Hadoop学习--流量分区并排序
Posted 是渣渣呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop学习--流量分区并排序相关的知识,希望对你有一定的参考价值。
准备文件
列名: 手机号码 上行流量 下行流量 总流量
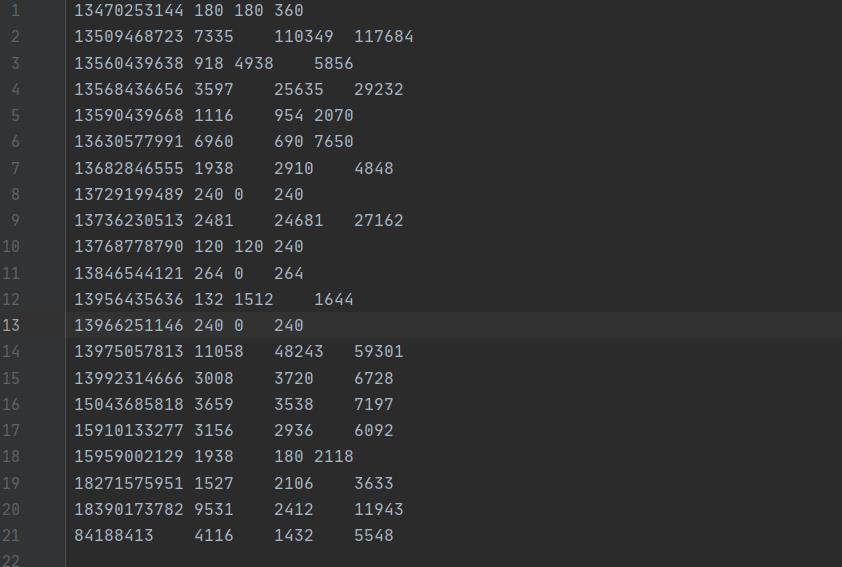
实验内容
统计给定文件中,每一个手机号耗费的总上行流量、下行流量、总流量,手机号136、137、138、139开头都分别放到一个独立的4个文件中,其他开头的放到一个文件中,并按照流量倒序排列
程序思路
每个类的作用
一、 FlowBean实体类
1. 实现Hadoop的Writable接口,并用来实现序列化及反序列化的bean对象
2. 用于存放我们感兴趣的数据(手机号,流量等)
3. 实现WritableComparable接口,用于shuffle中对key进行排序(这里是按照总流量进行倒序排列)
二、FlowSortPartitionerDriver驱动类
1. 获取Job实例并设置资源所在的类
2. 设置自定义的Mapper类,Reducer类以及分区类。
3. 指定Map输出的key,value的类型以及Reduce输出的key,value类型和reducer并行个数
4. 指定要读入的文件的位置和MapReduce后输出文件的位置
三、FlowSortMapper类
1. 获取读入文件并且经过Reader之后的数据(这里是电话及各种流量信息)
2. 对获取的value数据进行处理,并得到新的kv作为mapper的输出
2.1 这里是默认按每行读,所以map方法里先每次获取一行的数据并根据空格符截取数据,并将感兴趣的数据封装到bean对象中
2.2 然后将bean对象作为key,电话号作为value输出
四、FlowSortPartitioner分区类
1. 分区类在map函数执行context.write()时被调用
2. 获取map输出的键值对中我们感兴趣的信息(这里用的是value中电话号码的前三位)
3. 根据获取的信息将map输出的kv(键值对)分配给不同的分区
五、FlowSortReducer类
1. reducer类对shuffle后的键值对进行处理,并得到新的kv作为reducer的输出
1.1. 这里是将电话号码作为key,(其它流量等信息)bean对象作为value
完整代码
按照上面介绍的顺序
package com.zhuge.demo.pojo;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 1. 实现Hadoop的Writable接口,并用来实现序列化及反序列化的bean对象
* 2. 用于存放我们感兴趣的数据(手机号,流量等)
* 3. 实现WritableComparable接口,用于shuffle中对key进行排序(这里是按照总流量进行倒序排列)
*/
public class FlowBean implements Writable , WritableComparable
private long upFlow;
private long downFlow;
private long sumFlow;
public FlowBean()
super();
public FlowBean(long upFlow, long downFlow)
super();
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
//重写序列化方法
@Override
public void write(DataOutput dataOutput) throws IOException
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(sumFlow);
//重写反序列化方法
@Override
public void readFields(DataInput dataInput) throws IOException
this.upFlow = dataInput.readLong();
this.downFlow = dataInput.readLong();
this.sumFlow = dataInput.readLong();
@Override
public String toString()
return upFlow + "\\t" + downFlow + "\\t" + sumFlow;
public long getUpFlow()
return upFlow;
public void setUpFlow(long upFlow)
this.upFlow = upFlow;
public long getDownFlow()
return downFlow;
public void setDownFlow(long downFlow)
this.downFlow = downFlow;
public long getSumFlow()
return sumFlow;
public void setSumFlow(long sumFlow)
this.sumFlow = sumFlow;
// //用于对key进行排序的比较方法,sumFlow是当前对象的总流量,o是要比较的对象,若当前流量的更大,则返回负数
@Override
public int compareTo(Object o)
return Long.compare(((FlowBean) o).getSumFlow(), sumFlow);
package com.zhuge.demo.flowsortpartition;
import com.zhuge.demo.flowsort.FlowSortMapper;
import com.zhuge.demo.flowsort.FlowSortReducer;
import com.zhuge.demo.pojo.FlowBean;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @author ZCH
* @date 2021/5/13 0013 - 上午 11:37
*
* 1. 获取Job实例设置资源所在的类
* 2. 设置自定义的Mapper类,Reducer类以及分区类。
* 3. 指定Map输出的key,value的类型以及Reduce输出的key,value类型和reducer并行个数
* 4. 指定要读入的文件的位置和MapReduce后输出文件的位置
*
*/
public class FlowSortPartitionerDriver
public static void main(String[] args) throws Exception
Job job = Job.getInstance(new Configuration());
//设置job中的资源所在的jar包
job.setJarByClass(FlowSortPartitionerDriver.class);
//设置自定义的Mapper类,Reducer类
job.setMapperClass(FlowSortMapper.class);
job.setReducerClass(FlowSortReducer.class);
//指定Map输出的key,value的类型
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class);
//指定Reduce输出的key,value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//加载自定义分区类
job.setPartitionerClass(FlowSortPartitioner.class);
//设置Reducetask个数
job.setNumReduceTasks(5);
//指定要读入的文件的位置
FileInputFormat.setInputPaths(job,new Path("E:\\\\IDEA-Projects\\\\Writable\\\\src\\\\work\\\\part-r-00000"));
//指定输出文件的存放位置
FileOutputFormat.setOutputPath(job,new Path("E:\\\\IDEA-Projects\\\\Writable\\\\src\\\\output2"));
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
无论我们以怎样的方式从分片中读取一条记录,每读取一条记录都会调用RecordReader类;
系统默认的RecordReader是LineRecordReader,TextInputFormat;
LineRecordReader是用每行的偏移量作为map的key,每行的内容作为map的value;(就相当于我们文件中的每行电话及流量的记录)
注:为何要将bean作为mapper输出的key?
因为:shuffle中是对mapper输出中的key进行排序,也就是这里bean对象的属性sumFlow,所以如果bean不是key的话就没法按照总流量排序了!!
package com.zhuge.demo.flowsort;
import com.zhuge.demo.pojo.FlowBean;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author ZCH
* @date 2021/5/13 0013 - 上午 11:36
*
* 1. 获取读入文件并且经过Reader之后的数据(这里是电话及各种流量信息)
* 2. 对获取的value数据进行处理,并得到新的kv作为mapper的输出
* 3. 这里是默认按每行读,所以map方法里先每次获取一行的数据并根据空格符截取数据,并将感兴趣的数据封装到bean对象中
* 4. 然后将bean对象作为key,电话号作为value输出
*/
public class FlowSortMapper extends Mapper<LongWritable, Text, FlowBean, Text>
FlowBean bean = new FlowBean();
Text v = new Text();
/**
*
* 注: 这个mapper是对FlowDriver生成的文件进行Map的!!
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
// 1 获取一行
String line = value.toString();
// 2 截取
String[] fields = line.split("\\t");
// 3 封装对象
String phoneNbr = fields[0];
long upFlow = Long.parseLong(fields[1]);
long downFlow = Long.parseLong(fields[2]);
bean.setUpFlow(upFlow);
bean.setDownFlow(downFlow);
bean.setSumFlow(upFlow+downFlow);
v.set(phoneNbr);
// 4 输出
context.write(bean, v);
package com.zhuge.demo.flowsortpartition;
import com.zhuge.demo.pojo.FlowBean;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* @author ZCH
* @date 2021/5/13 0013 - 下午 2:05
*
* 1. 分区类在map函数执行context.write()时被调用
* 2. 获取map输出的键值对中的value的信息(这里是电话号码的前三位)
* 3. 根据获取的信息将map输出的kv(键值对)分配给不同的分区
*/
public class FlowSortPartitioner extends Partitioner<FlowBean, Text>
@Override
public int getPartition(FlowBean key, Text text, int i)
String preNum = text.toString().substring(0, 3);
int partition = 4;
// 2 判断是哪个省
if ("136".equals(preNum))
partition = 0;
else if ("137".equals(preNum))
partition = 1;
else if ("138".equals(preNum))
partition = 2;
else if ("139".equals(preNum))
partition = 3;
return partition;
package com.zhuge.demo.flowsort;
import com.zhuge.demo.pojo.FlowBean;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author ZCH
* @date 2021/5/13 0013 - 上午 11:37
*
* 1. reducer类对shuffle后的键值对进行处理,并得到新的kv作为reducer的输出
* 2. 这里是将电话号码作为key,(其它流量等信息)bean对象作为value
*/
public class FlowSortReducer extends Reducer<FlowBean, Text, Text, FlowBean>
@Override
protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException
// 循环输出,避免总流量相同情况
for (Text text : values)
context.write(text, key);
运行结果
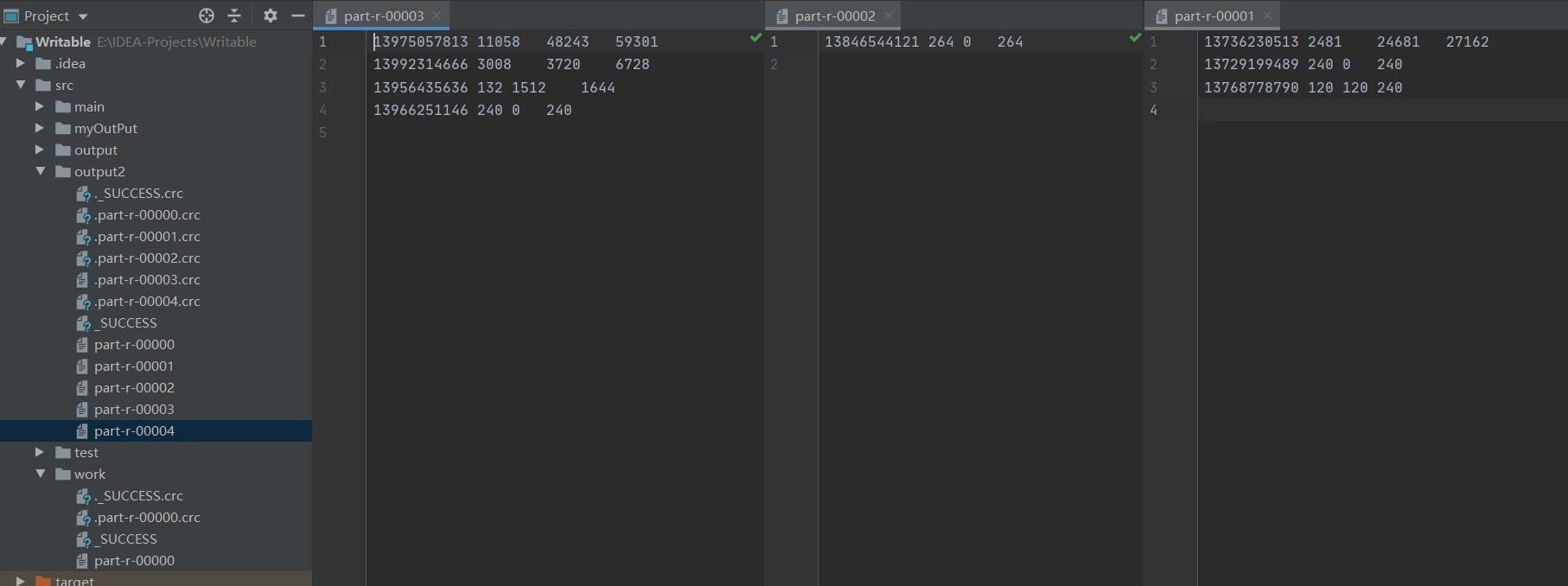
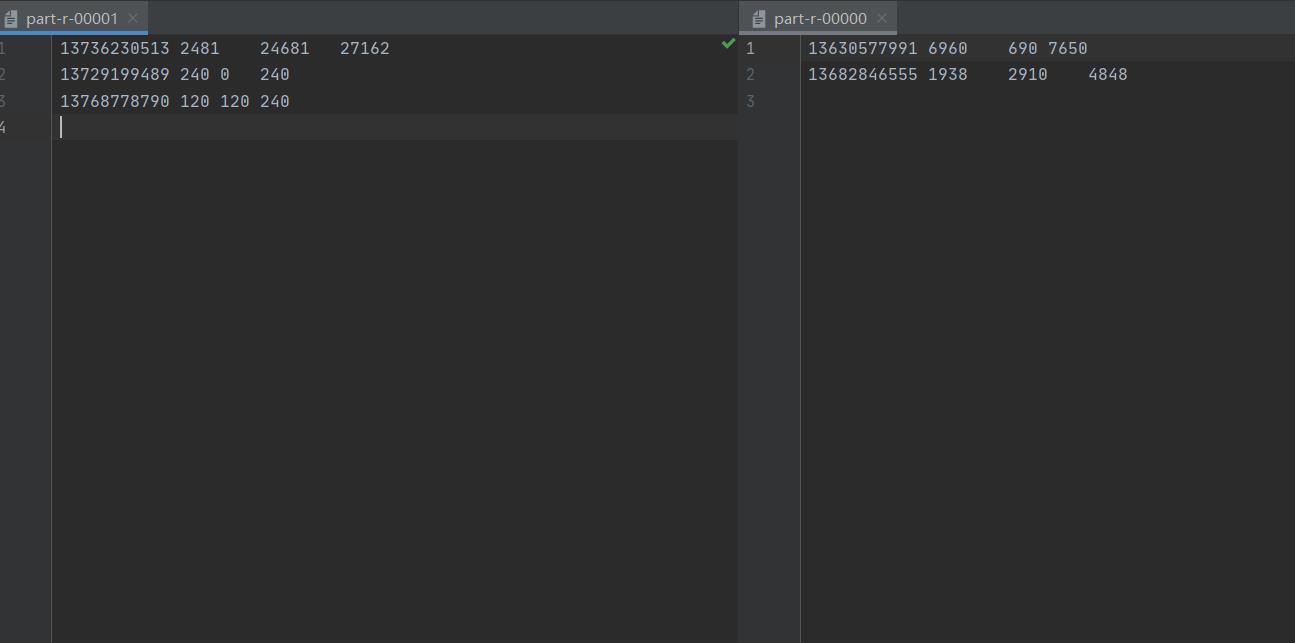
以上是关于Hadoop学习--流量分区并排序的主要内容,如果未能解决你的问题,请参考以下文章