adobe reader 9.0 pro里为啥都没有OCR文本识别这个选项?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了adobe reader 9.0 pro里为啥都没有OCR文本识别这个选项?相关的知识,希望对你有一定的参考价值。
如图,为什么都没有OCR文本识别这些选项?
复制粘贴就不劳动手了
我用的只是adobe reader 9.0 pro其他不想下载了
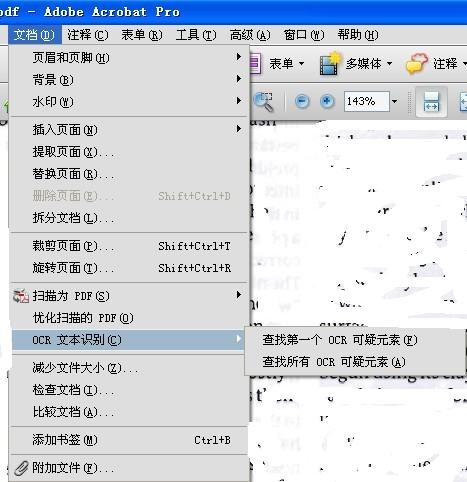
工具的消失,是由于选项勾选为常用工具导致的OCR不可用。在工具集选项卡下,勾选住默认工具即可,详细步骤:
1、打开任意的一个PDF文档。切换到视图菜单模式下。
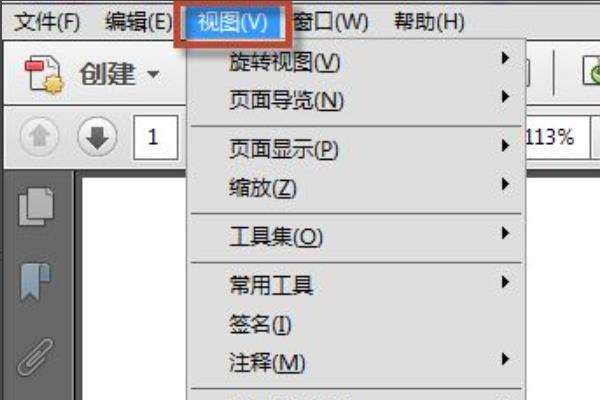
2、在视图菜单模式下,点选工具集。
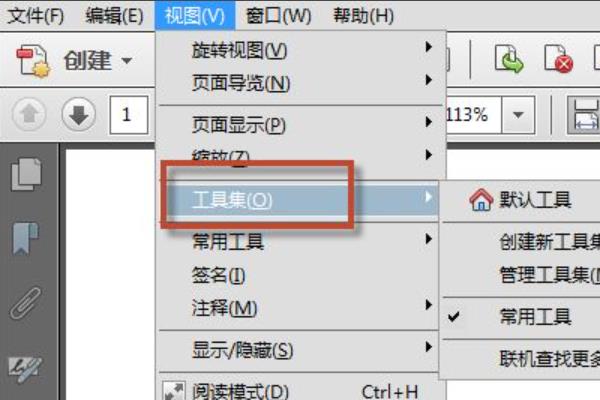
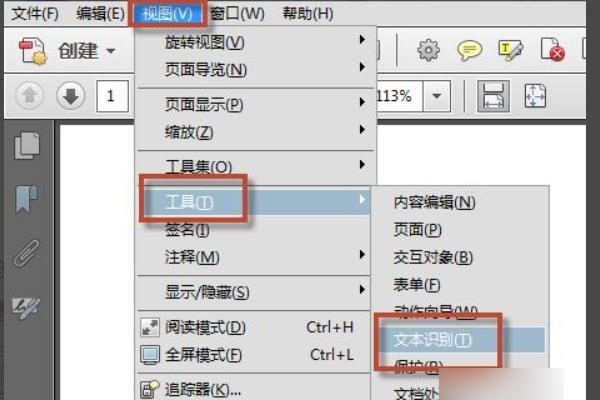
3、在工具集选项卡下,勾选住默认工具即可。

4、点选视图->工具->文本识别,可以看到文本识别成功恢复。
首先安装 Adobe Acrobat 7.0 Pro中文版, 安装时选择自定义方式安装,然后在自定义安装框中选中查看Adobe PDF->Paper Capture (即OCR功能)及亚洲语言支持,完成安装后用Acrobat 打开PDF图像,选择"文档"->"使用OCR识别文本"->"开始", 在弹出的"识别文本"对话框中选择要转换的区域(全部页面,当前页面,自定义从第几页到第几页)单击"编辑(E)..."按钮, "OCR识别的主要语言" 选"英语", "PDF输出样式"选择"格式化的文本和图形", "对图像缩减像素采样" 选合适的的dpi (高dpi转换出来的图像会比较接近原始图像,低dpi转换出来的图像会变得模糊,但前者使转换出来的PDF文件体积更大).
转换完后,由于 Acrobat OCR 本身的识别不可能完全准确,因此会有一些 Acrobat 自己也不能确定是图像还是文字的部分(称为OCR可疑物),需要我们告诉Acrobat这些"OCR可疑物"是文本还是图像:选择"文档"->"使用OCR识别文本"->"查找第一个OCR可疑物",这样Acrobat会标出第一个"OCR可疑物",并显示这些"可疑物"可能对应的文本内容, 如果的确是文本且Acrobat转换出来的文本完全正确,则单击"认可并查找"来确认并查找下一个"可疑物",如果这个"可疑物"的确是文本但 Acrobat转换出来的文本不正确,则我们可以修改后再按"认可并查找";如果不是文本,则单击"非文本"来查找下一个可疑物.
现在唯一的问题是:经常有一些特殊符号(如\alpha,\beta, 积分号等),Acrobat能识别出来是文本,却不能找到对应的文本,以特殊字符\alpha 为例, 因为这个特殊字符其实是"Symbol"字体的"a",因此我们需要在上一步中告诉Acrobat这个字符是 a, 然后用"TouchUp文本"工具选中这个 a ,右键单击, 选"属性", 将它的"字体"属性改成"Symbol", 这样就OK了. 参考技术B 可以用ScanDoc,软件默认没有这个功能,用第三方的软件就好了。 参考技术C 我也是这个问题,解决这个问题确实有大用,不像有些回答者说用其他的识别软件,这是因为他们不知道为什么我们要使用ADOBE9.0里面的OCR识别。难道我们不会用其他的识别软件,以为就是识别一下文本吗 参考技术D pdf文档是图片组成时,需要用OCR软件进行识别转换。
英文内容用acrobat就可以OCR了。
中文就需要汉王或者abbyy finereader OCR professional本回答被提问者和网友采纳
以上是关于adobe reader 9.0 pro里为啥都没有OCR文本识别这个选项?的主要内容,如果未能解决你的问题,请参考以下文章
Adobe Reader自动更新成Adobe Acrobat Reader DC下载的安装文件存放在哪里的?
用adobe reader 打开一个pdf文档,点击了文档里链接到本文档的链接,如何回到上一个位置
为啥在打开PDF文件时,Windows提示Adobe Reader 已停止工作
Adobe Audition 导出到pr时为啥不能勾选Adobe Premiere Pro打开?