内核解读之内存管理页分配器伙伴系统介绍
Posted 奇妙之二进制
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了内核解读之内存管理页分配器伙伴系统介绍相关的知识,希望对你有一定的参考价值。
文章目录
1 分配器的需求
伙伴系统是linux的页框分配器,负责系统物理内存的分配工作。由于几乎所有模块的运行都依赖于内存,而不同模块对内存分配策略又有不同的需求,因此如何高效地满足这些需求就成为了页框分配器的核心问题。
例如对于大部分内存分配请求,若内存分配器暂时无法满足要求则允许其返回失败。而对于一些内核关键路径的请求,一旦失败可能会导致内核无法继续运行,则这种分配并不允许失败。
对于实时性要求不高的模块,若分配器当前空闲内存不足,可以将进程睡眠,然后通过swap页面交换或cache/buffer内存回收机制从系统回收部分内存后再延迟分配。而有些处于关中断等临界区的代码不允许睡眠,因此这种分配一旦空闲内存不足,则应该立即返回分配失败,而不能睡眠等待。
前面提到内存回收,那什么时候应该触发内存回收,回收操作又应该在什么时候完成。对于不允许失败的操作,即使通过回收还无法得到足够多的内存又该如何处理。
除此以外,由于内存分配是一种比较频繁的操作,分配器还需要考虑内存分配的速度,以期使其能尽快完成。同时,cache缓存能极大地提高程序的执行效率,若在内存分配策略中考虑优先分配还处于cache中的hot page,显然能够提升内存访问的速度。
以上这些问题都需要在内存分配策略中综合考虑。当然,linux在不同场景下对内存分配策略的需求千差万别,伙伴系统分配器也是力求能够尽量满足大部分的通用需求,其中很多参数也是根据经验值设置。而且随着需求的变化,分配器本身也会处于不断更新之中。
2 伙伴系统的内存组织
内存分配的首要任务当然是如何快速找到待分配的空闲内存,伙伴系统通过以下三个层次管理系统的空闲页框:
(1)为每个内存节点建立内存分配的zonelist优先级列表
(2)通过freelist管理每个zone中的空闲内存,这些内存页框按2的指数次分为不同的order,并且每个order进一步按迁移类型不同挂到独立的链表中
(3)内存zone为每个cpu维护一个per_cpu_pages数据结构,用于保存该cpu的hot page。若分配的页面数量较少,且per_cpu_pages中拥有合适的页面,则优先从pcp中分配内存,以提升系统的性能
2.1 zonelist列表结构
linux通过node和zone划分系统内存,并且为每个node建立了按优先级排列的zonelist列表。由于cpu对与其绑定的local node访问速度最快,而对与其距离最远的remote node访问速度最慢。因此node优先级主要考虑给定node与local node的距离,同时也会根据一些其它因素做适当的调整。
内核又根据内存的应用场景不同将每个node的内存划分为不同的zone,对于arm64架构一般包含zone_normal和zone_dma两种zone。其中zone_dma是可被用于dma的内存,因此对系统来说更加重要,在内存分配时除非明确指定从该zone分配,否则只有在zone_normal内存不足时才会动用这部分资源。
在上一篇伙伴系统初始化中已经详细介绍了内核zonelist的建立过程,其在建立完成后每个node都会拥有一个类似下图的内存分配优先级列表:
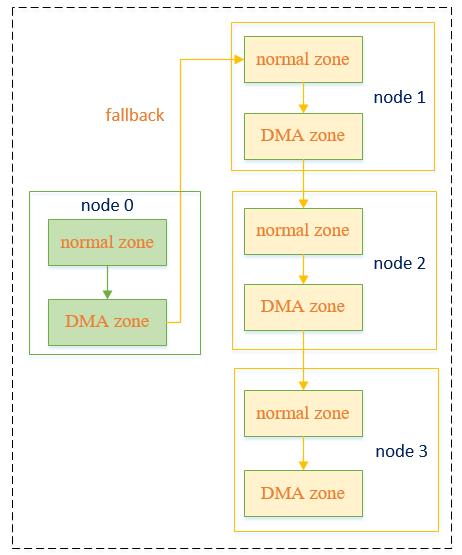
例如对于上图的node 0节点,若需要分配非DMA的普通内存,则其先尝试从从node 0的normal zone分配,若分配不成功,则继续尝试从node 0的DMA zone分配,若依然不成功,则fallback到node 1中分配,依次类推。
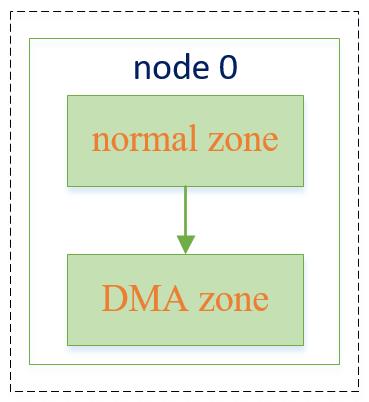
对于numa系统,除了上面的这张zonelist之外,还会为每个节点创建一张不带fallback的zonelist。若申请者明确要求只从某个节点分配内存,则若该节点分配失败后不能fallback到备用节点,因此这张表只包含节点自身的zone,其形式如下:
以上结构在内核中通过数据结构struct zonelist表示,其定义如下:
struct zonelist
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
;
其中MAX_ZONES_PER_ZONELIST表示一个node最多可以包含多少个可用于内存分配的zone,其定义如下:
#define MAX_ZONES_PER_ZONELIST (MAX_NUMNODES * MAX_NR_ZONES)
而结构体zoneref的定义如下:
struct zoneref
struct zone *zone;
int zone_idx;
;
它表示一个特定的zone,其中zone指向特定zone的指针,zone_idx表示该zone的类型,如normal zone或dma zone等
2.2 zone的空闲内存结构
伙伴系统在一个特定的zone中将物理页框按2的order次为单位进行划分,并且相同order的页框继续按不同的迁移类型进一步划分,划分后的每种类型页框被挂到不同的空闲链表上。在内存分配时,根据调用接口传入的order和migrate_type参数,就能快速找到对应的链表,若该链表非空则内存分配完成。以下为一个zone的空闲页框链表示意图:


若需要分配一个order为1的可移动页框,则直接获取上图蓝色链表第一个节点的页框即可。
zone中使用下述结构体定义空闲内存链表:
struct free_area free_area[MAX_ORDER];
struct free_area
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
;
其中free_list表示特定order中不同迁移类型内存的空闲链表,nr_free表示该order下总的空闲页框数量
2.3 内存迁移类型
2.4 pcp页框
相对于访问寄存器而言,cpu对内存的访问是相当耗时的,因此为了提高系统性能,处理器都在cpu和内存之间增加一些更快的cache作为临时缓存。cache一般会缓存最近访问过的内存数据,因此最近被使用过的页位于cache中的概率也最大。
伙伴系统的页框分配策略中,若能优先分配最后被释放的内存页,则这些页还位于cache中的概率也比较大。因此伙伴系统为每个cpu维护了一个per_cpu_pages数据结构,用于保存最近被释放的页框,在内存分配时也会优先从该列表中查找匹配的页框,从而尽量提升系统的性能。
与free_area类似,这些页框也是根据order和迁移类型划分的。为了减轻其维护的页框数量,pcp只包含了order较低的几种页框长度,即其只维护小于PAGE_ALLOC_COSTLY_ORDER的页框,在当前内核版本中该值被定义为3。其结构体定义如下:
/* Fields and list protected by pagesets local_lock in page_alloc.c */
struct per_cpu_pages
spinlock_t lock; /* Protects lists field */
int count; /* number of pages in the list */
int high; /* high watermark, emptying needed */
int batch; /* chunk size for buddy add/remove */
short free_factor; /* batch scaling factor during free */
#ifdef CONFIG_NUMA
short expire; /* When 0, remote pagesets are drained */
#endif
/* Lists of pages, one per migrate type stored on the pcp-lists */
struct list_head lists[NR_PCP_LISTS];
____cacheline_aligned_in_smp;
pcp也是安装迁移类型挂接在不同链表,并且每种类型都有0,1,… PAGE_ALLOC_COSTLY_ORDER 不同阶的大小。
/*
* One per migratetype for each PAGE_ALLOC_COSTLY_ORDER. One additional list
* for THP which will usually be GFP_MOVABLE. Even if it is another type,
* it should not contribute to serious fragmentation causing THP allocation
* failures.
*/
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
#define NR_PCP_THP 1
#else
#define NR_PCP_THP 0
#endif
#define NR_LOWORDER_PCP_LISTS (MIGRATE_PCPTYPES * (PAGE_ALLOC_COSTLY_ORDER + 1))
#define NR_PCP_LISTS (NR_LOWORDER_PCP_LISTS + NR_PCP_THP)
除了链表成员以外,该结构体还包含了count、high和batch等成员。我们知道pcp主要是为了优化性能而在free_area之上提供了一层类似缓存的机制,若其包含的页框数量太多则最先释放的那些页框可能早已不在cache中,从而失去了其本身的目的。更糟糕的是,这些缓存在pcp中的页框,若释放到free_area中则可能可以与其它页框合并成order更高的内存块,从而减少系统的内存碎片。
我们知道内核中连续大块内存是稀缺资源,因此为了减轻内存碎片,需要控制pcp中内存的数量。high参数就是用于该目的,当pcp中的内存高于high时,其会将一部分内存释放回buddy的free_area中,当然若pcp中的内存不足,也会从free_area中分配部分内存。那么每次释放或分配内存的数量是多少呢?它是由batch参数指定的,其表示单次分配或释放的页框数为batch* 2 ^order个。
最后,我们再看一下链表操作需要的注意点。由于我们每次都希望从pcp中分配最新加入的页框,因此在向pcp释放页框时需要将其插入到链表头后面,而分配页框时也需要从链表头后第一个节点处开始分配,以达到获取hot page的目的。以下为pcp内存释放时链表节点插入和内存分配时链表节点删除示意图:


以上是关于内核解读之内存管理页分配器伙伴系统介绍的主要内容,如果未能解决你的问题,请参考以下文章