInvocationHandler直接从memberValues这个map取出来并返回,而这个map就是通过解析RuntimeVisibleAnnotations得到并传给AnnotationInvocationHandler的。
注解主要区分为两大类:编译时注解和运行时注解
保留阶段不同,编译时注解保留到编译时,运行时无法访问。运行时注解保留到运行时,可在运行时访问。
根据其保存的阶段,也区分了这两者不同的使用
编译时注解
编译时注解 由于主要使用是在编译阶段,那么我们在这个状态主要使用就是通过APT javaopet ASM 反射等技术在
编译阶段获取到注解和被注解对象的相关信息,在拿到这些信息后我们可以根据需求来自动的生成一些代
码,省去了手动编写。注意,获取注解及生成代码都是在代码编译时候完成的,相比反射在运行时处理注解
大大提高了程序性能。APT的核心是AbstractProcessor类
APT 用来在编译时期扫描处理源代码中的注解信息,我们可以根据注解信息生成一些文件,比如 Java
文件。利用 APT 为我们生成的 Java 代码,实现冗余的代码功能,这样就减少手动的代码输入,提升了
编码效率,而且使源代码看起来更清晰简洁
因此APT技术被广泛的运用在Java框架中,比如:ButterKnife之外、Dagger2以及阿里
的ARouter路由框架等都运用到APT技术
运行时注解
运行时注解就是就是运行时运用反射,动态获取对象、属性、方法等,一般的IOC框架就是这样,可能会牺
牲一点效率,在一些比如Retrofit Glid EventBus 等框架中有广泛的使用
由于使用Java反射,因此对性能上有影响
注解处理器(APT)
1. 什么是APT
APT即为Annotation Processing Tool;
它是javac的一个工具,中文意思为编译时注解处理器。
APT 存在于Java 5,但是主要API在java 6才加入,主要用来在编译时扫描和处理注解信息 ;
通过APT可以获取到注解和被注解对象的相关信息,在拿到这些信息后我们可以根据需求来自动的生成一些代码,省去了手动编写。注意,获取注解及生成代码都是在代码编译时候完成的,相比反射在运行时处理注解大大提高了程序性能。APT的核心是AbstractProcessor类;
2. APT的使用场景
APT技术被广泛的运用在Java框架中,包括android项以及Java后台项目,除了上面我们提到的ButterKnife之外,像EventBus 、Dagger2以及阿里的ARouter路由框架等都运用到APT技术;
3. 怎么使用APT
-
新建Java Library模块
自定义注解处理器的类必须是在java工程,所以,要在AS中使用APT,首先必须新建一个Java Library模块
为什么?
因为APT是javac的一个工具,如果不适用 apply plugin: ‘java-library’ 会找不到AbstractProcessor 类 -
引入auto-service依赖库
compile 'com.google.auto.service:auto-service:1.0-rc2'使用注解处理器需要先声明,也就是将注解处理器注册到javac中
具体步骤:
1、需要在 processors 库的 main 目录下新建 resources 资源文件夹;
2、在 resources文件夹下建立 META-INF/services 目录文件夹;
3、在 META-INF/services 目录文件夹下创建 javax.annotation.processing.Processor 文件;
4、在 javax.annotation.processing.Processor 文件写入注解处理器的全称,包括包路径;)
内容如下:每一个元素换行分割:
com.eric.myprocess.MyProcessorA
com.eric.myprocess.MyProcessorB但是如果使用auto-service库,使用@AutoService注解声明就可以自动完成以上APT的声明步骤。
注意:在Gradle 5.5以上 使用AutoService会存在一些兼容性问题,此时需要使用手动创建完成 -
自定义注解处理器实战
- 构建一个自定义注解
建议将需要注解处理器处理的所有自定义注解放在一个独立的java Module里面
如图实例:
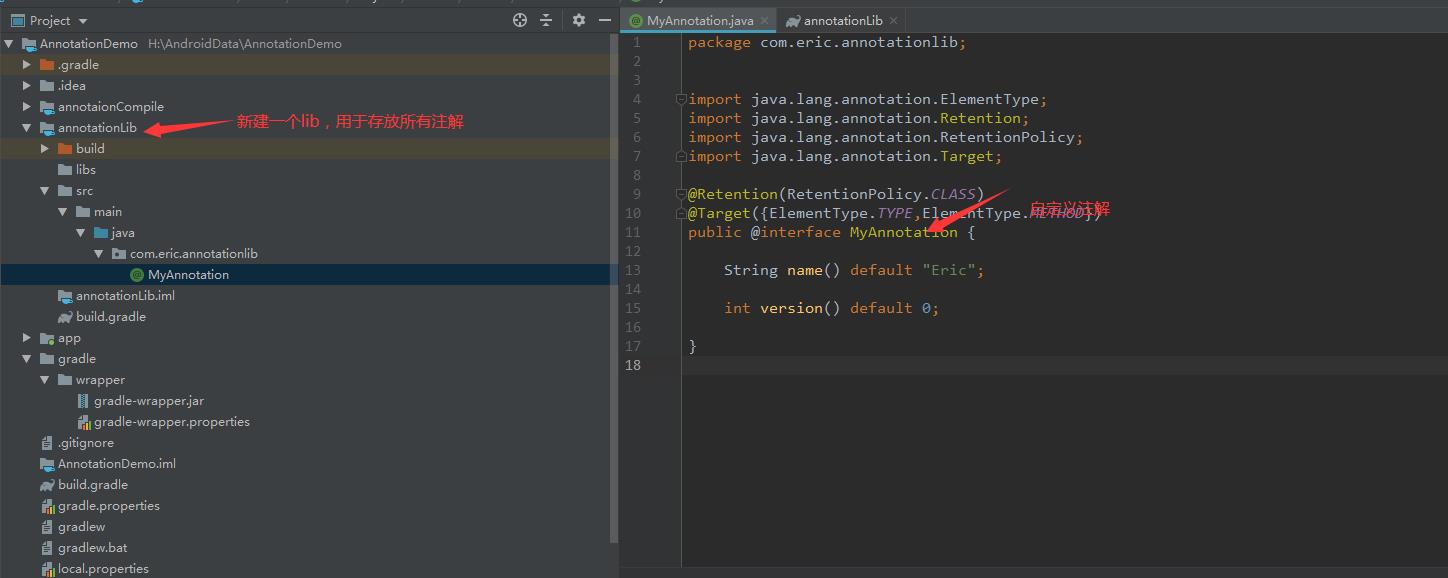
- 新建一个注解处理器的module,该module必须是一个java Module,并且依赖auto-service库,以便协助我们完成APT的声明
如图所示:
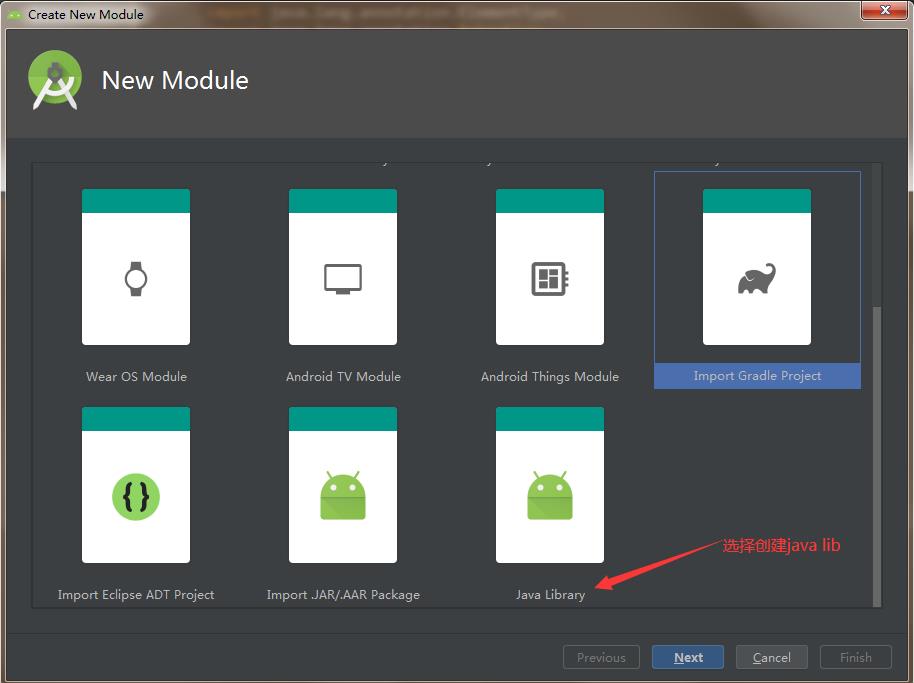

- 创建自定义注解处理器
package com.eric.lib; import com.eric.annotationlib.MyAnnotation; import com.google.auto.service.AutoService; import java.util.HashSet; import java.util.LinkedHashSet; import java.util.Set; import javax.annotation.processing.AbstractProcessor; import javax.annotation.processing.Messager; import javax.annotation.processing.ProcessingEnvironment; import javax.annotation.processing.Processor; import javax.annotation.processing.RoundEnvironment; import javax.lang.model.SourceVersion; import javax.lang.model.element.Element; import javax.lang.model.element.ElementKind; import javax.lang.model.element.TypeElement; import javax.lang.model.util.Elements; import javax.tools.Diagnostic; @AutoService(Processor.class)//通过在注解处理器上增加AutoService实现自动的声明 public class ActivityProcessor extends AbstractProcessor //继承AbstractProcessor 自定义一个注解处理器 private Elements mElementUtils;//处理Element的工具类 private Messager messager;//日志工具 @Override public synchronized void init(ProcessingEnvironment processingEnvironment) super.init(processingEnvironment); //processingEnvironment.getElementUtils(); 处理Element的工具类,用于获取程序的元素,例如包、类、方法。 //processingEnvironment.getTypeUtils(); 处理TypeMirror的工具类,用于取类信息 //processingEnvironment.getFiler(); 文件工具 //processingEnvironment.getMessager(); 错误处理工具 mElementUtils = processingEnv.getElementUtils(); messager = processingEnvironment.getMessager(); @Override public Set<String> getSupportedOptions() return super.getSupportedOptions(); @Override public Set<String> getSupportedAnnotationTypes() //大部分class而已getName、getCanonicalNam这两个方法没有什么不同的。 //但是对于array或内部类等就不一样了。 //getName返回的是[[Ljava.lang.String之类的表现形式, //getCanonicalName返回的就是跟我们声明类似的形式。 HashSet<String> supportTypes = new LinkedHashSet<>(); supportTypes.add(MyAnnotation.class.getCanonicalName()); return supportTypes; //因为兼容的原因,特别是针对Android平台,建议使用重载getSupportedAnnotationTypes()方法替代默认使用注解实现 @Override public SourceVersion getSupportedSourceVersion() return SourceVersion.latest(); @Override public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) System.out.println("ActivityProcessor process"); //真正的注解处理部分 for(Element element : roundEnvironment.getElementsAnnotatedWith(MyAnnotation.class)) if(element.getKind() == ElementKind.FIELD) messager.printMessage(Diagnostic.Kind.NOTE,"printMessage : " + element.toString()); return false;-
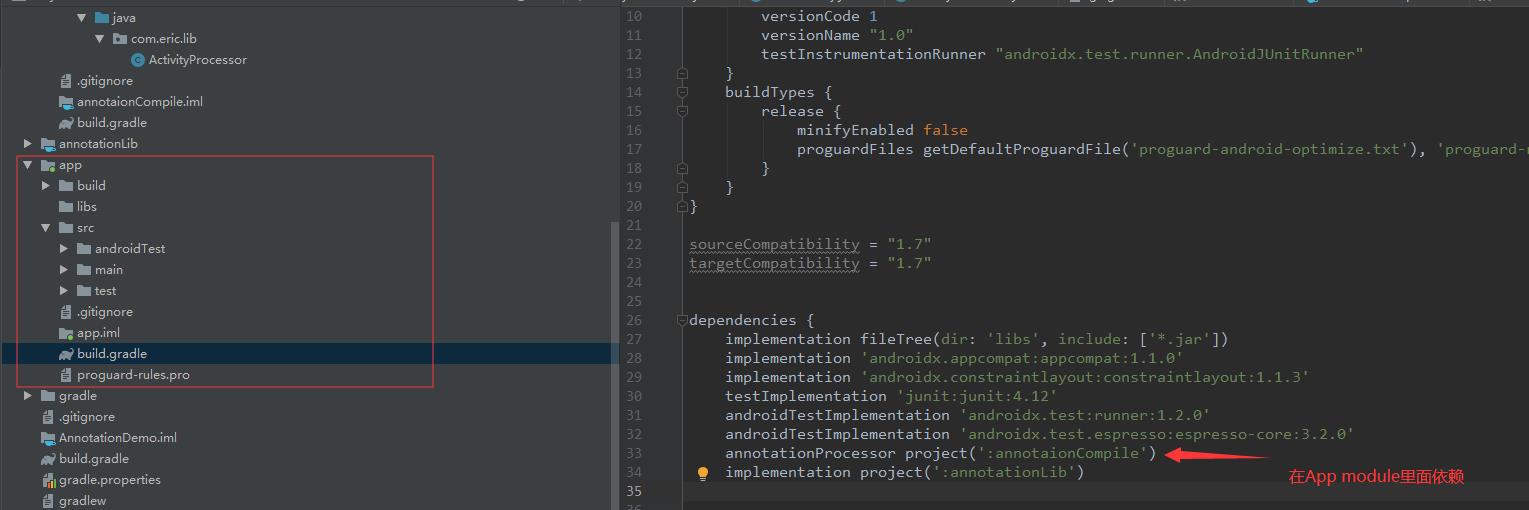
依赖注解处理模块并编译
依赖注解处理模块
如图:
编译后我们可以看到:
如图在指定路径下自动生成了注解处理器的声明文件
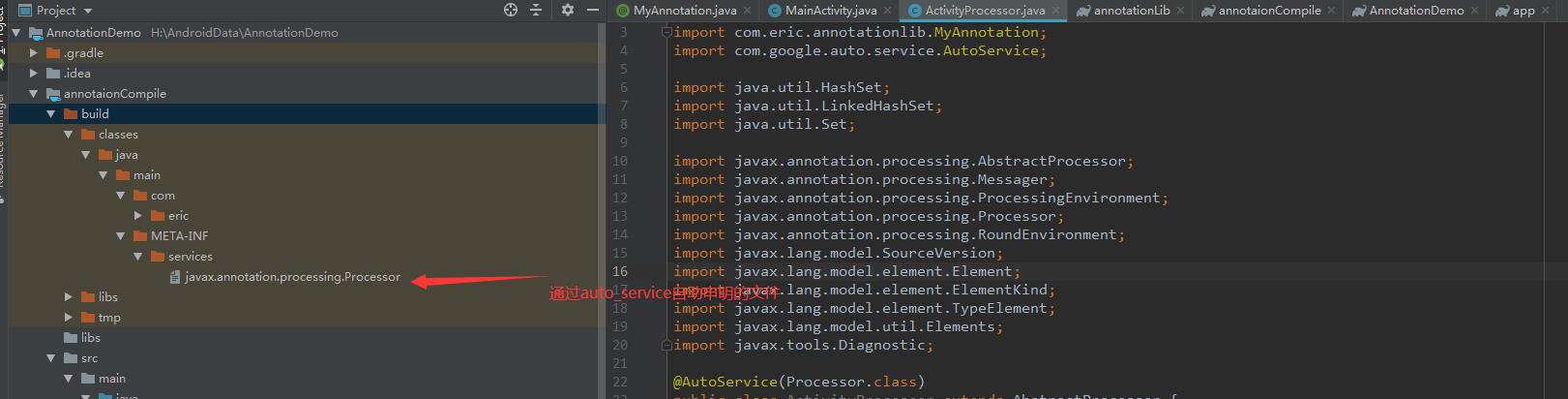
具体如何生成声明文件的过程,从注解申明到生成配置文件,我们可以猜到,肯定也是通过注解处理器搭配动态生成代码或者文件的工具库实现的
具体的原理以及流程请参考Google开源库AutoService的原理 -
看编译输出日志
很显然注解处理器执行的时候是在编译环节,也就是说主要用于编译时注解,并且是在Task :app:compileDebugJavaWithJavac这个任务之后才执行
如图:
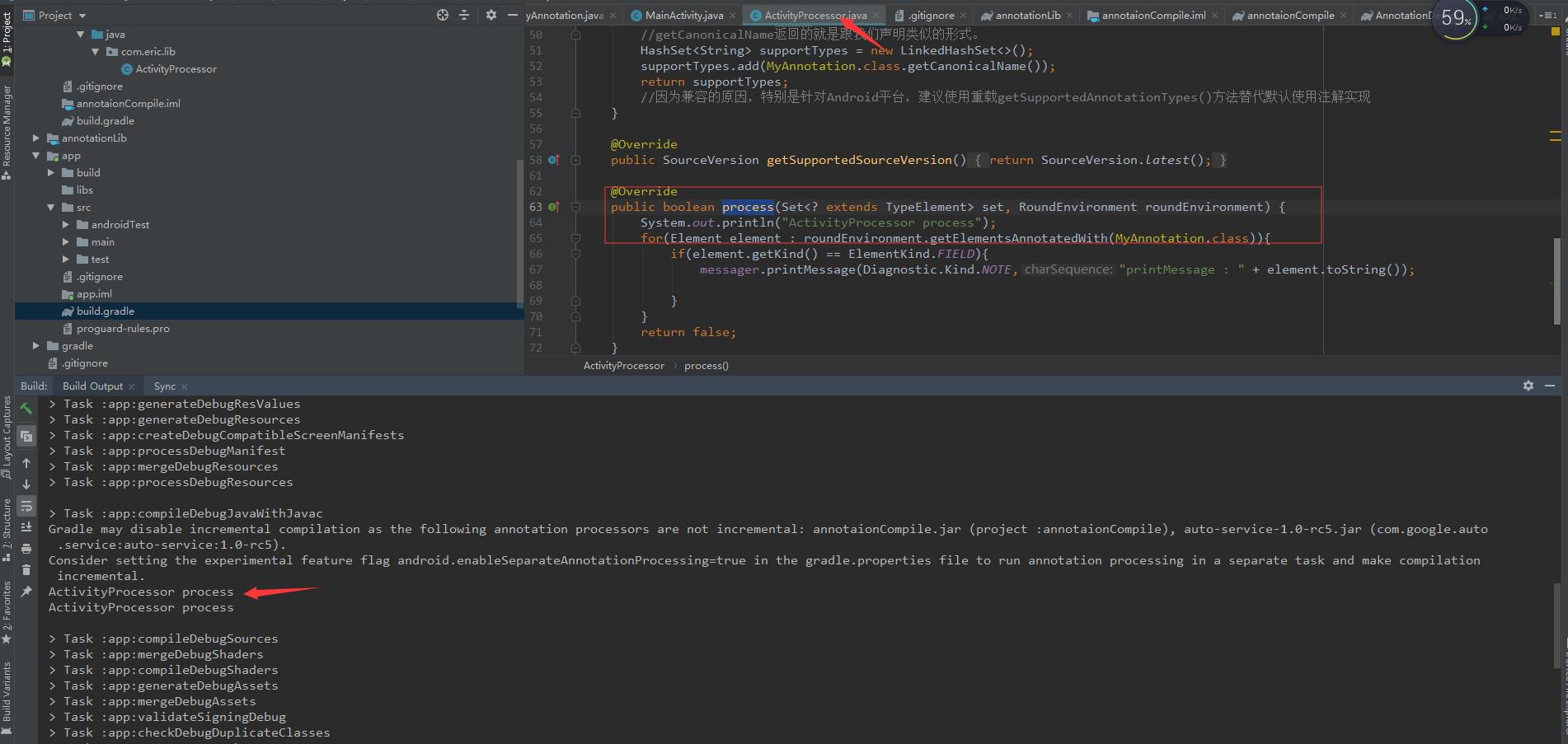
更具体的APT使用分析,也可以参考Java注解知识梳理—自定义注解处理器
- 构建一个自定义注解
动态字节码生成方法
这里只简单介绍下几种生成的工具库,不介绍详细使用方法,后续可能会更新具体的使用;
- JDK提供的动态代理
- JavaPoet
使用可以参考JavaPoet动态生成代码 - cglib
- Javassist
- ASM
这里我就只介绍上面这几种,具体的使用的区别,推荐大家可以看看这篇博文,相信会有比较大的帮助
Java动态代理:JDK 和CGLIB、Javassist、ASM之间的差别 (详细)
以上是关于注解第二部分原理分析和注解处理器的主要内容,如果未能解决你的问题,请参考以下文章