深入浅出Tomcat/4 - Tomcat容器
Posted 江边闲话集
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入浅出Tomcat/4 - Tomcat容器相关的知识,希望对你有一定的参考价值。
Container是一个Tomcat容器的接口,Tomcat有四种容器
· Engine
· Host
· Context
· Wrapper
Engine代表整个Catalina的Servlet引擎,Host则代表若干个上下文的虚拟主机。Context则代表一个Web应用,而一个Context则会用有多个Wrapper。Wrapper是一个单独的Servlet。
下图是几种容器实现的类继承图,我们可以看到最下层以Standard开头的几个类
· StandardEngine
· StandardHost
· StandardContext
· StandardWrapper
以上几个类是Tomcat对几种容器的默认实现。
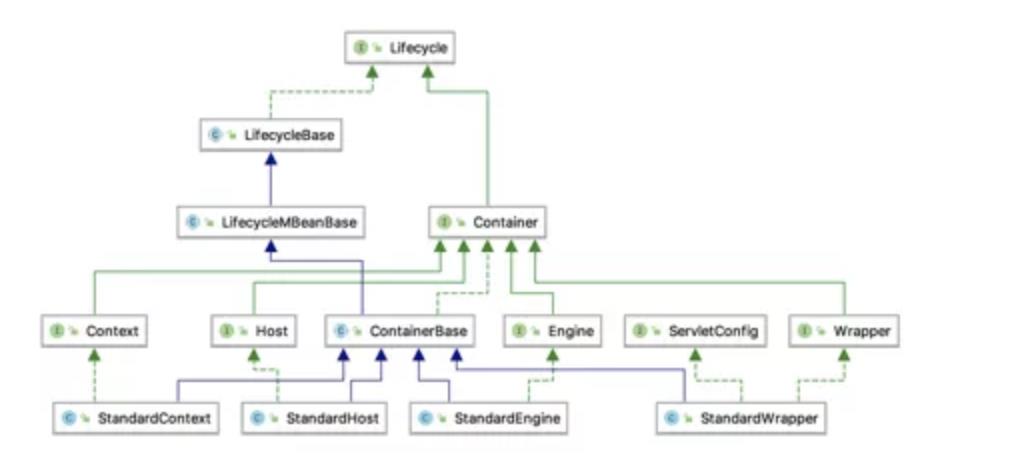
以上几个类是Tomcat对几种容器的默认实现。
Engine
Engine的属性name,是Engine的名字,如果有多个Engine,Engine需要唯一。defaultHost也非常重要,如果一个Engine有多个Host时,如果匹配不到合适的Host时,则需要默认选取一个,也就是defaultHost定义的,它的值为Host的name。
<Engine name="Catalina" defaultHost="localhost"> <RealmclassName="org.apache.catalina.realm.LockOutRealm"> <!--This Realm uses the UserDatabase configured in the global JNDI resources under the key"UserDatabase". Any edits that are performed against thisUserDatabase are immediately available for use by theRealm. --> <RealmclassName="org.apache.catalina.realm.UserDatabaseRealm" resourceName="UserDatabase"/> </Realm> <Host name="localhost" appBase="webapps" unpackWARs="true" autoDeploy="true"> <!--SingleSignOn valve, share authentication between web applications Documentation at: /docs/config/valve.html--> <!-- <ValveclassName="org.apache.catalina.authenticator.SingleSignOn" /> --> <!-- Access log processes allexample. Documentation at:/docs/config/valve.html Note: The pattern used isequivalent to using pattern="common" --> <ValveclassName="org.apache.catalina.valves.AccessLogValve"directory="logs" prefix="localhost_access_log" suffix=".txt" pattern="%h %l %u %t "%r" %s %b" /> </Host> </Engine>
Engine还有另外一个非常重要的属性叫jvmRoute,它一般用在Cluster里。
假设Cluster是这么配置的,Tomcat1的 conf/server.xml
<Engine name="Catalina" defaultHost="localhost" jvmRoute="tomcat1">
Tomcat2的conf/server.xml
<Engine name="Catalina" defaultHost="localhost" jvmRoute="tomcat2">
在生成SessionID时,jvmRoute会用到的,代码如下:
public class StandardSessionIdGeneratorextends SessionIdGeneratorBase{
@Override
publicString generateSessionId(String route) {
byterandom[] = newbyte[16];
int sessionIdLength = getSessionIdLength();
//Render the result as a String of hexadecimal digits
// Start with enough space forsessionIdLength and medium route size
StringBuilderbuffer = new StringBuilder(2 * sessionIdLength + 20);
int resultLenBytes = 0;
while (resultLenBytes < sessionIdLength) {
getRandomBytes(random);
for (int j = 0;
j < random.length && resultLenBytes < sessionIdLength;
j++) {
byte b1 = (byte) ((random[j] & 0xf0) >> 4);
byte b2 = (byte) (random[j] & 0x0f);
if (b1 < 10)
buffer.append((char) (\'0\' + b1));
else
buffer.append((char) (\'A\' + (b1 - 10)));
if (b2< 10)
buffer.append((char) (\'0\' + b2));
else
buffer.append((char) (\'A\' + (b2 - 10)));
resultLenBytes++;
}
}
if(route != null&& route.length() > 0) {
buffer.append(\'.\').append(route);
}else {
String jvmRoute =getJvmRoute();
if (jvmRoute != null && jvmRoute.length() > 0) {
buffer.append(\'.\').append(jvmRoute);
}
}
returnbuffer.toString();
}
}
最后几行代码显示如果在Cluster情况下会将jvmRoute加在sessionID后面。
Host
Host是代表虚拟主机,主要设置appbase目录,例如webapps等。Host中的name代表域名,所以下面的例子中代表的localhost,可以通过localhost来访问。appBase是指该站点所在的目录,默认一般是webapps。unpackWARs这个属性也很重要,一般来说,一个webapp的发布包有格式各样,例如zip,war等,对于war包放到appBase
下是否自动解压缩,显而易见,当为true时,自动解包。autoDeploy是指是指Tomcat在运行时应用程序是否自动部署。
<Host name="localhost" appBase="webapps" unpackWARs="true" autoDeploy="true">
Context
Context可以在以下几个地方声明:
1. Tomcat的server.xml配置文件中的<Context>节点用于配置Context,它直接在Tomcat解析server.xml的时候,就完成Context对象的创建。
2. Web应用的/META-INF/context.xml文件可用于配置Context,此配置文件用于配置Web应用对应的Context属性。
3. 可用%CATALINA_HOME%/conf[EngineName]/[HostName]/[Web项目名].xml文件声明创建一个Context。
4. Tomcat全局配置为conf/context.xml,此文件配置的属性会设置到所有的Context中
5. Tomcat的Host级别配置文件为/conf[EngineName]/[HostName]/context.xml.default文件,它配置的属性会设置到某Host下面所有的Context中。
以上5种方法有些是共享的,有些是独享的。其中后面2种是被Tomcat共享的。在实际的应用中,个人非常推荐第三种方法。如果在采用第一种方法,这种方法是有侵入性的,不建议,而且该文件是在Tomcat启动时才加载。对于共享的方法我个人也是不推荐使用的,毕竟在实际的应用中还是希望自己的app配置单独出来更合理一些。
Wrapper
Wrapper 代表一个Servlet,它负责管理一个Servlet,包括Servlet 的装载、初始化、执行以及资源回收。Wrapper的父容器一般是Context,Wrapper是最底层的容器,它没有子容器了,所以调用它的addChild 将会抛illegalargumentexception。Wrapper的实现类是StandardWrapper,StandardWrapper还实现了拥有一个Servlet 初始化信息的ServletConfig,由此看出StandardWrapper 将直接和Servlet 的各种信息打交道。
Container的启动
前面的类图讲过,前面提到的容容器都实现或继承了LifeCycle,所以LifeCycle里的几个生命周期同样适用于这里。不过除了继承自LifeCycle之外,几个容器也继承ContainerBase这个类。几个Container的初始化和启动都是通过initInternal和startInternal来实现的。需要的话,各个容器可以实现自己的逻辑。
因为4大容器都继承ContainerBase,我们看看该类的initInternal和startInternal的实现。
@Override protected void initInternal() throws LifecycleException { reconfigureStartStopExecutor(getStartStopThreads()); super.initInternal(); } /* * Implementation note: If there is ademand for more control than this then * it is likely that the best solutionwill be to reference an external * executor. */ private void reconfigureStartStopExecutor(int threads) { if (threads == 1) { //Use a fake executor if(!(startStopExecutorinstanceof InlineExecutorService)) { startStopExecutor = new InlineExecutorService(); } } else{ //Delegate utility execution to the Service Serverserver = Container.getService(this).getServer(); server.setUtilityThreads(threads); startStopExecutor= server.getUtilityExecutor(); } }
我们可以看到这里并没有设置一些状态。在初始化的过程中,初始化statStopExecutor,它的类型是java.util.concurrent.ExecutorService。
下面是startInternal的代码,我们可以看出这里做的事情:
1. 如果cluster和realm都配置后,需要调用它们自己的启动方法。
2. 调用子容器的启动方法。
3. 启动管道。
4. 设置生命周期的状态。
5. 同时启动一些background的监控线程。
@Override protected synchronized void startInternal() throws LifecycleException { // Start our subordinate components, if any logger = null; getLogger(); Cluster cluster = getClusterInternal(); if (cluster instanceof Lifecycle) { ((Lifecycle) cluster).start(); } Realm realm = getRealmInternal(); if (realm instanceof Lifecycle) { ((Lifecycle) realm).start(); } // Start our child containers, if any Container children[] = findChildren(); List<Future<Void>> results = new ArrayList<>(); for (int i = 0; i < children.length; i++) { results.add(startStopExecutor.submit(new StartChild(children[i]))); } MultiThrowable multiThrowable = null; for (Future<Void> result : results) { try { result.get(); } catch (Throwable e) { log.error(sm.getString("containerBase.threadedStartFailed"), e); if (multiThrowable == null) { multiThrowable = new MultiThrowable(); } multiThrowable.add(e); } } if (multiThrowable != null) { throw new LifecycleException(sm.getString("containerBase.threadedStartFailed"), multiThrowable.getThrowable()); } // Start the Valves in our pipeline (including the basic), if any if (pipeline instanceof Lifecycle) { ((Lifecycle) pipeline).start(); } setState(LifecycleState.STARTING); // Start our thread if (backgroundProcessorDelay > 0) { monitorFuture = Container.getService(ContainerBase.this).getServer() .getUtilityExecutor().scheduleWithFixedDelay( new ContainerBackgroundProcessorMonitor(), 0, 60, TimeUnit.SECONDS); } }
这里首先根据配置启动了Cluster和Realm,启动的方法也很直观,直接调用它们的start方法。Cluster一般用于集群,Realm是Tomcat的安全域,管理资源的访问权限,例如身份认证,权限等。一个Tomcat可以拥有多个Realm的。
根据代码,子容器是使用startStopExecutor来实现的,startStopExecutor会使用新的线程来启动,这样可以使用多个线程来同时启动多个子容器,这样在性能上更胜一筹。因为可能有多个子容器,把他们存入到Future的List里,然后遍历每个Future并调用其get方法。
遍历Future的作用是什么?1,get方法是阻塞的,只有线程处理完后才能继续往下走,这样保证了Pipeline启动之前容器确保调用完成。2,可以处理启动过程中的异常,如果有容器启动失败,也不至于继续执行下去。
启动子容器调用了StartChild这么一个类似,它的实现如下:
private static class StartChild implements Callable<Void> { private Container child; public StartChild(Container child) { this.child = child; } @Override public Void call() throws LifecycleException { child.start(); return null; } }
这个类也是定义在ContainerBase里的,所以所有容器的启动过程都对调用容器的start方法。
我们可以看到StartChild实现了Callable接口。我们知道启动线程,有Runnable和Callable等方式,那么Runnable和Callable的区别在哪里呢?我认为的区别是:
1. 对于实现Runnable,run方法并不会返回任何东西,但是对于Callable,真是可以实现当执行完成后返回结果的。但需要注意,一个线程并不能和Callable创建,尽可以和Runnable一起创建。
2. 另外一个区别就是Callable的Call方式可以抛出Exception,但是Runnable的run方法这不可以。
根据以上,我们可以看出为什么要用Callable,前面说捕获到异常也正是这个原理。
在这里我们也看到了Future这个东西。有必要在这里详细解释一下Future的概念。Future用来表示异步计算的结果,它提供了一些方法用来检查计算是否已经完成,或等待计算的完成以及获取计算的结果。计算结束后的结果只能通过get方法来获取。当然,也可以使用Cancel方法来取消计算。在回到我们这里的代码,如下,我们可以看到结果已经存在result里,通过get方法来获取,前面我们分析Callable可以抛出异常,这里我们可以看到有捕获到这些异常的代码。
for (Future<Void> result : results) { try { result.get(); } catch (Throwable e) { log.error(sm.getString("containerBase.threadedStartFailed"), e); if (multiThrowable == null) { multiThrowable = new MultiThrowable(); } multiThrowable.add(e); } }
Engine
Engine的默认实现类是StandardEngine,它的初始化和启动会调用initInternal和startInternal。下面是StandardEngine的结构图
初始化和启动的代码分别如下:
@Override protected void initInternal() throws LifecycleException { // Ensure that a Realm is present before any attempt is made to start // one. This will create the default NullRealm if necessary. getRealm(); super.initInternal(); } /** * Start this component and implement the requirements * of {@link org.apache.catalina.util.LifecycleBase#startInternal()}. * * @exception LifecycleException if this component detects a fatal error * that prevents this component from being used */ @Override protected synchronized void startInternal() throws LifecycleException { // Log our server identification information if (log.isInfoEnabled()) { log.info(sm.getString("standardEngine.start", ServerInfo.getServerInfo())); } // Standard container startup super.startInternal(); }
初始化和启动还是分别调用了ContainerBase的initInternal·和startInternal。特别要注意的是initInternal额外调用了getRealm获取Realm的信息。那么getRealm的实现如下:
@Override
public Realm getRealm() {
Realm configured = super.getRealm();
// If no set realm has been called - default to NullRealm
// This can be overridden at engine, context and host level
if (configured == null) {
configured = new NullRealm();
this.setRealm(configured);
}
return configured;
}
我们可以看出,如果没有realm配置,直接返回默认的NullRealm。
Host
Host的默认实现类是StandardHost,继承图如下。
下面代码只有startInternal,并没有initInternal,那是因为StandardHost并没有重写initInternal。
代码比较简单,除了调用ContainerBase的startInternal,前面还需要查询Pipeline里的Valve有没有和ErrorReport相关的。如果没有创建Valve一下,然后加到Pipeline里。
protected synchronized void startInternal() throws LifecycleException { // Set error report valve String errorValve = getErrorReportValveClass(); if ((errorValve != null) && (!errorValve.equals(""))) { try { boolean found = false; Valve[] valves = getPipeline().getValves(); for (Valve valve : valves) { if (errorValve.equals(valve.getClass().getName())) { found = true; break; } } if(!found) { Valve valve = (Valve) Class.forName(errorValve).getConstructor().newInstance(); getPipeline().addValve(valve); } } catch (Throwable t) { ExceptionUtils.handleThrowable(t); log.error(sm.getString( "standardHost.invalidErrorReportValveClass", errorValve), t); } } super.startInternal(); }
其中默认的ErrorReport Valve是
/** * The Java class name of the default error reporter implementation class * for deployed web applications. */ private String errorReportValveClass = "org.apache.catalina.valves.ErrorReportValve"
Context
下面是Context的初始化代码,后面调用了NamingResource相关信息。
@Override protected void initInternal() throws LifecycleException { super.initInternal(); // Register the naming resources if (namingResources != null) { namingResources.init(); } // Send j2ee.object.created notification if (this.getObjectName() != null) { Notification notification = new Notification("j2ee.object.created", this.getObjectName(), sequenceNumber.getAndIncrement()); broadcaster.sendNotification(notification); } }
接下来看看startInternal,这个方法非常长,节选重要代码.
如果resouce没有启动,需要调用resource的启动,接下来是调用web.xml中定义的Listener,另外还需要初始化该配置文件定义的Filter以及load-on-startup的Servlet。
protected synchronized void startInternal() throws LifecycleException { //… … if (ok) { resourcesStart(); } //… … // Configure and call application event listeners if (ok) { if (!listenerStart()) { log.error(sm.getString("standardContext.listenerFail")); ok = false; } } //…… // Configure and call application filters if (ok) { if (!filterStart()) { log.error(sm.getString("standardContext.filterFail")); ok = false; } } // Load and initialize all "load on startup" servlets if (ok) { if (!loadOnStartup(findChildren())){ log.error(sm.getString("standardContext.servletFail")); ok = false; } }
以上是关于深入浅出Tomcat/4 - Tomcat容器的主要内容,如果未能解决你的问题,请参考以下文章