C开源项目-TinyHttp解读(下)
Posted 用七年单身换个PolyU.CSPhD
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C开源项目-TinyHttp解读(下)相关的知识,希望对你有一定的参考价值。
中上小结
前面两部分,我们主要分析了服务器端的一些基本功能和义务。
服务器端要把自己绑定到一个众所周知的端口上去,要去监听客户端的请求。服务器端要学会辨认客户端发送来的Http报文头,识别两种主要方法“GET、POST”,可以发送一些不同的应答报文(此处以代码表示)“404,200”。
千万不要担心我们迟迟未分析simpleclient,其用到的我们在server全看过的。
cgi是什么
我也不知道,我也是现看的,还处于一知半解状态。
传送门:CGI是什么
官方地下个定义:CGI是通用网关接口。
学过计网的话会知道以前的服务器会存储一些静态的html文件,客户端要求要了就给他,但现在更多的有动态需求、需要现场生成。我们的服务器做不到,就通过CGI程序代劳,我觉得上面的博客中的这张图比较好:
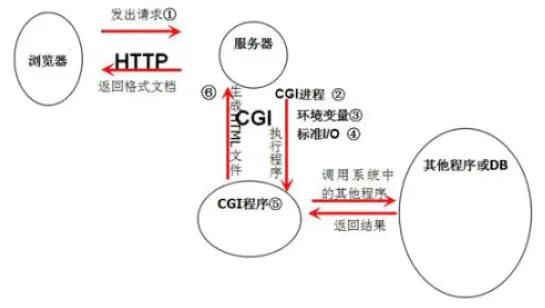
也就是服务器没法直接去数据库(DB)或者其他的啥的给用户返回了,就找CGI去调用。博客中的有一句话涉及了我们CGI的实现机理(图中也有),所以需要记一记:
服务器要解析出HTTP请求的正文内容写入到CGI程序的标准输入(stdin)中,CGI程序的标准输出(stdout)就作为服务器的返回(应答报文[Response])。
代码分析
我们主要只剩下一个execute_cgi了,比较长,分两块解决。
1.处理报文头(客户端发送的服务请求)阶段
/**********************************************************************/
/* Execute a CGI script. Will need to set environment variables as
* appropriate.
* Parameters: client socket descriptor
* path to the CGI script */
/**********************************************************************/
void execute_cgi(int client, const char *path,
const char *method, const char *query_string)
char buf[1024];
int cgi_output[2];
int cgi_input[2];
pid_t pid;
int status;
int i;
char c;
int numchars = 1;
int content_length = -1;
buf[0] = 'A'; buf[1] = '\\0';
if (strcasecmp(method, "GET") == 0)
while ((numchars > 0) && strcmp("\\n", buf)) /* read & discard headers */
numchars = get_line(client, buf, sizeof(buf));
else if (strcasecmp(method, "POST") == 0) /*POST*/
numchars = get_line(client, buf, sizeof(buf));
while ((numchars > 0) && strcmp("\\n", buf))
buf[15] = '\\0';
if (strcasecmp(buf, "Content-Length:") == 0)
content_length = atoi(&(buf[16]));
numchars = get_line(client, buf, sizeof(buf));
if (content_length == -1)
bad_request(client);
return;
else/*HEAD or other*/
同样地,先略过变量声明。
看到这个while循环和要做的事,是不是已经烂熟于心了呢?
while ((numchars > 0) && strcmp("\\n", buf))
numchars = get_line(client, buf, sizeof(buf));
就是没读完就一行一行读完为止呗,此循环的注释也比较生动:
// read & discard headers -> 读取然后扔掉这个报文头
这是我们的请求方法为GET时的情况,因为此时的参数已经被我们包含在query_string里了,因此我们已经把该拿的都拿到了,直接舍弃报文头没问题!
当我们为POST请求方法时:
我们同样是一行一行地读取,并且最后也是读完并舍弃这个报文头,值得注意的是当我们读到“Content-Length:”行时要把这个长度进行记录!
这里附上一个看GET和POST报文格式的博客链接,我没有WireShark了。。
GET和POST报文格式
2.处理应答报文阶段【重要!】
if (pipe(cgi_output) < 0)
cannot_execute(client);
return;
if (pipe(cgi_input) < 0)
cannot_execute(client);
return;
if ( (pid = fork()) < 0 )
cannot_execute(client);
return;
sprintf(buf, "HTTP/1.0 200 OK\\r\\n");
send(client, buf, strlen(buf), 0);
if (pid == 0) /* child: CGI script */
char meth_env[255];
char query_env[255];
char length_env[255];
dup2(cgi_output[1], STDOUT);
dup2(cgi_input[0], STDIN);
close(cgi_output[0]);
close(cgi_input[1]);
sprintf(meth_env, "REQUEST_METHOD=%s", method);
putenv(meth_env);
if (strcasecmp(method, "GET") == 0)
sprintf(query_env, "QUERY_STRING=%s", query_string);
putenv(query_env);
else /* POST */
sprintf(length_env, "CONTENT_LENGTH=%d", content_length);
putenv(length_env);
execl(path, NULL);
exit(0);
else /* parent */
close(cgi_output[1]);
close(cgi_input[0]);
if (strcasecmp(method, "POST") == 0)
for (i = 0; i < content_length; i++)
recv(client, &c, 1, 0);
write(cgi_input[1], &c, 1);
while (read(cgi_output[0], &c, 1) > 0)
send(client, &c, 1, 0);
close(cgi_output[0]);
close(cgi_input[1]);
waitpid(pid, &status, 0);
pipe单从单词是管道的意思,实际上我们也确实是这么来理解的,可以看看其注释是什么:创建一个单向通信通道,可以从[1]写入从[0]读出,返回-1的话说明出错了,现在可以返回去看看我们的cgi_output和cgi_input的类型哈。
出错的话是错在服务器本身而不是客户无理取闹,会执行一个cannot_execute函数。此函数的定义如下:
/**********************************************************************/
/* Inform the client that a CGI script could not be executed.
* Parameter: the client socket descriptor. */
/**********************************************************************/
void cannot_execute(int client)
char buf[1024];
sprintf(buf, "HTTP/1.0 500 Internal Server Error\\r\\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "Content-type: text/html\\r\\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "\\r\\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "<P>Error prohibited CGI execution.\\r\\n");
send(client, buf, strlen(buf), 0);
这里返回了一个新的代码,“500”,意思就是服务器自己炸了,其他的不赘述。
从pipe往下看,又是一个系统调用,这次是fork(),这个操作系统里一定学过!
就是创建一个进程,当前的为父进程,这个新创建的是子进程,子进程的所有资源都是copy父进程的。
上面这些系统调用一切正常情况下我们会先把代码“200”写入缓冲区中发送给客户端。接下来我们会根据依照父子进程的判断去做不同的事。
3.子进程做的事,pid=0时:
if (pid == 0) /* child: CGI script */
char meth_env[255];
char query_env[255];
char length_env[255];
dup2(cgi_output[1], STDOUT);
dup2(cgi_input[0], STDIN);
close(cgi_output[0]);
close(cgi_input[1]);
sprintf(meth_env, "REQUEST_METHOD=%s", method);
putenv(meth_env);
if (strcasecmp(method, "GET") == 0)
sprintf(query_env, "QUERY_STRING=%s", query_string);
putenv(query_env);
else /* POST */
sprintf(length_env, "CONTENT_LENGTH=%d", content_length);
putenv(length_env);
execl(path, NULL);
exit(0);
子进程做了重定向,就是把标准输入输入重定向(dup2)到我们的管道上,同时会添加环境变量(putenv)-----这玩意儿即使在Linux下自己可能用的不多我相信在Windows下肯定配过 。
execl就是带着参数运行指定文件,现在参数是NULL。path是我们的文件路径,是我们在解读【中】中提取出来的我们的客户端发送过来的(可能被我们修改成默认的index.html)的合法文件路径
4.父进程做的事
else /* parent */
close(cgi_output[1]);
close(cgi_input[0]);
if (strcasecmp(method, "POST") == 0)
for (i = 0; i < content_length; i++)
recv(client, &c, 1, 0);
write(cgi_input[1], &c, 1);
while (read(cgi_output[0], &c, 1) > 0)
send(client, &c, 1, 0);
close(cgi_output[0]);
close(cgi_input[1]);
waitpid(pid, &status, 0);
父进程做的事就是先关闭管道口。
(说实话我也不知道不关闭会咋样。。)
如果我们是POST方法的话就需要从客户端读取Content-Length长的参数,一边读一边写入到cgi_input端。
然后不断读取cgi_output端的信息并发送给客户端。最后关闭另外俩端口,并且要等待子进程退出回收其“资源”后才能真正退出。否则会有“孤儿进程”,也就是父亲死了,儿子还没运行完,具体在此环境下会产生何种问题我也没有尝试过。
测试结果
我就先不测试cgi的效果了,因为一下子没配好perl-cgi的环境。
此外,我们有一个返回代码500表示服务器出问题,这是基于pipe管道出问题或者说创建进程出问题的,我没有进行尝试,但pipe或许把传入的参数改掉就行?
看了Linux内核设计与实现,我觉得首先比较容易使fork出错的就是进程数超过了系统的最大限制,书上的是内核2.6版本说是不能超过几百个来着好像(当然我们的Ubuntu21内核版本5.x最大限制数都已经到400多w了几乎不大可能)。
看了别人的说法,觉得也非常有道理,超过系统内存也会失败。原因比较简单,也在上面简要介绍了,fork出的子进程完全拷贝父进程的资源,那么两个一加可能栈空间就受不了了,就炸了?
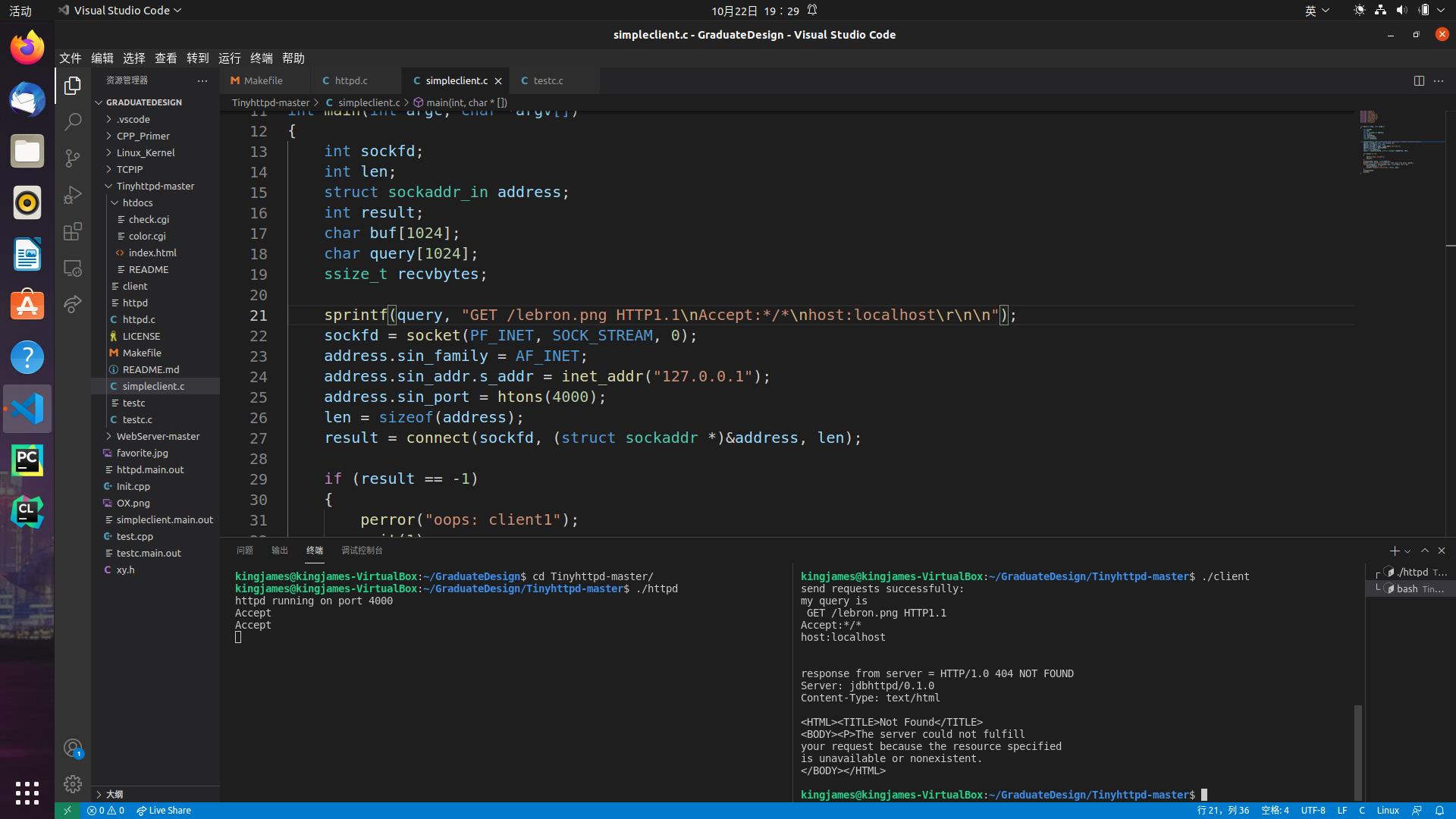
以下测试例子除了看终端返回响应报文不同外看看query的不同。
1.返回代码404,也就是“找不到网页”,我们的htdocs文件夹下只有index.html一个文件 (除了俩cgi脚本,我们不管它) ,我们可以随意命名一个文件来看结果。
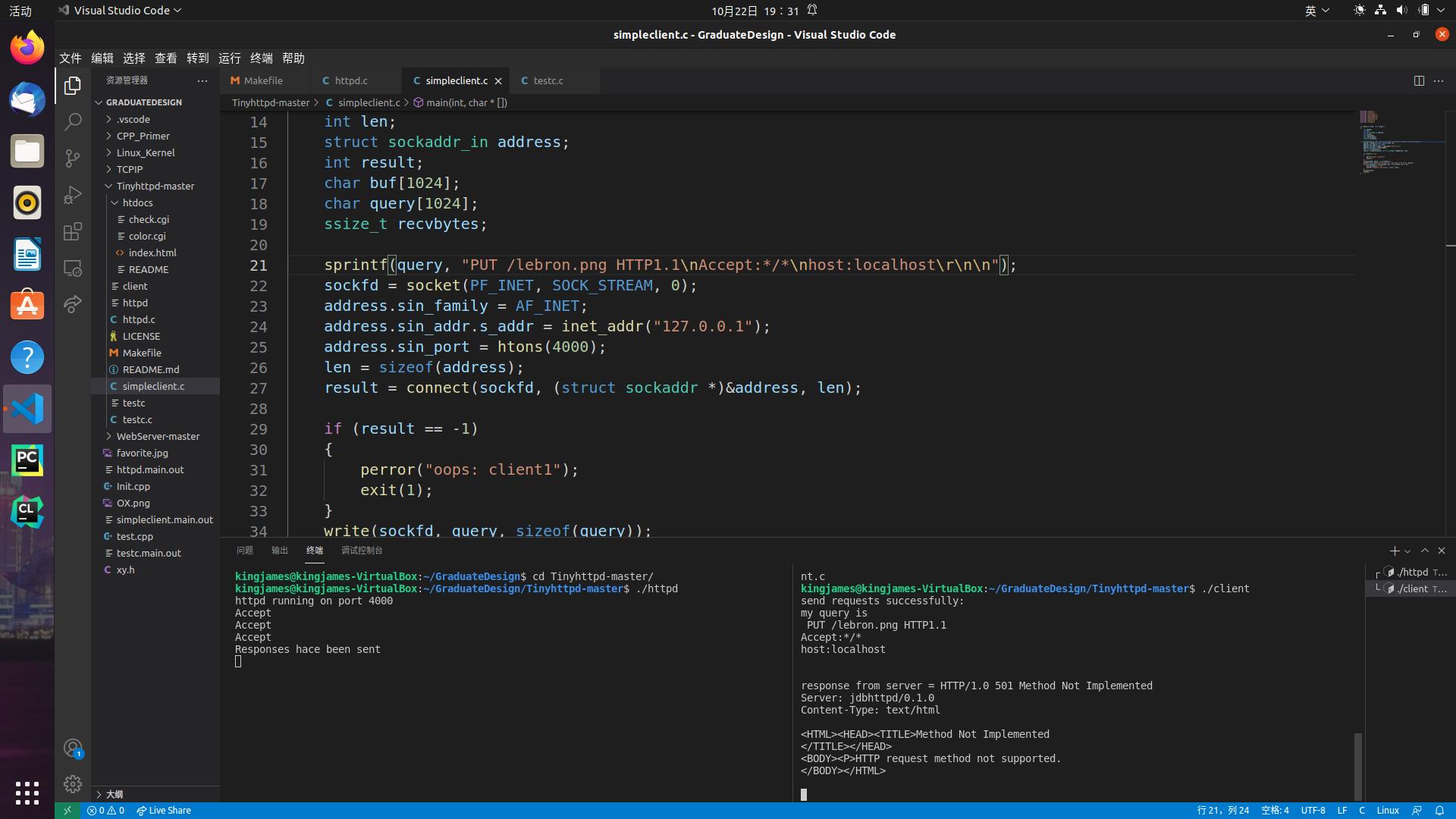
2.返回代码501,使用未实现的方法。
3.返回代码200,一切正常运行。
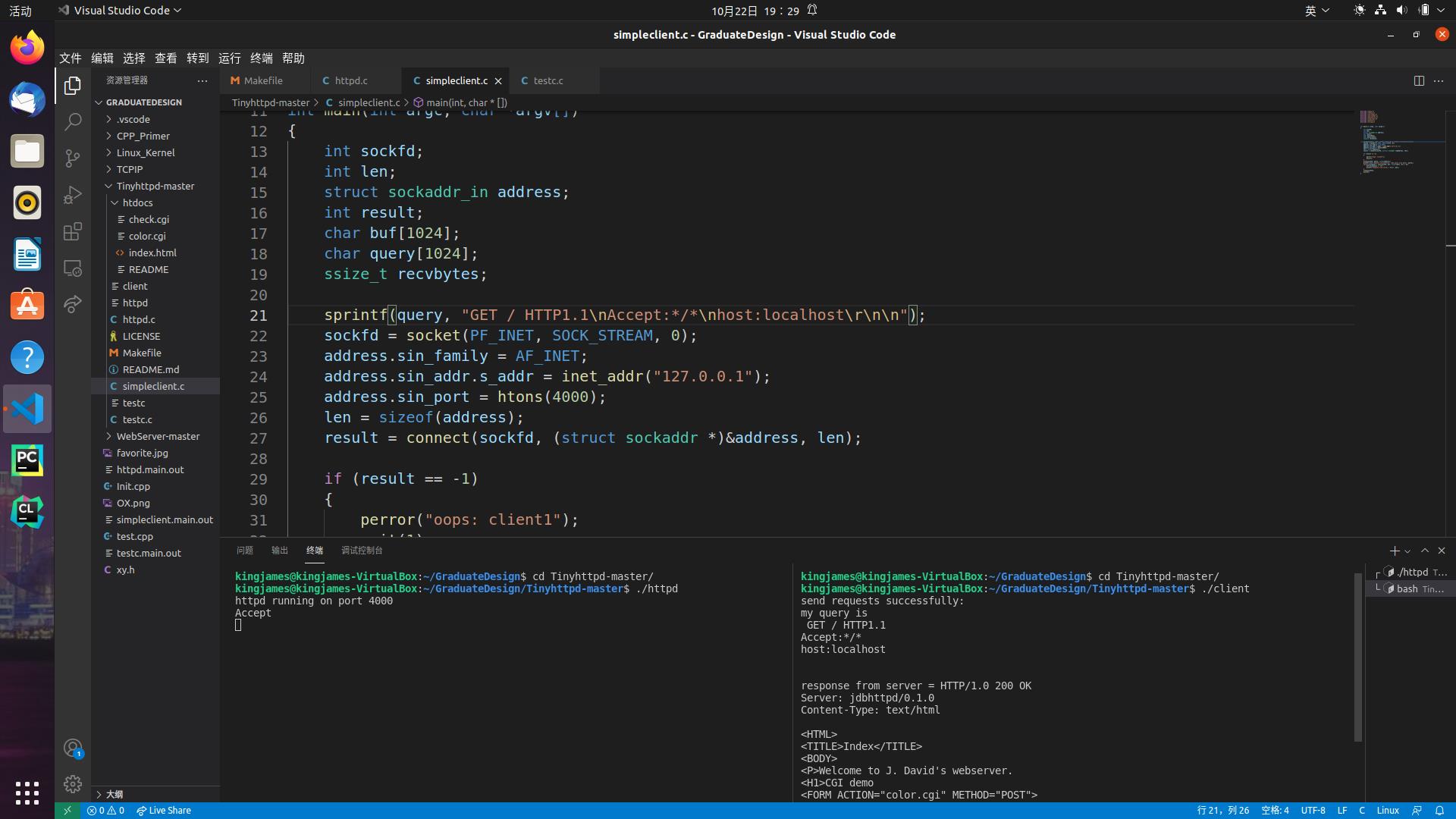
除上述外,还有更好的验证方式就是直接用浏览器进程访问我们的端口,如下:
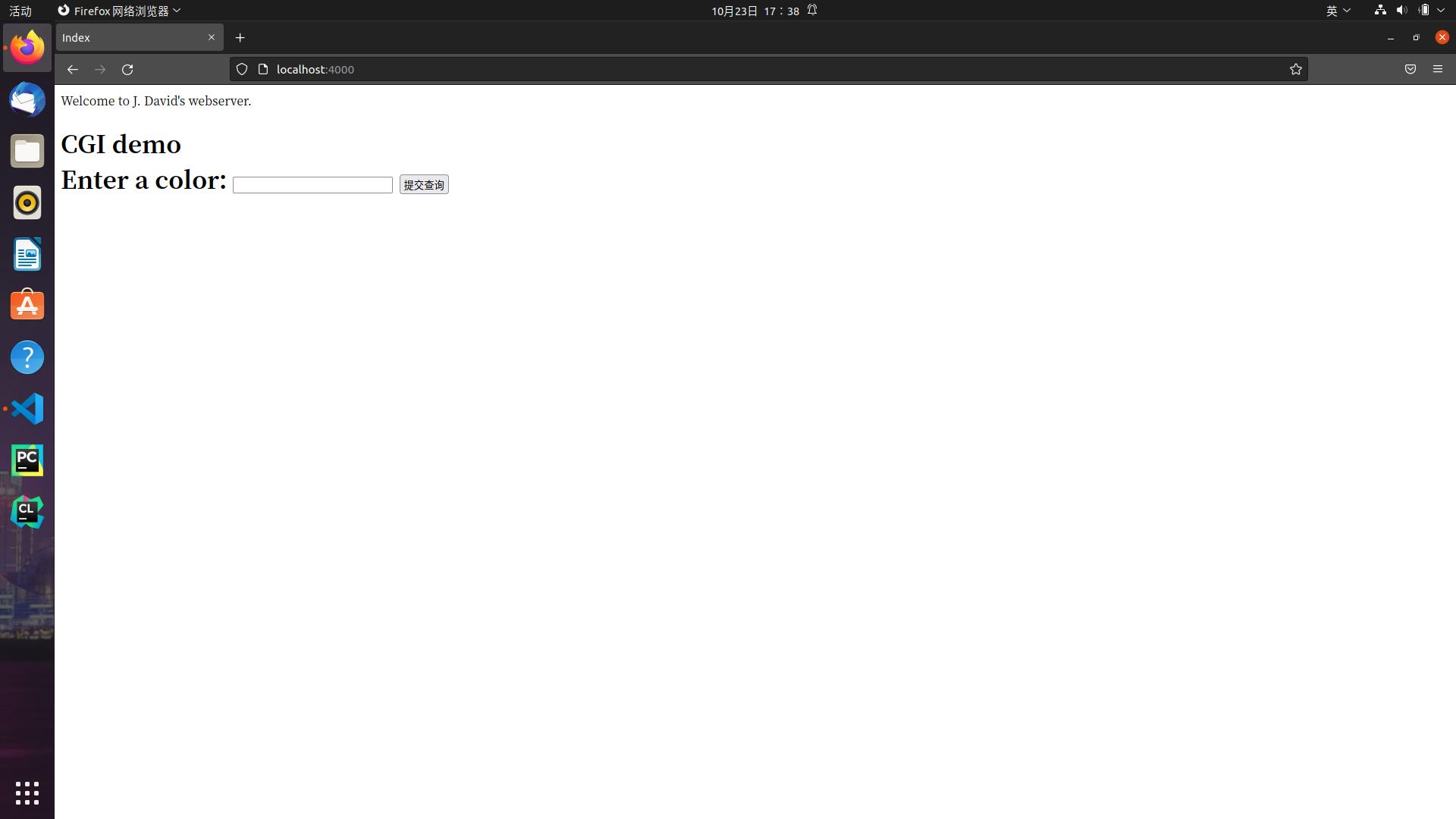
项目总结
设计方面不难,我们先从计算机网络角度来解析逻辑架构。
(一些关键地方用函数名代替,唤醒记忆,更加清晰)
Server:创建socket端口,进行绑定bind,监听此端口listen,同意Client的连接accept。取数据报,按行取get_line,其中需要调用recv逐字节地从缓冲区读出,返回各种类型的响应报文,send给Client。
Client:有许多是重复的事件,一个主要的不同就是调用connect,去尝试连接Server占用的端口!
以上是关于C开源项目-TinyHttp解读(下)的主要内容,如果未能解决你的问题,请参考以下文章