图解C/C++底层:函数栈帧的创建和销毁(下篇)
Posted Xy丶Promise
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解C/C++底层:函数栈帧的创建和销毁(下篇)相关的知识,希望对你有一定的参考价值。
函数栈帧的创建和销毁(下篇)
根据上篇的函数栈帧过程的学习,我们了解到:
-
什么是寄存器?
计算机的速度最快的存储单元,因为寄存器是集成在CPU之上的,与内存是不同的独立的存储空间。
-
什么是栈?
一种数据结构,数据依次放入栈内后,取出元素时顺序是最先进入的元素最后出;
函数的栈区是在操作系统级别上的,管理内存区,是主要运行在系统内存之上的。
-
函数栈帧的形成过程
函数栈帧的概念:
- 在寄存器内,EBP、ESP这2个寄存器中存放的是地址,这两个寄存器的指针是用来维护函数栈帧的。而这两个指针维护的内存空间就是一个函数的栈帧。
- 每一次函数调用时,都需要在栈区内创建一个空间,而创建的过程就是由这两个指针去实现的;调用了哪个函数,EBP、ESP两个指针地址就会去维护这个函数的内存空间,这就是函数的栈帧;例如main函数在运行过程的当中,esp和ebp两个指针地址会位于函数的它的栈顶和栈底。
函数栈帧的形成过程:
- 当程序发出调用函数操作时,ESP和EBP指针向低地址偏移初始化形成一块栈帧区域,并压入3个非易失寄存器压入栈帧区,ESP指针也随之向上变动;随后,程序会向低地址偏移0E4H个空间单位直至前面压入的ebx寄存器之下,并在这个空间内填满字符 0CCCCCCCCh,最终这个加载出来的有效空间就是一个函数真正意义上的栈帧有效空间,而这一片由0CCCCCCCCh字符填满的空间就是这个函数的作用域。此刻,栈帧的初始化真正完成,程序开始在这块区域内填入有效内容、例如声明变量。
-
函数变量的形成过程
在栈帧初始化完成后,每次声明变量都会以栈底指针EBP作为基准向上(低地址)偏移字节大小存放变量,依次叠加。变量申请后无法由用户主动释放。
本篇,我们将继续学习:函数的调用与传参的过程、新函数如何的栈帧建立、函数返回值与函数返回的实现(栈帧的销毁),函数形参的销毁与原函数获取返回值的过程。
汇编指令:调用函数与传参
程序的调用函数操作时如何进行的呢?接下来我们来看一看!
废话不多说,先看汇编指令:

前面讲解了这么多汇编指令,到这里看到的指令是不是开始按捺不住跳动的DNA了呢(bu)?
第一、第三句的mov,含义是将ebp-14h和ebp-8分别放到eax和ecx当中去,我们翻到上一步,看看ebp-14h和ebp-8是什么呢?根据栈底指针向低地址偏移观察可以看到,没错,就是我们a和b的值。这里是将a和b分别放入寄存器eax和ecx中去。
第二、第四局中的push,是压入栈的指令。分别将eax和ecx压入栈(别忘了每一次压入栈时,程序的栈顶指针也在变化哦),而eax和ecx现在里面是什么呢?不就是a和b的值吗?
此时顶部栈区的示意图应该如下
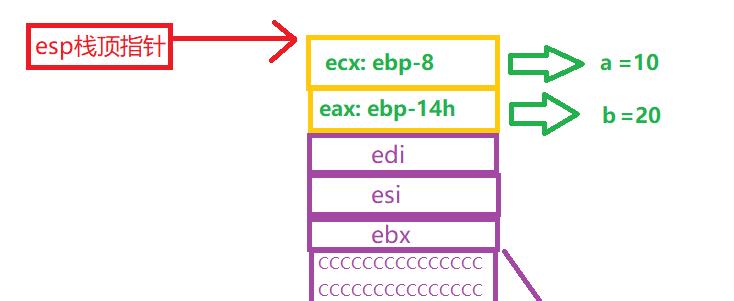
通过示例函数中我们可以看到。这4个动作是不是很像在进行传参前的准备呢?答案是确定的。那这样的放入和压入操作真的可以把参数传入函数嘛?调用函数又是如何使用我们的参数的呢?让我们继续往下看!
第五句,call实际上是一个转移指令,转移到另外一个区域内,同时为了执行转移后完成原区域的下一条指令,call指令会总是会将下一条指令压入栈区中,以此实现转移区内指令完成后返回至原地(简单来说,原地插个眼后传送去支援,最后还能传送回到线上。做到有去有回)。到这里,我们知道call指令会将原区域内的下一个指令的地址压入栈,所以栈顶应该就是下一条指令(00C21450) 的地址,打开内存和监视器确认果真如此

继续看,call指令的右边的一串标识,实际是call的“传送”位置,这个时候我们按下调试的F11进入到声明处,会看到声明处的指令。这里的jmp,就是跳入add函数当中去(本处只需了解jmp也是个转移操作,会在后续深挖细节)

接下来,我们继续往下走,欢迎来到Add函数的内部!!
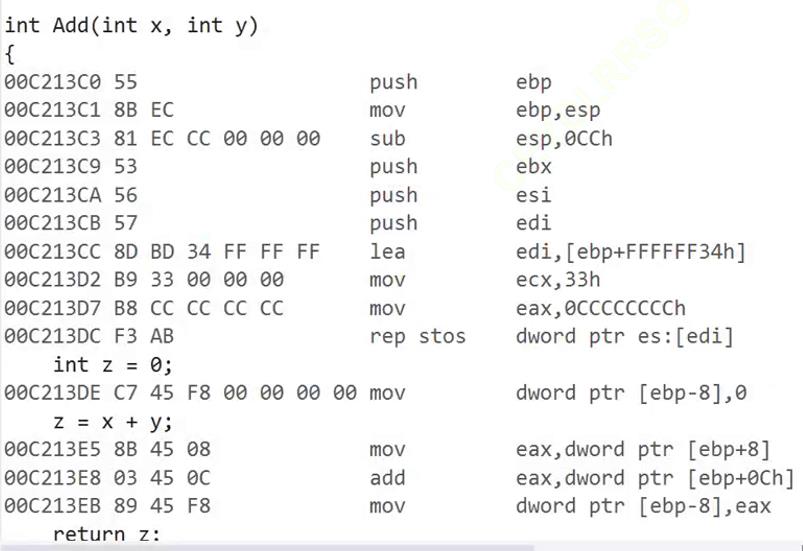
到这里函数的调用和传参操作已经完成了,我们可以总结出来的是:
-
传参时:程序在传参前会把要传入的参数先放入到寄存器当中,并将寄存器地址压入栈中。再观察他们的顺序 a->b,是由左往右依次压入栈的(示意图显示b在上,根据栈的先进后出原则证明b是后进的),同时栈顶指针在时刻变化。
-
调用函数时:在调用函数时,程序会使用call指令进入函数,call指令首先会将调用函数完成后的下一步指令压入栈区中,以此实现调用后返回至原函数继续执行内容的操作,接着就会根据标识进行转移,最后进入到新的函数中。
此时栈区顶部示意图应该如下

汇编指令:新函数的栈帧的生成
进入到Add函数内,观察到参数z形成前的所有代码,是不是有一种恍然之间中遇见前世的那个TA的一般似曾相识的感觉呢?
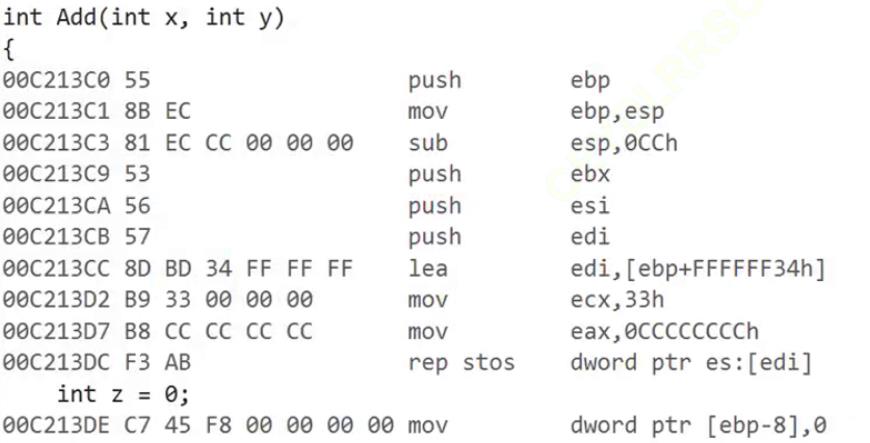
没错,这里是在将Add函数基础元素压入栈区并形成其作用域,最后生成这个函数内的局部变量;
这里唯一需要提醒的一点是,我们前面所提到的esp和ebp是用来维护当前运行函数的指针,而push ebp处,实际上是压入main函数的ebp栈底指针地址,以此实现ebp的转移以及函数运行完成后ebp返回原处。
下面一部分就是形成有效的Add函数栈帧区了,由此可以得到栈顶区域的示意图(画完才发现有点粉…粉色即正义!)

接下来,我们来观察新函数内是如何使用传入进来的参数的。
汇编指令:函数形参的使用
在开始学习C语言程序时,我们之前一直知道一个函数传参的理论:形参是实参的一份临时拷贝。现在我们来看看它是怎么执行的!
话不多说,上汇编指令!

观察这段汇编指令,ebp+8, ebp+0Ch,顺应十六进制转化就是ebp+8和ebp+12,结合当前ebp所指向的位置翻看栈帧区,这两个位置指向的是哪里呢?

没错,就是进入函数前就已经早早压入栈的函数形参。形参和实参在栈上是两个独立的个体存在,形参的改变不会影响到原来实参的改变,所以有形参是实参的一份临时拷贝。
汇编指令处,mov 会把ebp+8(a)的值放入寄存器eax中,add会把ebp+12(b)的值加进寄存器eax当中去,这也是程序实现加法的原理。
再看下一条,mov 将寄存器eax内的值放入到ebp-8的位置,ebp-8是什么?ebp-8就是z的值!此时它已经从0变成了30。
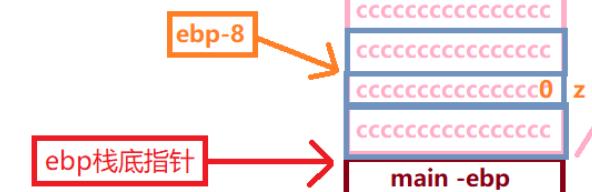
到这里我们可以看到,之所以说在一个函数内形参是实参的一份临时拷贝,是因为程序是不会主动创建的形参的,在我们调用这个函数之前程序就已经早早把将会用到的形参压入到栈上的,程序只要往前面去拿就可以拿到想要的形参值。这就是函数的形参使用原理。
汇编指令:函数返回值与函数返回的实现(栈帧的销毁)
我们前面看到,程序会把a+b的值结果赋值给z,再将z返回。按照我们之前所学的,程序会在出作用域内会将局部变量销毁,而z又是在新函数内临时生成的局部变量,那程序又是如何拿到z的返回值的呢?而程序在运行结束后,又是怎么将esp和ebp两个栈顶和栈顶指针回到原位,程序又是如何回到原函数内的下一条指令的呢?
接下来,我们继续通过汇编指令回答这一个问题。

前面带着你看了那么多汇编指令,现在5秒钟时间可以回到我第一句汇编指令是什么意思吗?5…4…3…2…1,答案没错,就是把ebp-8的值放入到eax当中去。而ebp-8的值就是刚刚z的位置,那么我们可以得到,函数的返回值,通常会放入到临时存放到寄存器eax当中去(为什么叫通常,因为超出寄存器大小时会借用其他的寄存器,比如esi)
再继续往下看,pop指令是什么意思呢(英文含义是什么)?pop指令出栈的意思,将元素弹出栈区以此释放掉。这里连续的3个pop,想想这是啥?是一个函数顶上的3个非易失寄存器。当函数要返回结束时,这3个寄存器会被弹出去。需要注意一点,弹出栈时esp的位置也在调整(向高地址挪动相加)
弹出栈前esp和ebp的值

弹出3个寄存器地址完成后。
程序要结束弹出栈区了,那我的esp和ebp指针是不是也要回到原地了呢?来下一句的mov esp,ebp,就是在调整esp和ebp的位置,将ebp的值给到esp。
此时,程序pop掉add函数内的ebp,这里的ebp是在进入Add函数时压入的栈的main函数ebp,那它是如何返回的呢?这需要提到pop指令的一个用法,pop指令可以实现用一个寄存器接收出栈的数据,此处的pop实际上就是将Add函数的ebp弹出后,又获取到原来压到栈上的main函数的ebp,做到ebp的跳转,这就是此处的pop ebp的作用。
到下面的ret,就比较有意思了。ret是什么意思呢?ret是将栈顶字单元出栈,其值赋给IP寄存器,实现了一个程序的转移。在汇编语言中,IP寄存器是表示即将执行的下一条指令的段内偏移地址。那现在栈顶元素是什么呢?

还记得现在栈顶的这个(00C21450)元素是什么嘛?如果不太了解,答案在这!这是在调用函数前,程序预留的call指令的下一条指令的地址。通过ret指令,程序已经回到main函数内部了。
到此,程序栈区示意图可以如下图
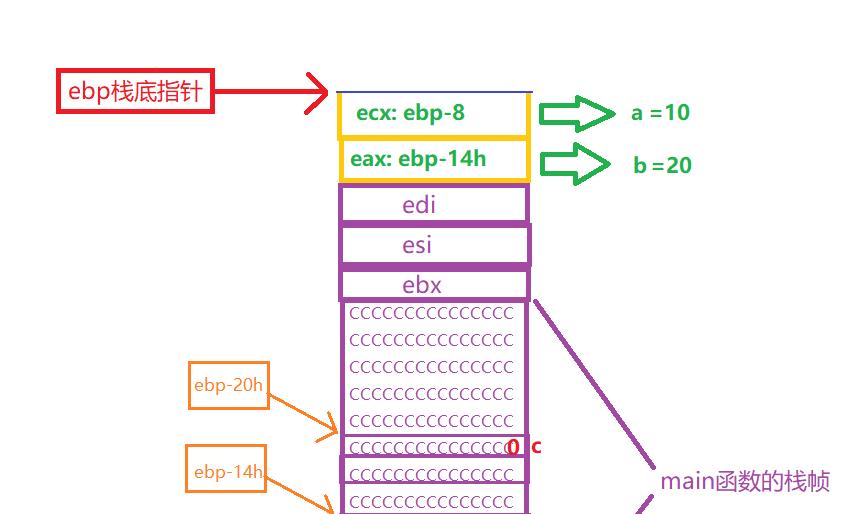
综上所述我们可以了解到:
- 函数返回值的操作是,会暂时将返回值放入到寄存器eax当中去。
- 当函数运行即将返回时,程序首先会销毁当前函数的局部变量,随后悔将放置在函数栈帧上的3个非易失寄存器以此由上至下弹出栈区。;
- **紧接着程序会把当前栈底指针的ebp的值,赋值给栈顶指针esp,**栈帧区的收缩调整,以此实现销毁一个函数的栈帧;与此同时,程序会读取曾经存储在栈区上原函数的ebp的地址(当前位于栈顶),并将ebp转移至之前记录的地址上,之后再弹出压在栈上原函数ebp的地址元素,实现ebp返回至原函数内。
- 最后,程序会进行ret 操作,目的是读取调用函数前压在栈上的下一条指令的地址,以此实现调用函数后返回至原函数还能继续执行指令的操作。
根据以上步骤,可得当前栈区示意图

汇编指令:返回后形参的销毁与获取返回值
前面我们提到,形参并非是在新函数栈帧区内创建的,而是临时拷贝一份实参后压在栈上的元素。当函数运行完成后,它的形参又该如何销毁的呢?通过前面的许多步骤和观察上方的函数当前栈帧示意图,现在开动你聪明的大脑思考形参会如何处理时一定会有所思路吧!或许你的思路和答案完全一致,就是弹出栈区。
本处只会讲到两句指令。话不多说,上才(hui)艺(bian)!

现在大声告诉我!add esp,8 是什么意思?(结合上篇:栈帧过程 3)上篇原文链接
答案就是,esp向高地址出挪上8个字节,而我们前面说一个32位机器上一个栈帧元素是4个字节,那现在向高地址挪动8个字节,不就是把原来存放在栈帧上的2个形参的空间给销毁了么?一个函数的形参销毁的答案就是如此,不接受任何反驳QWQ!~
到现在,我们程序也返回了,形参也销毁了,返回值说:“我呢?”别急,再看下一句,说说看这句话是什么意思呢?
答案显而易见,把eax里面的值放到ebp-20h处。
而eax刚刚不就是放的是Add函数的返回值么?到ebp-20h处,我们刚刚提到,ebp已经返回到原函数了,而ebp-20h所指向的区域就是我们之前所声明的变量c的内存空间。这样,一个函数的返回值从返回处获取到原函数的方式就是先把返回值放到eax寄存器内,返回至原函数后再从eax里拿到这个返回值。
根据示例代码剩余的内容无非剩下主函数退出和printf输出。不再做过多赘述。
函数栈帧的创建与销毁-总结
到这里,一个程序的函数栈帧的形成和销毁的全过程就讲解结束啦~你可能会感觉到云里雾里和蒙圈。
确定不来一个总结吗?
那现在来带你一点点的回顾整个过程并做出相应的总结吧。
函数栈帧可以追溯到最顶层的三个非易失寄存器顶上,也可以将edi所标记的ebp-0E4h处开始向高地址填充内容的区域叫做函数栈帧的有效区域。当真正有效意义上的栈帧应该是除去三个非易失寄存器的。
函数栈帧创建可以分为3步:
-
第一步:一个函数在准备调用前会做的第一件事是什么呢?先插眼!程序会首先把当前运行的函数的ebp地址压到内存栈上,以此实现函数运行完成后ebp能返回到调用前的ebp原处。如果是调用普通函数(非main函数),还会压入下一条指令的地址做到调用完后继续执行。
同时,因为压入了新的数据,所以esp栈顶指针也会随之上浮挪动,随后ebp栈底指针也会移动到esp栈顶指针处,此时esp和ebp两个指针同处在栈顶区域。 -
第二步:程序会发出sub 地址减法指令,指示esp向低地址偏移一片区域。esp偏移到新的区域后与当前ebp栈顶指针形成的一片新的内存空间就是这个函数的栈帧区,这也是函数的作用域。随后程序会压入3个非易失寄存器eax,esi,edi,这3个寄存器是一个调用约定(为了能够在不同平台运行)。
-
第三步:程序由ebp栈底指针位置为基准发出lea指令,目的是加载一个函数栈帧的有效空间,通常会向低地址偏移0E4H个空间单位直至前面压入的ebx寄存器之下,并在这个空间内填满字符0CCCCCCCCh,最终这个加载出来的有效空间就是一个函数真正意义上的栈帧有效空间,而这一片由0CCCCCCCCh字符填满的空间就是这个函数的作用域。现在,一个函数的栈帧才真正意义上是完整的。而这时候程序才开始执行它的有效代码。
函数栈帧的销毁和返回同样可以分为3步:
- 第一步:程序会首先会将函数内的局部变量给弹出栈,如果程序有返回值,会把返回值暂时放入寄存器eax当中。随后会将栈顶上的非易失寄存器ebx、esi、edi弹出。
- 第二步:程序将当前栈底指针的ebp的值,赋值给栈顶指针esp,将esp下移后的释放的那一片空间就是函数的栈帧区。
- 第三步:如果还有下一条指令,程序会读取曾经存储在栈区上原函数的ebp的地址,并将ebp转移至之前记录的地址上,实现ebp返回至原函数内,之后再弹出压在栈上原函数ebp的地址元素。最后,程序读取压在栈上的下一条指令的地址,读取完成后弹出栈区,执行下一条指令。
无论程序做出什么指令,最需要记住的原则就是:无论取多少偏移量,都是以栈底的ebp指针位置为基准;无论压入什么内容,栈顶的esp指针都会跟着向上偏移。
我们回到前篇我们提出的几个问题,学习完函数栈帧就已经把这些问题都能一一回答了吧!现在来大声告诉我答案吧!!
- 函数的作用域是怎么形成的呢?
答:一个函数的栈帧,就是一个函数的作用域。
- 局部变量是如何创建的?
答:程序在发出lea(load effective
address)指令后开始绘制这个函数的定义域后,开始以底部的ebp栈底指针为标准不断向低地址划定区域,并将这块区域赋予十六进制的值,这个过程就是局部变量创建的过程。
- 为什么未初始化的局部变量的值是随机值或是乱码呢?
答:程序在发出lea(load effective
address)指令后开始绘制这个函数的定义域并分配好局部变量,因为该区域的初始字符均为0CCCCCCCCh,所以此时打印出来的值多数情况下都是0CCCCCCCCh的表达形式。
- 函数是如何传参的?传参的顺序又是怎么样的呢?
答:程序在传参前会把要传入的参数先放入到寄存器当中,并将寄存器地址压入栈中。再观察他们的顺序
b->a,所以有函数传参是由右往左依次压入栈的(示意图显示a在上,根据栈的先进后出原则证明a是后进的).
- 形参和实参的关系是什么?
答:在调用函数内,任何新产生的局部变量会在调用函数的栈帧区内创建,而使用形参的方法实际上是回到当前函数栈帧创建前压入栈上的形参数据。正因为形参和实参在栈上是两个独立个体的存在,形参的改变不会影响到原来实参,所以才有形参是实参的一份临时拷贝。
- 函数的调用是怎么实现的呢?
答:在开始调用函数前,程序会把需要用到的函数形参提前压到栈。在调用一个函数时,程序会首先压入下一条指令和当前函数的ebp的地址进入栈区内,以此实现调用完成后程序继续执行与ebp返回原处。随后就开始以栈顶位置为起始并同时压入3个非易失寄存器形成一个完整的函数栈帧区。一个函数调用过程正是如此。
- 函数调用结束后是怎么返回的呢?
答:当被调用函数的栈帧被销毁后,程序会读取曾经存储在栈区上原函数的ebp的地址,并将ebp转移至之前记录的地址上,实现ebp返回至原函数内,之后再弹出压在栈上原函数ebp的地址元素。最后,程序读取压在栈上的下一条指令的地址,读取完成后弹出栈区,执行下一条指令。
- 为什么会存在函数递归的最大深度呢?到达最大深度所提出的堆栈溢出错误是什么意思呢?
答:函数的递归之所以有最大深度,是因为每个函数都存在函数栈帧,受到了栈空间的限制,如果递归深度超出栈所能承受的空间,此时就会出现最大深度的堆栈溢出的警告。而不同的函数深度可能会有所不同,毕竟每个函数所需要的栈空间是不一样的。
结语
一个函数的栈帧从创建到销毁的过程笔记 结束啦!~因为相关的知识点不仅重要,还非常非常的多,笔者又非常非常想把内容都表述出来,所以整篇篇幅较长(全文1w+字)!相信你一定能收获满满的。如果有疑问或者纰漏,欢迎在评论区内一起交流学习!
学习系列文章一定要上下篇结合哦!!上篇原文链接
结语
一个函数的栈帧从创建到销毁的过程笔记 结束啦!~因为相关的知识点不仅重要,还非常非常的多,所以篇幅较长!相信你一定能收获满满的。如果有疑问或者纰漏,欢迎在评论区内交流学习!
如果你觉得本系列文章对你用帮助,别忘了点赞关注作者哦!你的鼓励是我继续创作分享加更的动力!愿我们都能一起在顶峰相见。欢迎来到作者的公众号:“01编程小屋” 做客哦!关注小屋,学习编程不迷路!

以上是关于图解C/C++底层:函数栈帧的创建和销毁(下篇)的主要内容,如果未能解决你的问题,请参考以下文章