第四节:web爬虫之urllib
Posted 懒惰的小松鼠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第四节:web爬虫之urllib相关的知识,希望对你有一定的参考价值。
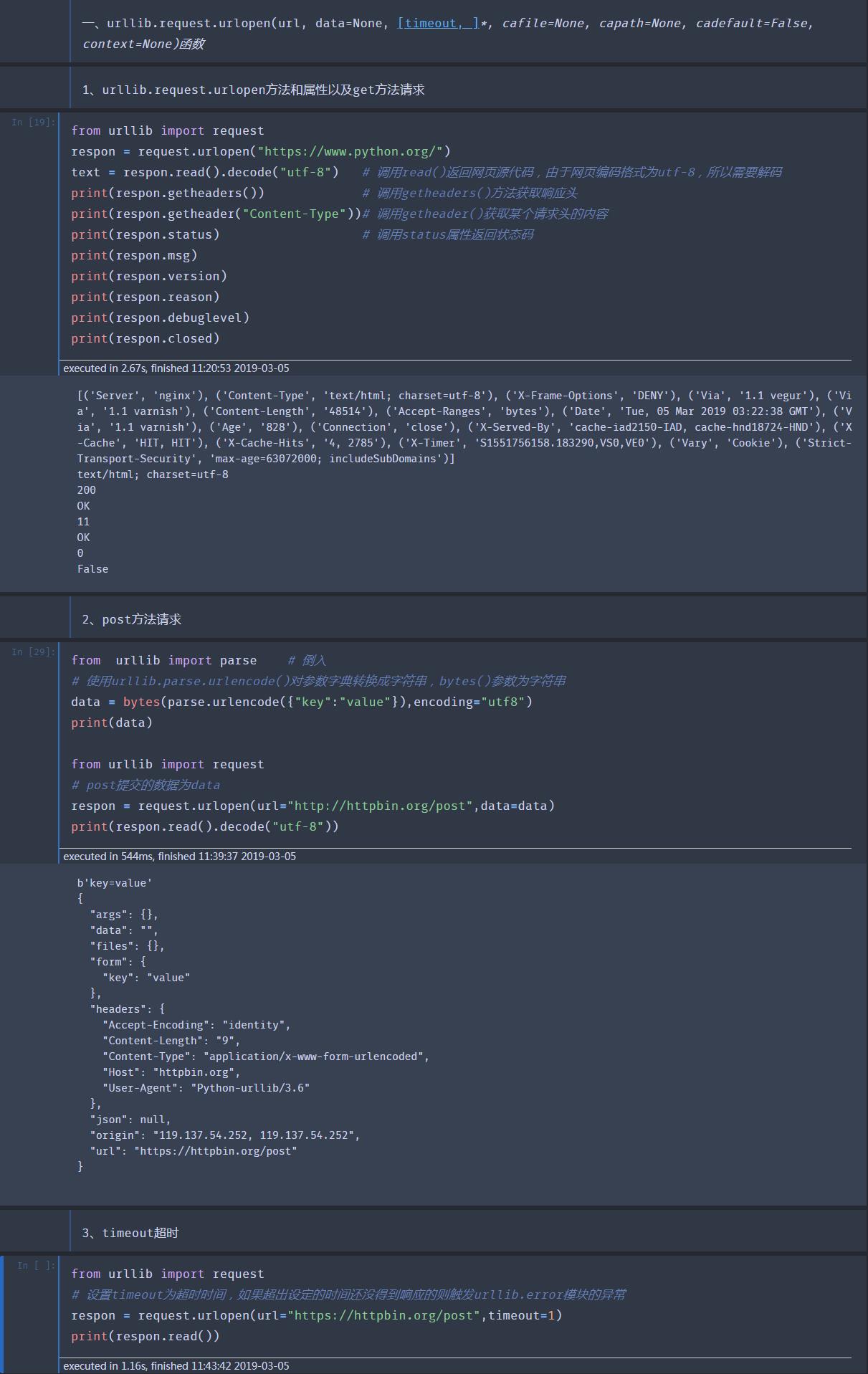
一、urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
简介:urllib.request.urlopen()函数用于实现对目标url的访问
参数详解:
url: 需要打开的网址
data:Post提交的数据
timeout:设置网站的访问超时时间
cafile:CA证书文件
capath:CA证书文件目录
cadefault:cadefault已经弃用,默认为False
context:设置SSL
以上是关于第四节:web爬虫之urllib的主要内容,如果未能解决你的问题,请参考以下文章