斯坦福大学公开课机器学习: advice for applying machine learning - evaluatin a phpothesis(怎么评估学习算法得到的假设以及如何防止过拟合或欠
Posted 橙子牛奶糖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了斯坦福大学公开课机器学习: advice for applying machine learning - evaluatin a phpothesis(怎么评估学习算法得到的假设以及如何防止过拟合或欠相关的知识,希望对你有一定的参考价值。
怎样评价我们的学习算法得到的假设以及如何防止过拟合和欠拟合的问题。
当我们确定学习算法的参数时,我们考虑的是选择参数来使训练误差最小化。有人认为,得到一个很小的训练误差一定是一件好事。但其实,仅仅是因为这个假设具有很小的训练误差,当将其样本量扩大时,会发现训练误差变大了,这说明它不是一个好的假设。比如下图,拟合的非常好,一旦样本量改变,其训练误差随之增大。
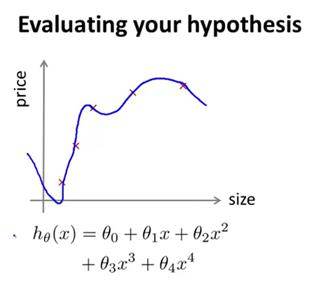
那么我们如何判断一个假设是否是过拟合的呢?我们可以画出假设函数h(x),然后观察。但对于更一般的情况,特征有很多个,比如下图。想要通过画出假设函数来观察,就变得很难甚至不可能了。因此,我们需要另一种评价假设函数的方法。

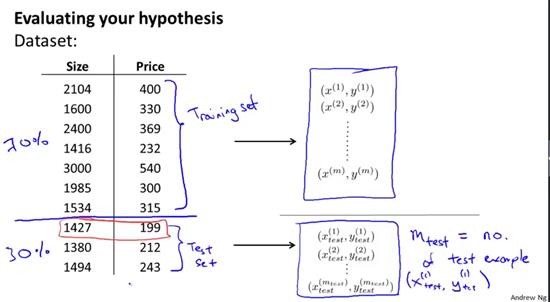
如下给出了一种评价假设的标准方法,假如我们有这样一组数据组,在这里只展示了10组训练样本,当然通常有成百上千组训练样本(下图)。为了确保我们可以评价我们的假设函数,我们要做的是将这些数据分成两部分。第一部分将成为我们的训练集,第二部分将成为我们的测试集。将所有数据分成训练集和测试集,其中一种典型的分割方法是按照7:3的比例,将70%的数据作为训练集,30%的数据作为测试集。这里的m表示训练样本的总数,而剩下的那部分数据将被用作测试集。下标test将表示这些样本是来自测试集,因此x(1)test,y(1)test将成为第一组测试样本。值得注意的是,在这里选择了前70%的数据作为训练集,后30%的数据作为测试集。但如果这组数据有某种规律或顺序的话,那么最好是随机选择70%作为训练集,剩下的30%作为测试集。当然如果数据已经随机分布了,那么可以选择前70%和后30%。但如果你的数据不是随机排列的,最好还是打乱顺序,或者使用一种随机的顺序来构建数据,然后再取出前70%作为训练集,后30%作为测试集。
下面展示了一种典型的训练和测试线性回归学习算法。首先,对训练集进行学习,得到参数θ。具体来讲就是最小化训练误差J(θ),这里的J(θ)是使用那70%数据来定义得到的,也就是仅仅是训练数据的。接下来,计算测试误差,J下标test来表示测试误差。取出之前从训练集中学习得到的参数θ放在这里,计算测试误差,可以写成如下图的形式(蓝色字迹),这实际上是测试集平方误差的平均值,也就是我们期望得到的值。因此,我们使用包含参数theta的假设函数对每一个测试样本进行测试,然后通过假设函数和测试样本计算出mtest个平方误差。这是当我们使用线性回归和平方误差标准时,测试误差的定义。

那么如果是分类问题,比如说使用逻辑回归的时候呢。
训练和测试逻辑回归的步骤,与之前所说的非常类似。首先我们要从训练数据,也就是所有数据的70%中学习得到参数theta,然后用如下的方式计算测试误差,目标函数和我们平常做逻辑回归的一样。唯一的区别是,现在我们使用的是mtest个测试样本,这里的测试误差Jtest(θ)其实叫误分类率,也被称为0/1错分率。0/1表示了我们预测到的正确或错误样本的情况。当假设函数h(x)的值大于等于0.5,并且y的值等于0,或者当h(x)小于0.5,并且y的值等于1,那么这个误差等于1。这两种情况都表明假设函数对样本进行了误判,这里定义阈值为0.5。也就是说,假设结果更趋向于1,但实际是0;或者说假设更趋向于0,但实际的标签却是1,这两种情况都表明误判。否则,我们将误差值定义为0,此时假设值能够正确对样本y进行分类。
然后,我们就能应用错分率误差来定义测试误差,也就是1/mtest乘以h(i)(xtest)和y(i)的错分率误差(从i=1到mtest的求和)。

以上是关于斯坦福大学公开课机器学习: advice for applying machine learning - evaluatin a phpothesis(怎么评估学习算法得到的假设以及如何防止过拟合或欠的主要内容,如果未能解决你的问题,请参考以下文章