第二节 Nginx的web服务器功能
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第二节 Nginx的web服务器功能相关的知识,希望对你有一定的参考价值。
错误日志的级别??
查看主进程号
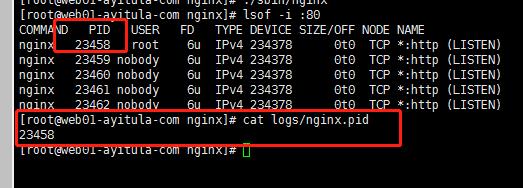
查看访问日志

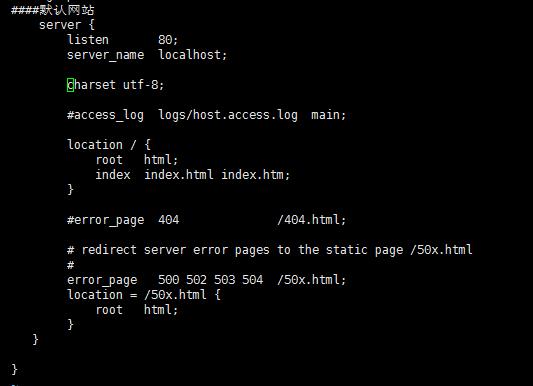
默认网站
删除不需要的https和php的server
把charset 修改为 utf-8 去掉前面的井号
修改access_log日志 当前只有一个server 则先不修改
nginx⽬录访问权限
进入html文件夹
mkdir a
mkdir b
mkdir c
echo aaaaa > a/index.html
echo bbbbb > b/index.html
echo ccccc > c/index.html
添加三个目录然后在目录下增加三个html文件
Linux下访问
elinks http://localhost --dump
如果提示bash: elinks: 未找到命令...
则安装elinks yum -y install elinks
访问 : elinks http://localhost/a
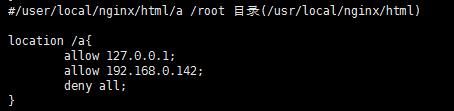
设置a文件夹下的html只能本机访问
../sbin/nginx -g ../conf/nginx.conf
检查后在重新启动
只能127.0.0.1 和192.168.0.142访问(在Linux下elinks访问 如果用本机电脑仍无法访问)
重新加载配置文件:
killall -s HUP nginx
可以修改return 404 来修改返回页面信息
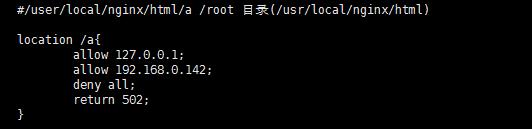
修改地址来做跳转
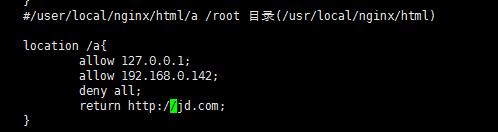
重新加载配置文件后访问直接跳转到jd.com
a目录:
访问控制 只能本机访问a目录其他机器拒绝访问
b目录
目录的用户验证:任何人都可以访问 但是需要凭用密码才能访问
安装htpasswd的包
yum -y install httpd-tools
/etc/nginx/htpasswd加密
创建文件加密
htpasswd -c /etc/nginx/htpasswd sky
如果文件已经存在则
htpasswd -m /etc/nginx/htpasswd sky
密码123
添加日志
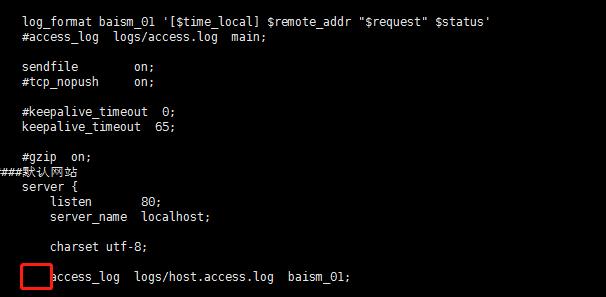
其中红色位置的井号需要去掉
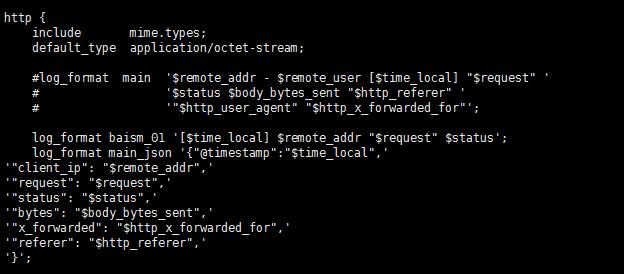
日志格式美化

防盗链
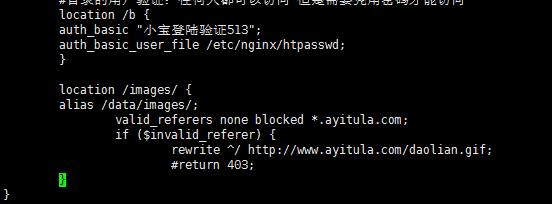
针对请求头中的referer来判断是否是防盗链
Nginx的虚拟主机:
就是把一台物理服务器划分成多个“虚拟”的服务器,每一个虚拟主机都可以有独立的域名和独立的目录
1、基于IP的虚拟主机
实现条件
1) 两个IP
2)DR 存在
3)索引页 index.html
#每个网站都需要一个IP
#缺点 需要多个IP 如果是公网IP 每个IP都需要付费
server {
listen 192.168.0.142:80;
location / {
root html/web1;
index index.html index.htm index.php;
}
}
server {
listen 192.168.0.152:80;
location / {
root html/web2;
index index.html index.htm;
}
}
备份nginx.config

删除config中井号和空行的数据

修改server
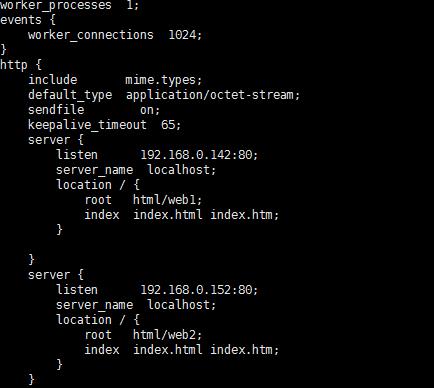
使用逻辑网卡方式增加ip
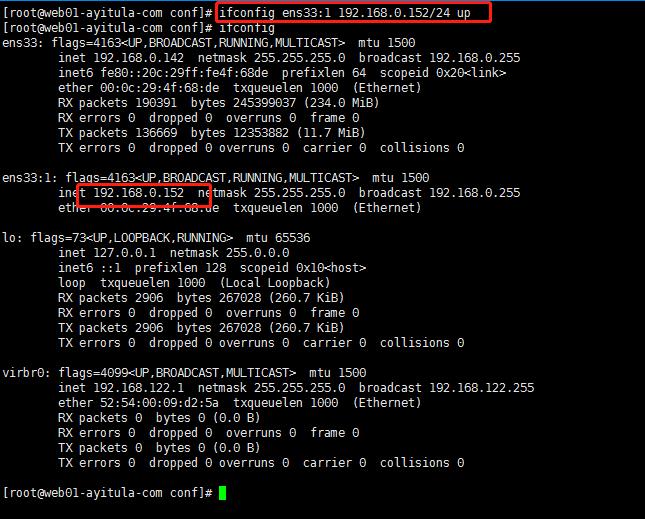
建立目录:web1 web2
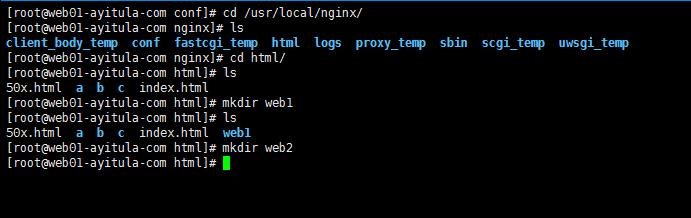
建立索引页

检测配置文件后启动Nginx 查看是否有142和152的ip
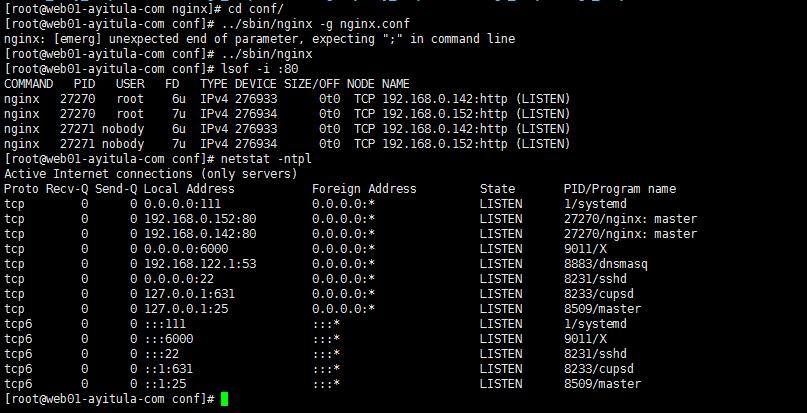
检查是否启动成功
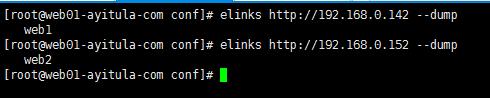
基于端口的虚拟主机
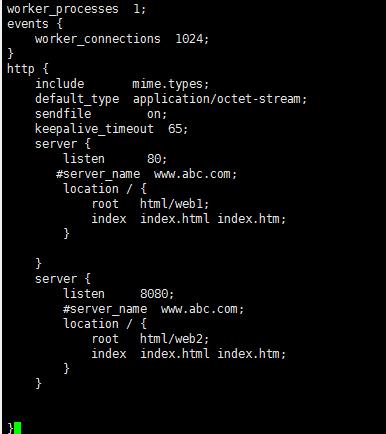
2、基于端口的虚拟主机
#只需要一个IP
#缺点 端口你是无法告诉公网用户 无法适用于公网客户 适合内部用户
基于端口
server {
listen 80;
#server_name www.abc.com;
location / {
root html/web1;
index index.html index.htm index.php;
}
}
server {
listen 8080;
#server_name www.abc.com;
location / {
root html/web2;
index index.html index.htm;
}
}
关闭子网卡
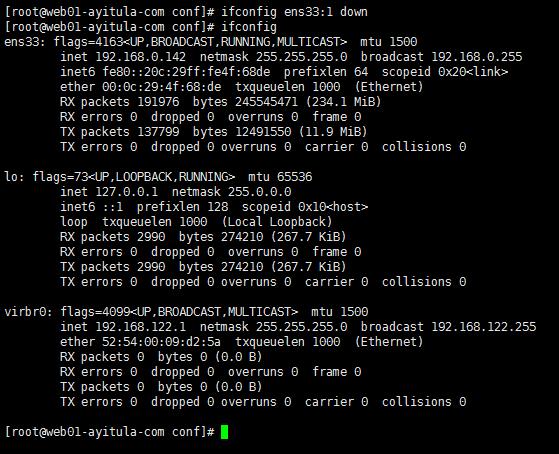
修改配置文件
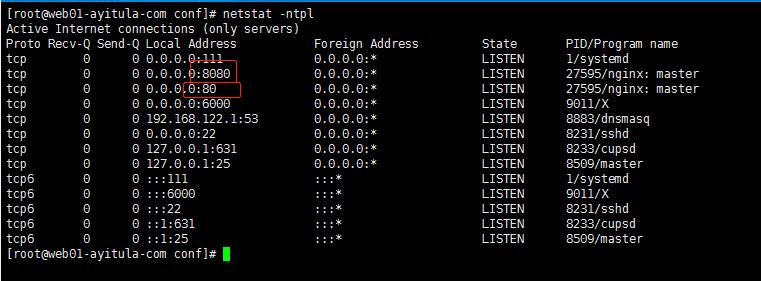
检测 关闭 重启

检测
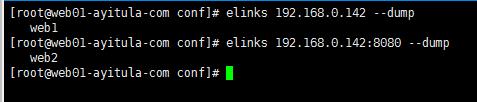
3、基于域名的虚拟主机
一个网站必然有一个域名
基于域名
server {
listen 80;
server_name www.abc.com;
location / {
root html/web1;
index index.html index.htm index.php;
}
}
server {
listen 80;
server_name www.cbd.com;
location / {
root html/web2;
index index.html index.htm;
}
}
解析域名
vi /etc/hosts

修改配置文件
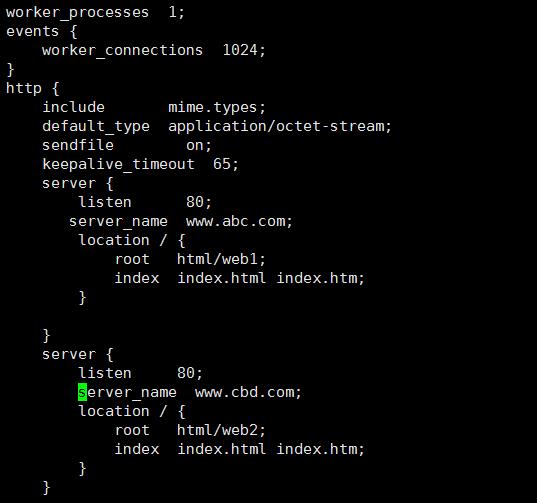
检测 关闭 启动 检查
查看
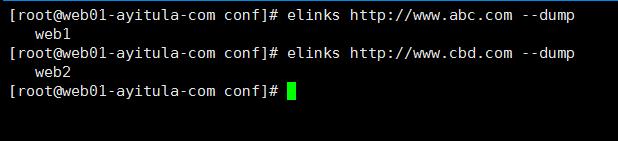
Nginx的反向代理
代理用户上网是正向代理
代理服务器是反向代理
反向代理介绍
代理理服务器器,客户机在发送请求时,不不会直接发送给⽬目的主机,⽽而是先发送给代理理服务器器,代理理服务接受客户机请求之后,再向主机发出,并接收⽬目的主机返回的数据,存放在代理理服务器器的硬盘中,再发送给客户机。
应用场景:
• 堡垒机场景
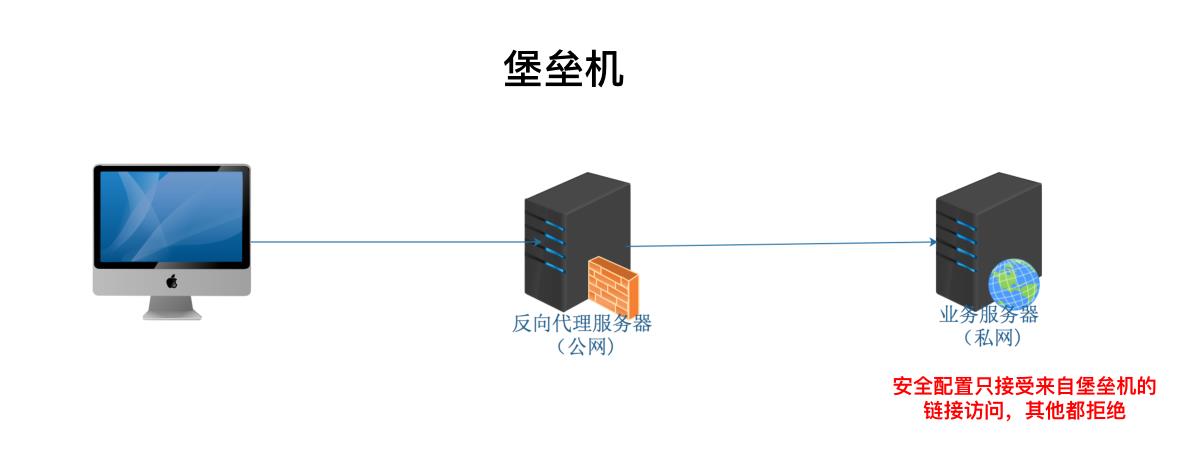
• 内网服务器器发布场景
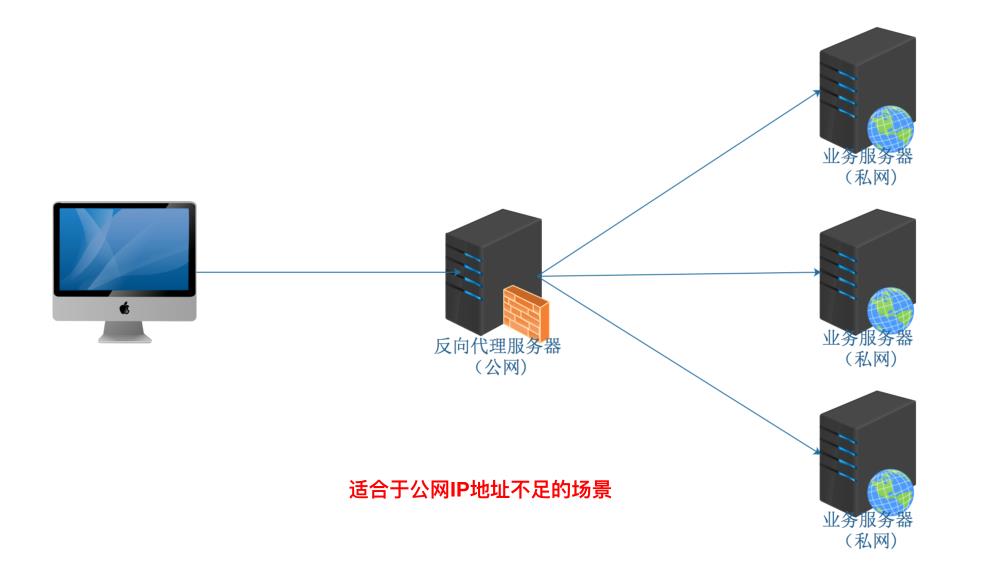
• 缓存场景
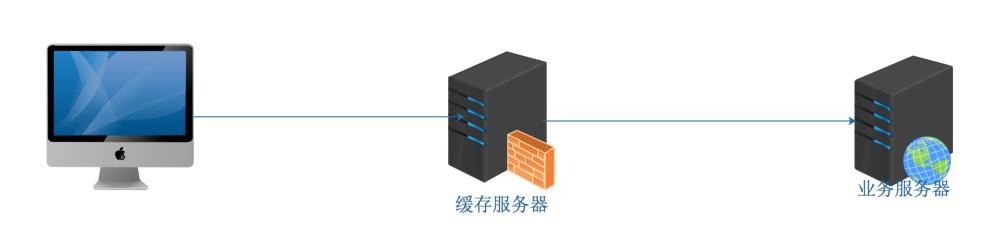
反向代理的原理

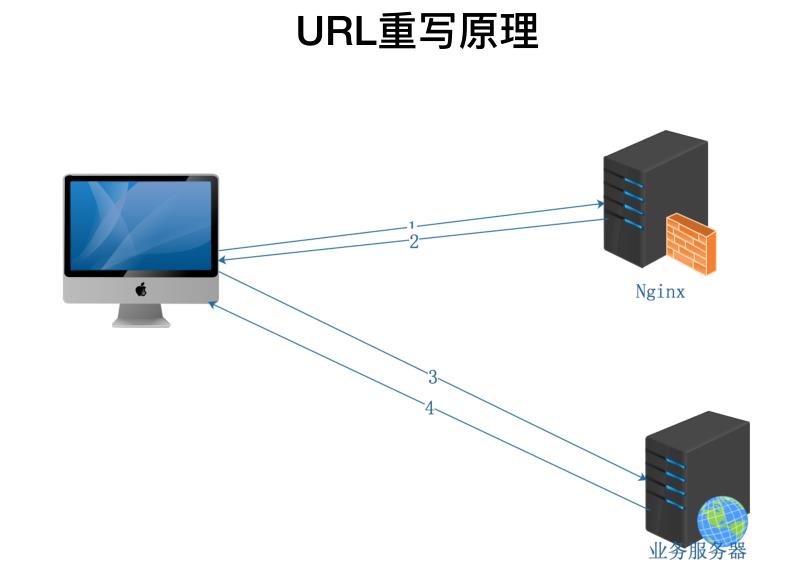
client mac http://192.168.0.142
反代 Nginx 142
业务机器 book.ayitula.com http://118.190.209.153:4000/
配置config

浏览器访问192.168.0.142
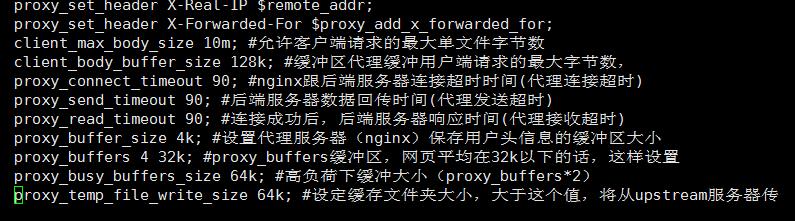
location / {
index index.php index.html index.htm; #定义首页索引文件的名称
proxy_pass http://mysvr ;#请求转向mysvr 定义的服务器列表
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
client_max_body_size 10m; #允许客户端请求的最大单文件字节数
client_body_buffer_size 128k; #缓冲区代理缓冲用户端请求的最大字节数,
proxy_connect_timeout 90; #nginx跟后端服务器连接超时时间(代理连接超时)
proxy_send_timeout 90; #后端服务器数据回传时间(代理发送超时)
proxy_read_timeout 90; #连接成功后,后端服务器响应时间(代理接收
超时)
proxy_buffer_size 4k; #设置代理服务器(nginx)保存用户头信息
的缓冲区大小
proxy_buffers 4 32k; #proxy_buffers缓冲区,网页平均在32k以
下的话,这样设置
proxy_busy_buffers_size 64k; #高负荷下缓冲大小(proxy_buffers*2)
proxy_temp_file_write_size 64k; #设定缓存文件夹大小,大于这个值,将从upstream服务器传
}
添加请求头

设置超时时间 缓存字节数等
限速
限流(rate limiting)是NGINX众多特性中最有用的,也是经常容易被误解和错误配置的,特性之一。该特性可以限制某个用户在一个给定时间段内能够产生的HTTP请求数。请求可以简单到就是一个对于主页的GET请求或者一个登陆表格的POST请求。
限流也可以用于安全目的上,比如减慢暴力密码破解攻击。通过限制进来的请求速率,并且(结合日志)标记出目标URLs来帮助防范DDoS攻击。一般地说,限流是用在保护上游应用服务器不被在同一时刻的大量用户请求湮没。
算法思想是:
水(请求)从上方倒入水桶,从水桶下方流出(被处理);
来不及流出的水存在水桶中(缓冲),以固定速率流出;
水桶满后水溢出(丢弃)。
这个算法的核心是:缓存请求、匀速处理、多余的请求直接丢弃。
相比漏桶算法,令牌桶算法不同之处在于它不但有一只“桶”,还有个队列,
这个桶是用来存放令牌的,队列才是用来存放请求的。
Nginx官方版本限制IP的连接和并发分别有两个模块:
limit_req_zone 用来限制单位时间内的请求数,即速率限制,采用的漏桶算法
"leaky bucket"。
limit_req_conn 用来限制同一时间连接数,即并发限制。
limit_req_zone 参数配置
Syntax: limit_req zone=name [burst=number] [nodelay];
Default: —
Context: http, server, location
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
#基于IP对下载速率做限制 限制每秒处理1次请求,对突发超过5个以后的请求放
入缓存区
http {
limit_req_zone $binary_remote_addr zone=baism:10m rate=1r/s;
server {
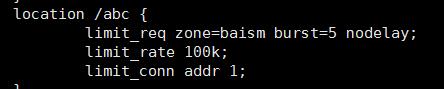
location /abc {
limit_req zone=baism burst=5 nodelay;
}
}
limit_req_zone $binary_remote_addr zone=baism:10m rate=1r/s;
第一个参数:$binary_remote_addr 表示通过remote_addr这个标识来做限制,“binary_”的目的是缩写内存占用量,是限制同一客户端ip地址。
第二个参数:zone=baism:10m表示生成一个大小为10M,名字为one的内存区域,用来存储访问的频次信息。
第三个参数:rate=1r/s表示允许相同标识的客户端的访问频次,这里限制的是每秒1次,还可以有比如30r/m的。
limit_req zone=baism burst=5 nodelay;
第一个参数:zone=baism 设置使用哪个配置区域来做限制,与上面limit_req_zone 里的name对应。
第二个参数:burst=5,重点说明一下这个配置,burst爆发的意思,这个配置的意思是设置一个大小为5的缓冲区当有大量请求(爆发)过来时,超过了访问频次限制的请求可以先放到这个缓冲区内。
第三个参数:nodelay,如果设置,超过访问频次而且缓冲区也满了的时候就会直接返回503,如果没有设置,则所有请求会等待排队。
修改config文件


保存 关闭进程 启动 验证
#基于IP做连接限制 限制同一IP并发为1 下载速度为100K
limit_conn_zone $binary_remote_addr zone=addr:10m;
server {
listen 80;
server_name localhost;
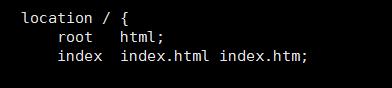
location / {
root html;
index index.html index.htm;
}
location /abc {
limit_conn addr 1;
limit_rate 100k;
}
}
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
#基于IP做连接限制 限制同一IP并发为1 下载速度为100K
limit_conn_zone $binary_remote_addr zone=addr:10m;
#基于IP对下载速率做限制 限制每秒处理1次请求,对突发超过5个以后的请求放
入缓存区
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
server {
listen 80;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
location /abc {
limit_req zone=one burst=5 nodelay;
limit_conn addr 1;
limit_rate 100k;
}
}
}
创建个大文件

下载

启动限速后下载

限制同时下载个数
第二个启动限速报错

Nginx的URL重写




编写config文件
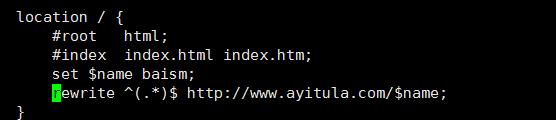
保存 关闭进程 重启
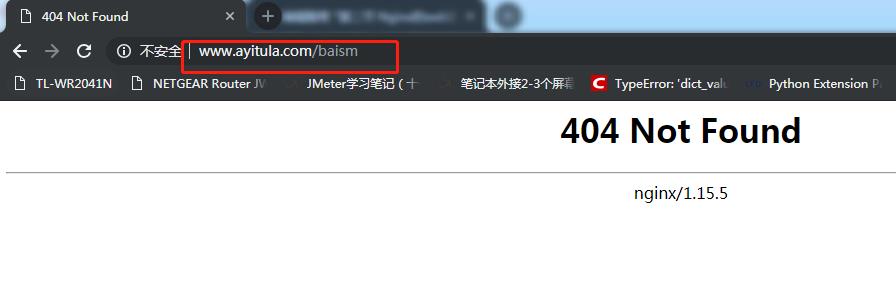
#模糊匹配
~匹配
!~不匹配
~* 不区分大小写的匹配
#精确匹配 = !=
使用谷歌浏览器则返回403
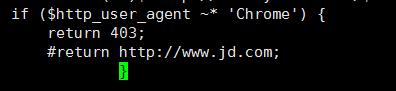
保存 关闭进程重启
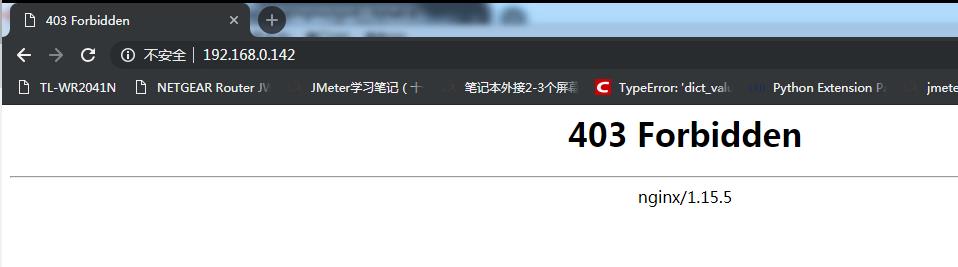
其他浏览器
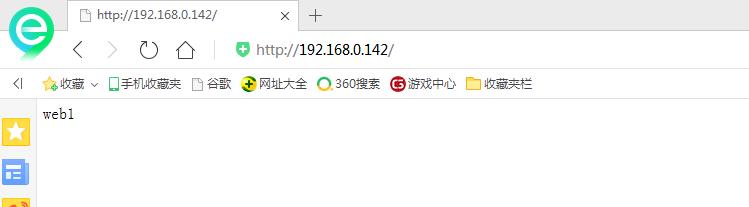
return jd.com
break 后后面不执行
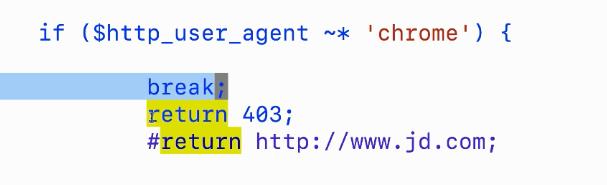


修改config文件

保存 关闭 启动Nginx
修改host

打开192.168.0.142
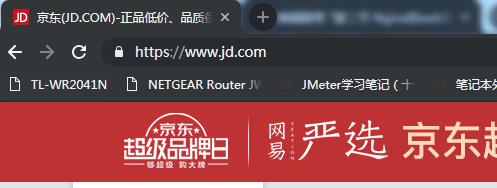
临时重定向
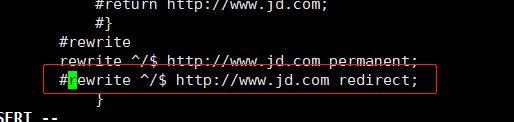


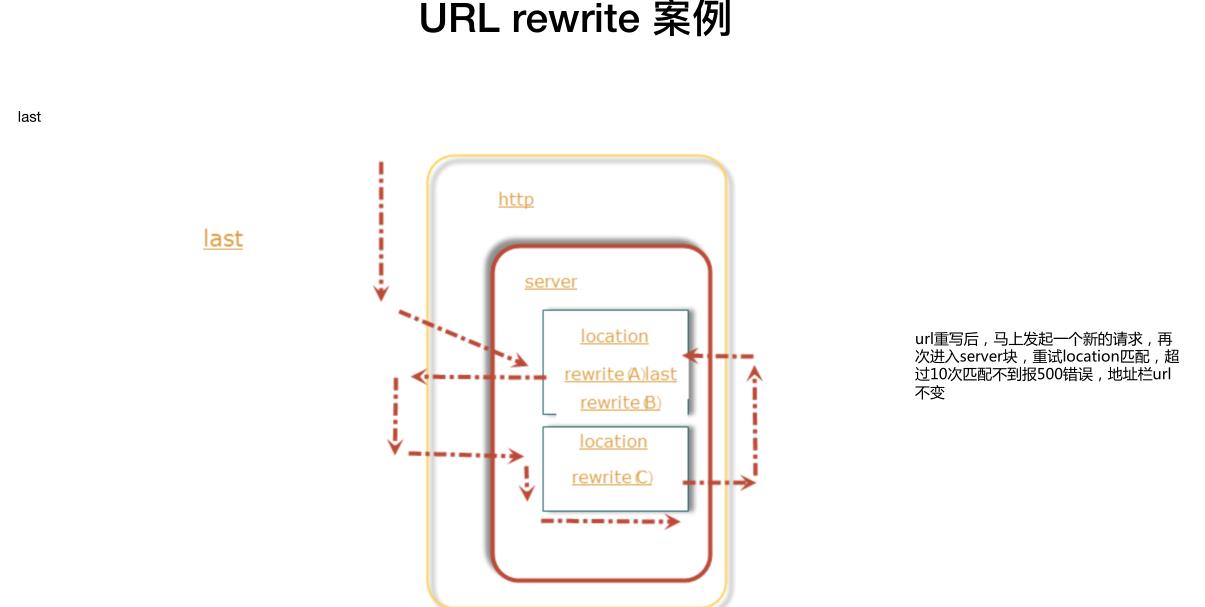

修改config文件
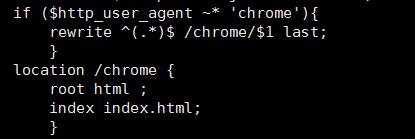
创建目录
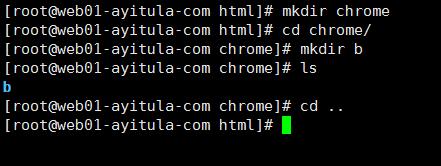

关闭重启Nginx
启动 192.168.0.142/b 跳转到192.168.0.142/chrome/b
以上是关于第二节 Nginx的web服务器功能的主要内容,如果未能解决你的问题,请参考以下文章