Nginx的进程模型及高可用方案(OpenResty)
Posted 随风去。
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Nginx的进程模型及高可用方案(OpenResty)相关的知识,希望对你有一定的参考价值。
1. nginx 进程模型简介
Nginx默认采用多进程工作方式,Nginx启动后,会运行一个master进程和多个worker进程。其中master充当整个进程组与用户的交互接口,同时对进程进行监护,管理worker进程来实现重启服务、平滑升级、更换日志文件、配置文件实时生效等功能。worker用来处理基本的网络事件,worker之间是平等的,他们共同竞争来处理来自客户端的请求。生产环境一般采用的是多进程+多路复用的形式。这里可以从服务器上可以很直观的看到:

进程模型:
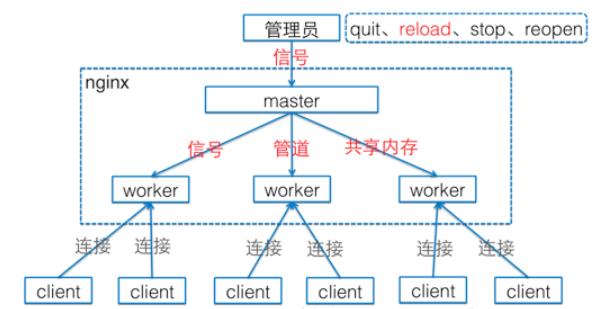
1. 在创建master进程时,先建立需要监听的socket(listenfd),然后从master进程中fork()出多个worker进程,如此一来每个worker进程都可以监听用户请求的socket。一般来说,当一个连接进来后,所有Worker都会收到通知,但是只有一个进程可以接受这个连接请求,其它的都失败,这是所谓的惊群现象。nginx提供了一个accept_mutex(互斥锁),有了这把锁之后,同一时刻,就只会有一个进程在accpet连接,这样就不会有惊群问题了。
2. 先打开accept_mutex选项,只有获得了accept_mutex的进程才会去添加accept事件。nginx使用一个叫ngx_accept_disabled的变量来控制是否去竞争accept_mutex锁。ngx_accept_disabled = nginx单进程的所有连接总数 / 8 -空闲连接数量,当ngx_accept_disabled大于0时,不会去尝试获取accept_mutex锁,ngx_accept_disable越大,让出的机会就越多,这样其它进程获取锁的机会也就越大。不去accept,每个worker进程的连接数就控制下来了,其它进程的连接池就会得到利用,这样,nginx就控制了多进程间连接的平衡。
3.每个worker进程都有一个独立的连接池,连接池的大小是worker_connections。这里的连接池里面保存的其实不是真实的连接,它只是一个worker_connections大小的一个ngx_connection_t结构的数组。并且,nginx会通过一个链表free_connections来保存所有的空闲ngx_connection_t,每次获取一个连接时,就从空闲连接链表中获取一个,用完后,再放回空闲连接链表里面。一个nginx能建立的最大连接数,应该是worker_connections * worker_processes。当然,这里说的是最大连接数,对于HTTP请求本地资源来说,能够支持的最大并发数量是worker_connections * worker_processes,而如果是HTTP作为反向代理来说,最大并发数量应该是worker_connections * worker_processes/2。因为作为反向代理服务器,每个并发会建立与客户端的连接和与后端服务的连接,会占用两个连接。
相关的配置:
worker_processes 1; // 工作进程数,建议设成CPU总核心数。
events { // 多路复用IO模型机制,epoll . select ....根据操作系统不同来选择。linux 默认epoll
use epoll; //io 模型
worker_connections 1024; // 每个woker进程的最大连接数,数值越大,并发量允许越大
}
http{
sendfile on;//开启零拷贝
}
2. Nginx 的高可用方案
Nginx 作为反向代理服务器,所有的流量都会经过 Nginx,所以 Nginx 本身的可靠性是我们首先要考虑的问题。
keepalived:
Keepalived 是 Linux 下一个轻量级别的高可用解决方案,Keepalived 软件起初是专为 LVS 负载均衡软件设计的,LVS 是 Linux Virtual Server 的缩写,也就是 Linux 虚拟服务器,在 linux2.4 内核以后,已经完全内置了 LVS 的各个功能模块。它是工作在四层的负载均衡,类似于 Haproxy, 主要用于实现对服务器集群的负载均衡。用来管理并监控 LVS 集群系统中各个服务节点的状态,后来又加入了可以实现高可用的 VRRP 功能。因此,Keepalived 除了能够管理 LVS 软件外,还可以作为其他服务(例如:Nginx、Haproxy、mysql 等)的高可用解决方案软件。
Keepalived 软件主要是通过 VRRP 协议实现高可用功能的。VRRP 是 Virtual Router RedundancyProtocol(虚拟路由器冗余协议)的缩写,VRRP 出现的目的就是为了解决静态路由单点故障问题的,它能够保证当个别节点宕机时,整个网络可以不间断地运行;(简单来说,vrrp 就是把两台或多态路由器设备虚拟成一个设备,实现主备高可用)。所以,Keepalived 一方面具有配置管理 LVS 的功能,同时还具有对 LVS 下面节点进行健康检查的功能,另一方面也可实现系统网络服务的高可用功能
关于四层负载,我们知道 osi 网络层次模型的 7 层模模型(应用层、表示层、会话层、传输层、网络层、数据链路层、物理层);四层负载就是基于传输层,也就是ip+端口的负载;而七层负载就是需要基于 URL 等应用层的信息来做负载,同时还有二层负载(基于 MAC)、三层负载(IP);常见的四层负载有:LVS、F5; 七层负载有:Nginx、HAproxy; 在软件层面,Nginx/LVS/HAProxy 是使用得比较广泛的三种负载均衡软件。
keepalived 安装:
1.tar -zxvf keepalived-2.0.10.tar.gz
2. ./configure --prefix=/data/program/keepalived --sysconf=/etc 我这边使用默认安装路径,执行./configure --sysconf=/etc 会安装到 /usr/local 下
3.如果缺少依赖库 安装 yum -y install pcre-devel zlib-devel openssl openssl-devel,yum install gcc gcc-c++
4.make && make install
5.进入安装后的路径 cd /usr/local, 创建软连接: ln -s sbin/keepalived /sbin
6.复制运行命令 cp /mysoft/keepalived-2.0.10/keepalived/etc/init.d/keepalived /etc/init.d/
7.添加到系统服务 chkconfig --add keepalived
8.启用该服务 systemctl enable keepalived.service

9.启动 service keepalived start 并查看状态,安装成功。在配置完conf文件后启动会有如下信息
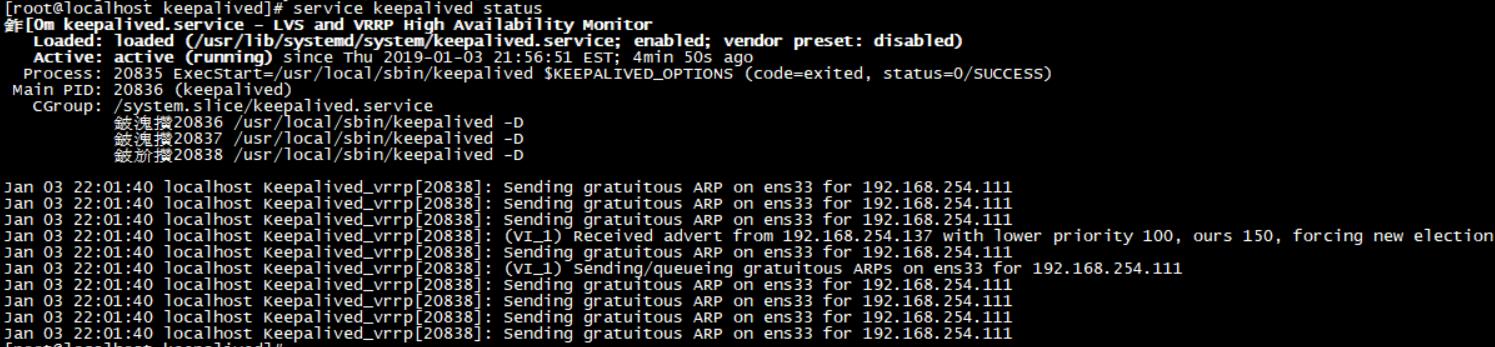
keepalived 的配置 vim /etc/keepalived/keepalived.conf,由于keepalive只作为vrrp协议的实现,负载代理的工作是交给后面的nginx或者haproxy来实现的。所以部署到一个节点上即可。
MASTER:(192.168.254.139)与nginx在同一个机器上
! Configuration File for keepalived
global_defs {
router_id MASTER_DEVEL #运行 keepalived 服务器的标识,在一个网络内应该是唯一的
}
vrrp_instance VI_1 { #vrrp 实例定义部分
state MASTER #设置 lvs 的状态,MASTER 和 BACKUP 两种,必须大写
interface ens33 #设置对外服务的接口
virtual_router_id 51 #设置虚拟路由标示,这个标示是一个数字,同一个 vrrp 实例使用唯一标示
priority 150 #定义优先级,数字越大优先级越高,在一个 vrrp——instance 下,master 的优先级必须大于 backup
advert_int 1 #设定 master 与 backup 负载均衡器之间同步检查的时间间隔,单位是秒
authentication { #设置验证类型和密码
auth_type PASS
auth_pass 1111 #验证密码,同一个 vrrp_instance 下 MASTER 和 BACKUP 密码必须相同}
virtual_ipaddress { #设置虚拟 ip 地址,可以设置多个,每行一个
192.168.254.111
}
}
virtual_server 192.168.254.111 80 { #设置虚拟服务器,需要指定虚拟 ip 和服务端口
delay_loop 6 #健康检查时间间隔
lb_algo rr #负载均衡调度算法
lb_kind NAT #负载均衡转发规则
persistence_timeout 50 #设置会话保持时间
protocol TCP #指定转发协议类型,有 TCP 和 UDP 两种
real_server 192.168.254.139 80 { #配置服务器节点 1,需要指定 real server 的真实 IP 地址和端口weight 1 #设置权重,数字越大权重越高
TCP_CHECK { #realserver 的状态监测设置部分单位秒
connect_timeout 3 #超时时间
delay_before_retry 3 #重试间隔
connect_port 80 #监测端口
}
}
}
BACKUP:(192.168.254.137)与nginx在同一个机器上
! Configuration File for keepalived
global_defs {
router_id BACKUP_DEVEL #运行 keepalived 服务器的标识,在一个网络内应该是唯一的
}
vrrp_instance VI_1 { #vrrp 实例定义部分
state BACKUP #设置 lvs 的状态,MASTER 和 BACKUP 两种,必须大写
interface ens33 #设置对外服务的接口
virtual_router_id 51 #设置虚拟路由标示,这个标示是一个数字,同一个 vrrp 实例使用唯一标示
priority 100 #定义优先级,数字越大优先级越高,在一个 vrrp——instance 下,master 的优先级必须大于 backup
advert_int 1 #设定 master 与 backup 负载均衡器之间同步检查的时间间隔,单位是秒
authentication { #设置验证类型和密码
auth_type PASS
auth_pass 1111 #验证密码,同一个 vrrp_instance 下 MASTER 和 BACKUP 密码必须相同}
virtual_ipaddress { #设置虚拟 ip 地址,可以设置多个,每行一个
192.168.254.111
}
}
virtual_server 192.168.254.111 80 { #设置虚拟服务器,需要指定虚拟 ip 和服务端口
delay_loop 6 #健康检查时间间隔
lb_algo rr #负载均衡调度算法
lb_kind NAT #负载均衡转发规则
persistence_timeout 50 #设置会话保持时间
protocol TCP #指定转发协议类型,有 TCP 和 UDP 两种
real_server 192.168.254.137 80 { #配置服务器节点 1,需要指定 real server 的真实 IP 地址和端口weight 1 #设置权重,数字越大权重越高
TCP_CHECK { #realserver 的状态监测设置部分单位秒
connect_timeout 3 #超时时间
delay_before_retry 3 #重试间隔
connect_port 80 #监测端口
}
}
}
通过脚本实现动态切换(与nginx心跳的绑定):
通过脚本的方式来检测 nginx 服务是否存活,一旦nginx挂了,那么可以通过这个机制把 keepalived 关闭,把机会让给哪些还存活的节点。详细配置如下:
首先编写shell 脚本:我这边是在keepalived.conf 所在目录下执行:vim vim nginx_service_check.sh,输入以下信息并保存。
#!bin/sh #! /bin/sh 是指此脚本使用/bin/sh 来执行
A=`ps -C nginx --no-header |wc -l`
if [ $A -eq 0 ]
then
echo \'nginx server is died\'
service keepalived stop
fi
可以通过sh nginx_service_check.sh 来验证该脚本是否正确。在nginx 没有启动的时候要是能输出如下信息就说明是OK的:

为给文件添加权限 : chmod +x nginx_service_check.sh 。
然后修改 keepalived.conf 文件:加入以下信息
global_defs {
router_id MASTER_DEVEL
enable_script_security
}
vrrp_script check_nginx_service {
script "/etc/keepalived/nginx_service_check.sh"
interval 3
weight -10
user root
}
#还有在vrrp_instance VI_1 这个模块中添加如下信息
vrrp_instance VI_1 {
track_script{
check_nginx_service
}
}
然后启动集群,把配置了该监听脚本的节点的nginx服务停掉,会发现此刻通过浏览器访问会切到另外一个节点上。说明配置完成,或者在nginx服务没有启动的时候去启动 keepalived 服务,会发现该服务无论如何都是无法启动的,启动后查看状态一直会是 dead 的状态。高可用方案到此结束。
3. OpenResty 安装及使用
OpenResty 是一个通过 Lua 扩展 Nginx 实现的可伸缩的 Web 平台,内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
安装:
1. 下载安装包 https://openresty.org/cn/download.html
2. 安装软件包 tar -zxvf openresty-1.13.6.2.tar.gz。cd openrestry-1.13.6.2。./configure [默认会安装在/usr/local/openresty 目录] --prefix= 指定路径。make && make install
3. 可能存在的错误,第三方依赖库没有安装的情况下会报错 yum install readline-devel / pcre-devel /openssl-devel
安装过程和 Nginx 是一样的,因为他是基于 Nginx 做的扩展。开始第一个程序,HelloWorld cd /usr/local/openresty/nginx/conf 编辑 nginx 配置文件 nginx.conf
location / {
default_type text/html;
content_by_lua_block {
ngx.say("helloworld");
}
}
在 sbin 目录下执行.nginx 命令就可以运行,访问可以看到 helloworld。
建立工作空间:
为了不影响默认的安装目录,我们可以创建一个独立的空间来练习,先到在安装目录下创建 demo 目录,安装目录为/usr/local/openresty .mkdir demo。然后在 demo 目录下创建三个子目录,一个是 logs 、一个是 conf,一个是 lua。
进接下去演示一个实现 API网关功能的简单demo,然后提供一个算法去计算传入参数a,b的和。入conf 创建配置文件 vim nginx.conf :
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
lua_package_path \'$prefix/lua/?.lua\'; //这里的¥prefix在启动的时候指定
lua_code_cache off; // lua脚本不需要重新加载
server {
listen 80;
// 正则匹配访问路径
location ~ ^/api/([-_a-zA-Z0-9]+) {
// 请求过滤一下
access_by_lua_file lua/check.lua;
content_by_lua_file lua/$1.lua;
}
}
}
当来到的请求符合 ^/api/([-_a-zA-Z0-9/] 时 会在NGX_HTTP_CONTENT_PHASE HTTP请求内容阶段 交给 lua/$1.lua来处理。比如:
/api/addition 交给 lua/addition.lua 处理。
/api/lua/substraction 交给 lua/substraction .lua 处理。
接下去创建 三个 lua 脚本:params.lua:
local _M ={} // 定义一个模块
//定义一个方法
//该方法用于判断参数是否为数字
function _M.is_number(...)
local args={...}
local num;
for i,v in ipairs(arg) do
num=tonumber(v);
if nil ==num then
return false;
end
end
return true;
end
//将该模块返回出去
return _M;
写一个用于起到网关过滤的检查脚本check.lua:
//导入模块
local param=require("params");
//获取uri的参数 local args=ngx.req.get_uri_args();
//判断a,b是否为空且是否为数字 if not args.a or not args.b or not param.is_number(args.a,args.b) then ngx.exit(ngx.HTTP_BAD_REQUEST); return; end
算法脚本 add.lua:
local args =ngx.req.get_uri_args(); ngx.say(args.a+args.b);
进入nginx的sbin目录执行:./nginx -p /usr/local/openresty/demo 【-p 主要是指明 nginx 启动时的配置目录】,此时会提示一个警告信息,无需理会,有强迫症把对应配置关了就还了:nginx: [alert] lua_code_cache is off; this will hurt performance in /usr/local/openresty/demo/conf/nginx.conf:12。通过访问http://192.168.254.137/api/add?a=1&b=3 能显示最后的值:
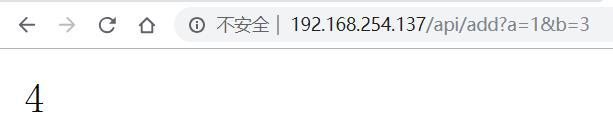
库文件使用:通过上面的案例,我们基本上对 openresty 有了一个更深的认识,其中我们用到了自定义的 lua 模块。实际上 openresty 提供了很丰富的模块。让我们在实现某些场景的时候更加方便。可以在 /openresty/lualib 目录下看到;比如在 resty 目录下可以看到 redis.lua、mysql.lua 这样的操作 redis 和操作数据库的模块。更多的库可以去百度,或者查找相关书籍。
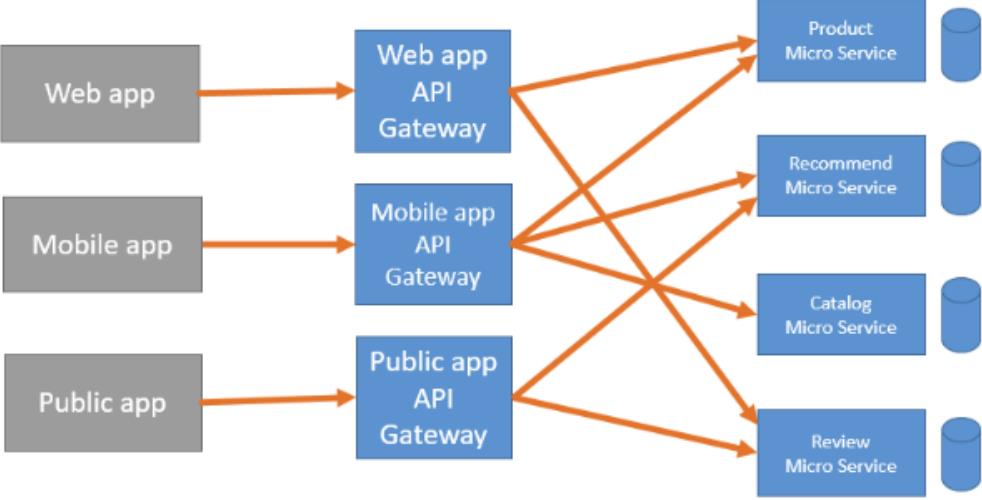
4.什么是API网关
从一个房间到另一个房间,必须必须要经过一扇门,同样,从一个网络向另一个网络发送信息,必须经过一道“关口”,这道关口就是网关。顾名思义,网关(Gateway)就是一个网络连接到另一个网络的“关口”。那什么是 api 网关呢?
在微服务流行起来之前,api 网关就一直存在,最主要的应用场景就是开放平台,也就是 open api; 这种场景大家接触的一定比较多,比如阿里的开放平台;当微服务流行起来以后,api 网关就成了上层应用集成的标配组件.
为什么需要网关?
对微服务组件地址进行统一抽象,API 网关意味着你要把 API 网关放到你的微服务的最前端,并且要让 API 网关变成由应用所发起的每个请求的入口。这样就可以简化客户端实现和微服务应用程序之间的沟通方式.
当服务越来越多以后,我们需要考虑一个问题,就是对某些服务进行安全校验以及用户身份校验。甚至包括对流量进行控制。 我们会对需要做流控、需要做身份认证的服务单独提供认证功能,但是服务越来越多以后,会发现很多组件的校验是重复的。这些东西很明显不是每个微服务组件需要去关心的事情。微服务组件只需要负责接收请求以及返回响应即可。可以把身份认证、流控都放在 API 网关层进行控制。
5. OpenResty 实现灰度发布功能
在单一架构中,随着代码量和业务量不断扩大,版本迭代会逐步变成一个很困难的事情,哪怕是一点小的修改,都必须要对整个应用重新部署。 但是在微服务中,各个模块是是一个独立运行的组件,版本迭代会很方便,影响面很小。同时,为服务化的组件节点,对于我们去实现灰度发布(金丝雀发布:将一部分流量引导到新的版本)来说,也会变的很简单;所以通过 API 网关,可以对指定调用的微服务版本,通过版本来隔离。如下图所示
OpenResty 实现 API 网关限流及登录授权
OpenResty 为什么能做网关?
前面我们了解到了网关的作用,通过网关,可以对 api 访问的前置操作进行统一的管理,比如鉴权、限流、负载均衡、日志收集、请求分片等。所以 API 网关的核心是所有客户端对接后端服务之前,都需要统一接入网关,通过网关层将所有非业务功能进行处理。OpenResty 为什么能实现网关呢? OpenResty 有一个非常重要的因素是,对于每一个请求,Openresty 会把请求分为不同阶段,从而可以让第三方模块通过挂载行为来实现不同阶段的自定义行为。而这样的机制能够让我们非常方便的设计 api 网关。
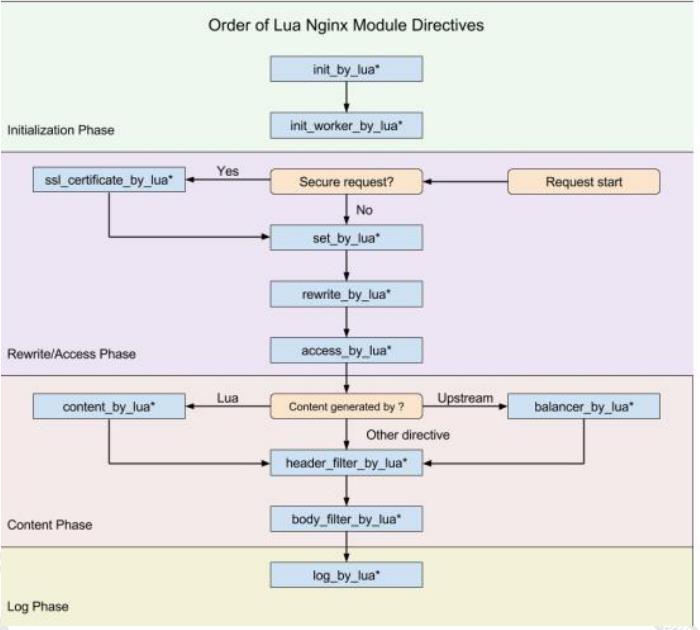
Nginx 本身在处理一个用户请求时,会按照不同的阶段进行处理,总共会分为 11个阶段。而 openresty 的执行指令,就是在这 11 个步骤中挂载 lua 执行脚本实现扩展,我们分别看看每个指令的作用
init_by_lua : 当 Nginx master 进程加载 nginx 配置文件时会运行这段 lua 脚本,一般用来注册全局变量或者预加载 lua 模块。
init_woker_by_lua: 每个 Nginx worker 进程启动时会执行的 lua 脚本,可以用来做健康检查。
set_by_lua:设置一个变量。
rewrite_by_lua:在 rewrite 阶段执行,为每个请求执行指定的 lua 脚本。
access_by_lua:为每个请求在访问阶段调用 lua 脚本。
content_by_lua:前面演示过,通过 lua 脚本生成 content 输出给 http 响应。
balancer_by_lua:实现动态负载均衡,如果不是走 contentbylua,则走 proxy_pass,再通过 upstream 进行转发。
header_filter_by_lua: 通过 lua 来设置 headers 或者 cookie。
body_filter_by_lua:对响应数据进行过滤。
log_by_lua : 在 log 阶段执行的脚本,一般用来做数据统计,将请求数据传输到后端进行分析。
灰度发布的实现:
1.跟前面一样创建一个新的工作空间 mkdir gray。然后在 demo 目录下创建三个子目录,一个是 logs 、一个是 conf,一个是 lua。
2.编写 Nginx 的配置文件 nginx.conf
worker_processes 1;
error_log logs/error.log;
events{
worker_connections 1024;
}
http{
lua_package_path "$prefix/lualib/?.lua;;";
lua_package_cpath "$prefix/lualib/?.so;;";
//生产环境
upstream prod {//tomcat地址
server 192.168.254.137:8080;
}
// 预生产环境
upstream pre {//tomcat地址
server 192.168.254.139:8080;
}
server {
listen 80;
server_name localhost;
//当访问该路径就会进入lua脚本
location / {
content_by_lua_file lua/gray.lua;
}
// 定义变量在lua中会使用
location @prod {
proxy_pass http://prod;
}
location @pre {
proxy_pass http://pre;
}
}
}
3.编写 gray.lua 文件
local redis=require "resty.redis";
local red=redis:new();
red:set_timeout(1000);
local ok,err=red:connect("192.168.254.138",6379);
if not ok then
ngx.say("failed to connect redis",err);
return;
end
ok, err = red:auth("wuzhenzhao");
local_ip=ngx.var.remote_addr;
local ip_lists=red:get("gray");
if string.find(ip_lists,local_ip) == nil then
ngx.exec("@prod");
else
ngx.exec("@pre");
end
local ok,err=red:close();
4.
1.进入sbin目录 执行命令启动 nginx: ./nginx -p /usr/local/openresty/gray
2. 启动 redis,并设置 set gray 192.168.254.1,由于我这边是访问虚拟机,所以我本地ip去访问就是这个。
3. 通过浏览器运行: http://192.168.254.137/查看运行结果
修改 redis gray 的值, 到 redis 中 set gray 192.168.254.2. 再次运行结果,即可看到访问结果已经发生了变化.
以上是关于Nginx的进程模型及高可用方案(OpenResty)的主要内容,如果未能解决你的问题,请参考以下文章