linux常用过滤日志命令
Posted 职业法师李富贵!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux常用过滤日志命令相关的知识,希望对你有一定的参考价值。
#过滤nginx访问日志
awk \'{print $1}\' /var/log/nginx/access.log | sort | uniq -c | sort -nr -k1 | head -n 10
#过滤ssh登录失败日志
grep "Failed password for root from" /var/log/secure | awk {\'print $11\'} | sort | uniq -c | sort -nr -k1 | head -n 10
输出结果如下图:(前面代表次数,后面代表ip)
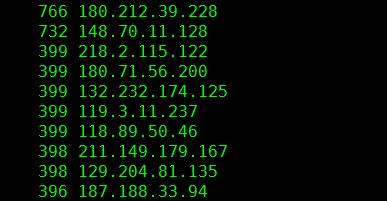
sort命令详解:
Linux sort命令用于将文本文件内容加以排序。sort可针对文本文件的内容,以行为单位来排序。
-f :忽略大小写的差异,例如 A 与 a 视为编码相同; -b :忽略最前面的空格符部分; -M :以月份的名字来排序,例如 JAN, DEC 等等的排序方法; -n :使用『纯数字』进行排序(默认是以文字型态来排序的); -r :反向排序; -u :就是 uniq ,相同的数据中,仅出现一行代表; -t :分隔符,默认是用 [tab] 键来分隔; -k :以那个区间 (field) 来进行排序的意思
uniq命令详解:
uniq命令可以去除排序过的文件中的重复行,因此uniq经常和sort合用。也就是说,为了使uniq起作用,所有的重复行必须是相邻的。
-i :忽略大小写字符的不同; -c :进行计数 -u :只显示唯一的行
以上是关于linux常用过滤日志命令的主要内容,如果未能解决你的问题,请参考以下文章