Python3 使用beautifulsoup解析微信文章
Posted 起名字是很难的事
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python3 使用beautifulsoup解析微信文章相关的知识,希望对你有一定的参考价值。
1.微信文章内容结构分析
注:只能采集图文文章,视频、语音无法采集
1)分享相关
<meta property="og:title" content="微信分享标题" />
<meta property="og:url" content="分享链接" />
<meta property="og:image" content="分享图片url" />
<meta property="og:description" content="分享描述" />2)文章结构
<body id="activity-detail" class="zh_CN wx_wap_page appmsg_desktop_fontsize_2 mm_appmsg discuss_tab appmsg_skin_default appmsg_style_default ">
<!--body的id为activity-detail-->
<div id="js_article" class="rich_media">
<!--js_article用来存储文章信息-->
<div id="js_top_ad_area" class="top_banner"></div>
<div class="rich_media_inner">
<div id="page-content" class="rich_media_area_primary">
<div id="img-content" class="rich_media_wrp">
<h2 class="rich_media_title" id="activity-name"></h2>
<!--文章标题,id="activity-name"-->
<div id="meta_content" class="rich_media_meta_list">
<div id="js_tags" class="article-tag__list" style="display: none;" data-len="0">
<div class="rich_media_content " id="js_content" style="visibility: visible;">
<!--正文内容,id="js-content"-->
<div id="js_sponsor_ad_area" style="display: none;"></div>
<div class="read-more__area" id="js_more_read_area" style="display:none;">
<div id="js_tags_preview_toast" class="article-tag__error-tips" style="display: none;">预览时标签不可点</div>
<ul id="js_hotspot_area" class="article_extend_area"></ul>
<div id="js_album_keep_read" class="appmsg_card_context album_read_card" style="display: none;">
<div class="rich_media_tool" id="js_toobar3">
<div class="like_comment_wrp" id="js_like_comment" style="display: none;">
<div style="display:none;" id="wow_close_inform">
<div id="js_like_toast" style="display: none;">
<div style="display: none;" id="js_comment_panel">
<div id="js_loading" style="display: none;">
<div class="rich_media_area_primary sougou" id="sg_tj" style="display:none"></div>
<div class="rich_media_area_extra">
<div id="js_pc_qr_code" class="qr_code_pc_outer" style="display: block;">3)作者信息
<!-- 公众号作者信息 -->
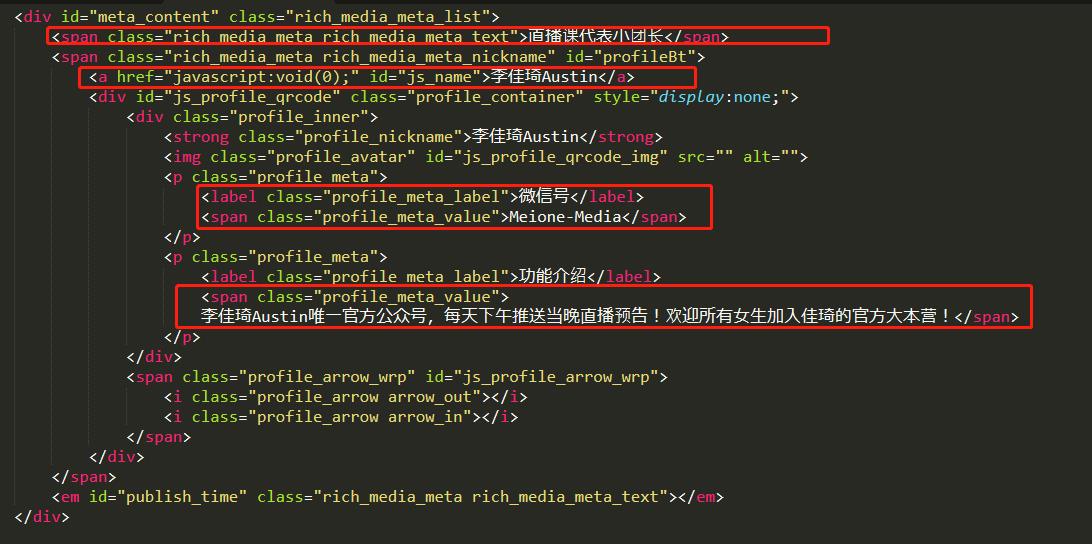
<div id="meta_content" class="rich_media_meta_list">
<span class="rich_media_meta rich_media_meta_text">直播课代表小团长</span> <!--作者名字,可能没有 -->
<span class="rich_media_meta rich_media_meta_nickname" id="profileBt">
<a href="javascript:void(0);" id="js_name">公众号名称</a>
<div id="js_profile_qrcode" class="profile_container" style="display:none;">
<!-- 公众号信息 -->
<div class="profile_inner">
<strong class="profile_nickname">公众号名字</strong>
<img class="profile_avatar" id="js_profile_qrcode_img" src="" alt="">
<p class="profile_meta">
<label class="profile_meta_label">微信号</label>
<span class="profile_meta_value">rmrbwx</span><!--公众号的微信号 -->
</p>
<p class="profile_meta">
<label class="profile_meta_label">功能介绍</label>
<span class="profile_meta_value">参与、沟通、记录时代。</span> <!--公众号的功能描述 -->
</p>
</div>
<span class="profile_arrow_wrp" id="js_profile_arrow_wrp">
<i class="profile_arrow arrow_out"></i>
<i class="profile_arrow arrow_in"></i>
</span>
</div>
</span>
<em id="publish_time" class="rich_media_meta rich_media_meta_text"></em>
</div>公众号及作者信息:在<div id="meta_content">中。
文章作者
(有的文章可能没有设置作者,非原创标志):<div id="meta_content">-----<span class="rich_media_meta rich_media_meta_text">
<span class="rich_media_meta rich_media_meta_text">直播课代表小团长</span>(认证了“原创”的文章的作者)<div id="meta_content">-----<span class="rich_media_meta rich_media_meta_text">------<div id="js_author_name">
<span class="rich_media_meta rich_media_meta_text">
<span id="js_author_name" class="" datarewardsn="" datatimestamp=""datacanreward="0">作者名字</span> </span>公众号名称:<div id="meta_content">----- <span id="profileBt">------ <a id="js_name">
公众号的微信号:<div id="meta_content">----- <span id="profileBt">------<div js_profile_qrcode> ------<p class="profile_meta">(第一个)------<span class="profile_meta_value">
公众号的介绍:<div id="meta_content">----- <span id="profileBt">------<div js_profile_qrcode> ----<div class="profile_inner">------<p class="profile_meta">(第二个)------<span class="profile_meta_value">
2.开始采集
1)获取文章源代码:
import requests
from bs4 import BeautifulSoup
html=requests.get(url).text #采集文章内容
soup = BeautifulSoup(html, 'lxml') #建一个BeautifulSoup对象
2)分享信息
# share_title = soup.find_all(property='og:title') #分享标题,返回的列表,实际中只有一条,用find()更合适
share_title = soup.find(property='og:title') #分享标题行
share_title_con = share_title.get('content') #分享标题文本
# print(share_title_con)
share_url = soup.find(property='og:url') #分享url行
share_url_con = share_url.get('content') #分享url地址文本
# print(share_url_con)
share_desc = soup.find(property='og:description') #分享描述行
share_desc_con = share_desc.get('content') #分享描述文本
# print(share_desc_con)
share_img = soup.find(property='og:image') #分享头图行
share_img_con = share_img.get('content') #分享头图地址,微信有防盗链机制,所以图片需要下载到本地
3)内容处理
文章有效内容在<body id="activity-detail'>中
body = soup.find(id='activity-detail') #body标题(id='activity-name'),内容(id='activity-name')
title = body.find(id='activity-name') #标题(带html标签的内容)
title_txt = title.get_text() #标题的文本
tags = body.find(id='js_tags') #话题(带html标签),有的文章在标题作者与正文中间,有一组收录于**话题
content = body.find(id="js_content") #文章正文内容
print(content.prettify()) #格式化输出内容
图片处理
1.微信文章的图片设置了延迟加载,真正的图片地址保存在<img data-src="">中;
2.图片有防盗链机制,不能直接使用原文件地址,需要保存到本地。
imgs = content.find_all('img') #文章中的所有图片
for img in imgs:
if img.get('data-src'):
new_src = download_img(img.get('data-src'))[0]
img['data-src'] = new_src #前端图片展示时需要用延迟加载
print(img)
import urllib.request as request
import os
from hashlib import sha1
def download_img(imgurl):
#将图片保存到本地
path = '/home/wang/images/'
if not os.path.exists(path):
os.makedirs(path)
s1 = sha1() #创建sha1加密对象
s1.update(imgurl.encode("utf-8"))
_imgurl = s1.hexdigest()
imgpath = path + '//' + _imgurl
#imgpath = path + '//' + os.path.split(imgurl)[1]
local_img_url = request.urlretrieve(imgurl, imgpath)
return local_img_url4)公众号及作者信息处理
name = soup.select('#meta_content > span.rich_media_meta_text')
if len(name) > 0:
author_name = name[0].get_text() #作者名字
print(author_name)公众号信息
#直接soup筛选公众号名字
wx_account_name = soup.select('#meta_content > #profileBt > #js_name')[0].get_text() #微信公众号的名字
wx_account = soup.find(id="meta_content")
wx_account_name = wx_account.select('#profileBt > #js_name')[0].get_text() #微信公众号的名字
wx_account_content = wx_account.select('#profileBt > #js_profile_qrcode > .profile_inner > .profile_meta') #获得列表,内容依次为公众号微信名,公众号描述
wx_account_account = wx_account_content[0].select('.profile_meta_value')[0].get_text() #公众号微信名
wx_account_desc = wx_account_content[1].select('.profile_meta_value')[0].get_text() #公众号描述
以上是关于Python3 使用beautifulsoup解析微信文章的主要内容,如果未能解决你的问题,请参考以下文章