etcd集群搭建(高可用)
Posted 51wansheng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了etcd集群搭建(高可用)相关的知识,希望对你有一定的参考价值。
一、etcd介绍:
ETCD 是一个高可用的分布式键值数据库,可用于服务发现。ETCD 采用 raft 一致性算法,基于 Go 语言实现。etcd作为一个高可用键值存储系统,天生就是为集群化而设计的。由于Raft算法在做决策时需要多数节点的投票,所以etcd一般部署集群推荐奇数个节点,推荐的数量为3、5或者7个节点构成一个集群。
二、特点:
实际上,etcd作为一个受到Zookeeper与doozer启发而催生的项目,除了拥有与之类似的功能外,更具有以下4个特点{![引自Docker官方文档]}。
- 简单:基于HTTP+JSON的API让你用curl命令就可以轻松使用。
- 安全:可选SSL客户认证机制。
- 快速:每个实例每秒支持一千次写操作。
- 可信:使用Raft算法充分实现了分布式。
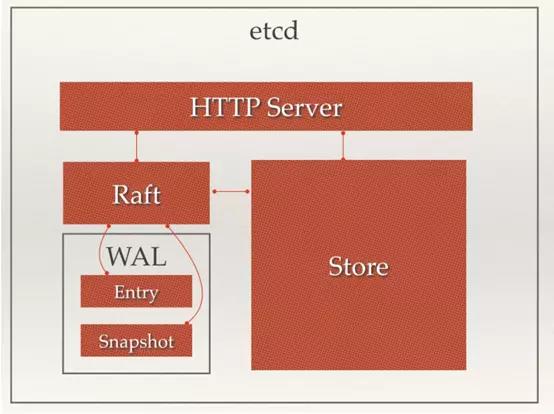
三、etcd关键词汇
- Raft:etcd所采用的保证分布式系统强一致性的算法。
- Node:一个Raft状态机实例。
- Member: 一个etcd实例。它管理着一个Node,并且可以为客户端请求提供服务。
- Cluster:由多个Member构成可以协同工作的etcd集群。
- Peer:对同一个etcd集群中另外一个Member的称呼。
- Client: 向etcd集群发送HTTP请求的客户端。
- WAL:预写式日志,etcd用于持久化存储的日志格式。
- snapshot:etcd防止WAL文件过多而设置的快照,存储etcd数据状态。
- Proxy:etcd的一种模式,为etcd集群提供反向代理服务。
- Leader:Raft算法中通过竞选而产生的处理所有数据提交的节点。
- Follower:竞选失败的节点作为Raft中的从属节点,为算法提供强一致性保证。
- Candidate:当Follower超过一定时间接收不到Leader的心跳时转变为Candidate开始Leader竞选。
- Term:某个节点成为Leader到下一次竞选开始的时间周期,称为一个Term。
- Index:数据项编号。Raft中通过Term和Index来定位数据。
四、etcd应用场景:
1、服务发现:
服务发现(Service Discovery)要解决的是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务如何才能找到对方并建立连接。从本质上说,服务发现就是想要了解集群中是否有进程在监听udp或tcp端口,并且通过名字就可以进行查找和连接。
2、消息发布与订阅:
在分布式系统中,最为适用的组件间通信方式是消息发布与订阅机制。具体而言,即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦相关主题有消息发布,就会实时通知订阅者。通过这种方式可以实现分布式系统配置的集中式管理与实时动态更新
- 应用中用到的一些配置信息存放在etcd上进行集中管理。这类场景的使用方式通常是这样的:应用在启动的时候主动从etcd获取一次配置信息,同时,在etcd节点上注册一个Watcher并等待,以后每次配置有更新的时候,etcd都会实时通知订阅者,以此达到获取最新配置信息的目的。
- 分布式搜索服务中,索引的元信息和服务器集群机器的节点状态信息存放在etcd中,供各个客户端订阅使用。使用etcd的
key TTL功能可以确保机器状态是实时更新的。 - 分布式日志收集系统。这个系统的核心工作是收集分布在不同机器上的日志。收集器通常按照应用(或主题)来分配收集任务单元,因此可以在etcd上创建一个以应用(或主题)命名的目录P,并将这个应用(或主题)相关的所有机器ip,以子目录的形式存储在目录P下,然后设置一个递归的etcd Watcher,递归式地监控应用(或主题)目录下所有信息的变动。这样就实现了在机器IP(消息)发生变动时,能够实时通知收集器调整任务分配。
- 系统中信息需要动态自动获取与人工干预修改信息请求内容的情况。通常的解决方案是对外暴露接口,例如JMX接口,来获取一些运行时的信息或提交修改的请求。而引入etcd之后,只需要将这些信息存放到指定的etcd目录中,即可通过HTTP接口直接被外部访问。
3、负载均衡:
在分布式系统中,为了保证服务的高可用以及数据的一致性,通常都会把数据和服务部署多份,以此达到对等服务,即使其中的某一个服务失效了,也不影响使用。这样的实现虽然会导致一定程度上数据写入性能的下降,但是却能实现数据访问时的负载均衡。因为每个对等服务节点上都存有完整的数据,所以用户的访问流量就可以分流到不同的机器上。
- etcd本身分布式架构存储的信息访问支持负载均衡。etcd集群化以后,每个etcd的核心节点都可以处理用户的请求。所以,把数据量小但是访问频繁的消息数据直接存储到etcd中也是个不错的选择,如业务系统中常用的二级代码表。二级代码表的工作过程一般是这样,在表中存储代码,在etcd中存储代码所代表的具体含义,业务系统调用查表的过程,就需要查找表中代码的含义。所以如果把二级代码表中的小量数据存储到etcd中,不仅方便修改,也易于大量访问。
- 利用etcd维护一个负载均衡节点表。etcd可以监控一个集群中多个节点的状态,当有一个请求发过来后,可以轮询式地把请求转发给存活着的多个节点。类似KafkaMQ,通过Zookeeper来维护生产者和消费者的负载均衡。同样也可以用etcd来做Zookeeper的工作。
4、分布式通知与协调:
这里讨论的分布式通知与协调,与消息发布和订阅有些相似。两者都使用了etcd中的Watcher机制,通过注册与异步通知机制,实现分布式环境下不同系统之间的通知与协调,从而对数据变更进行实时处理。实现方式通常为:不同系统都在etcd上对同一个目录进行注册,同时设置Watcher监控该目录的变化(如果对子目录的变化也有需要,可以设置成递归模式),当某个系统更新了etcd的目录,那么设置了Watcher的系统就会收到通知,并作出相应处理。
- 通过etcd进行低耦合的心跳检测。检测系统和被检测系统通过etcd上某个目录关联而非直接关联起来,这样可以大大减少系统的耦合性。
- 通过etcd完成系统调度。某系统有控制台和推送系统两部分组成,控制台的职责是控制推送系统进行相应的推送工作。管理人员在控制台做的一些操作,实际上只需要修改etcd上某些目录节点的状态,而etcd就会自动把这些变化通知给注册了Watcher的推送系统客户端,推送系统再做出相应的推送任务。
- 通过etcd完成工作汇报。大部分类似的任务分发系统,子任务启动后,到etcd来注册一个临时工作目录,并且定时将自己的进度进行汇报(将进度写入到这个临时目录),这样任务管理者就能够实时知道任务进度。
5、分布式锁:
因为etcd使用Raft算法保持了数据的强一致性,某次操作存储到集群中的值必然是全局一致的,所以很容易实现分布式锁。锁服务有两种使用方式,一是保持独占,二是控制时序。
- 保持独占,即所有试图获取锁的用户最终只有一个可以得到。etcd为此提供了一套实现分布式锁原子操作CAS(
CompareAndSwap)的API。通过设置prevExist值,可以保证在多个节点同时创建某个目录时,只有一个成功,而该用户即可认为是获得了锁。 - 控制时序,即所有试图获取锁的用户都会进入等待队列,获得锁的顺序是全局唯一的,同时决定了队列执行顺序。etcd为此也提供了一套API(自动创建有序键),对一个目录建值时指定为
POST动作,这样etcd会自动在目录下生成一个当前最大的值为键,存储这个新的值(客户端编号)。同时还可以使用API按顺序列出所有当前目录下的键值。此时这些键的值就是客户端的时序,而这些键中存储的值可以是代表客户端的编号。
五、搭建集群
主机信息:
| 角色 | 系统 | 节点 |
| master | CentOS-7 | 192.168.10.5 |
| node-1 | CentOS-7 | 192.168.10.6 |
| node-2 | CentOS-7 | 192.168.10.7 |
配置阿里epel源:
mv /etc/yum.repos.d/epel.repo /etc/yum.repos.d/epel.repo.backup
mv /etc/yum.repos.d/epel-testing.repo /etc/yum.repos.d/epel-testing.repo.backup
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
安装配置存储etcd(高可用):
1、在三台安装etcd(集群)、做高可用
[root@node1 ~]# yum -y install etcd [root@node2 ~]# yum -y install etcd [root@master ~]# yum -y install etcd [root@master ~]# etcd --version etcd Version: 3.2.22 Git SHA: 1674e68 Go Version: go1.9.4 Go OS/Arch: linux/amd64
2 配置文件修改
master节点
[root@master ~]# egrep -v "^$|^#" /etc/etcd/etcd.conf
ETCD_DATA_DIR="/var/lib/etcd/default.etcd" #etcd数据保存目录 ETCD_LISTEN_PEER_URLS="http://192.168.10.5:2380" #集群内部通信使用的URL ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379" #供外部客户端使用的url ETCD_NAME="etcd01" #etcd实例名称 ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.10.5:2380" #广播给集群内其他成员访问的URL ETCD_ADVERTISE_CLIENT_URLS="http://0.0.0.0:2379" #广播给外部客户端使用的url ETCD_INITIAL_CLUSTER="etcd01=http://192.168.10.5:2380,etcd02=http://192.168.10.6:2380,etcd03=http://192.168.10.7:2380" #初始集群成员列表 ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" #集群的名称 ETCD_INITIAL_CLUSTER_STATE="new" #初始集群状态,new为新建集群
node-1
[root@node1 etcd]# egrep -v "^$|^#" /etc/etcd/etcd.conf ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="http://192.168.10.6:2380" ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379" ETCD_NAME="etcd02" ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.10.6:2380" ETCD_ADVERTISE_CLIENT_URLS="http://0.0.0.0:2379" ETCD_INITIAL_CLUSTER="etcd01=http://192.168.10.5:2380,etcd02=http://192.168.10.6:2380,etcd03=http://192.168.10.7:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="exist"
node-2
[root@node2 ~]# egrep -v "^$|^#" /etc/etcd/etcd.conf ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="http://192.168.10.7:2380" ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379" ETCD_NAME="etcd03" ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.10.7:2380" ETCD_ADVERTISE_CLIENT_URLS="http://0.0.0.0:2379" ETCD_INITIAL_CLUSTER="etcd01=http://192.168.10.5:2380,etcd02=http://192.168.10.6:2380,etcd03=http://192.168.10.7:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="exist"
分别进行启动:
[root@master etcd]# systemctl start etcd [root@master etcd]# systemctl status etcd ● etcd.service - Etcd Server Loaded: loaded (/usr/lib/systemd/system/etcd.service; disabled; vendor preset: disabled) Active: active (running) since Tue 2019-01-08 17:28:34 CST; 2h 32min ago Main PID: 114077 (etcd) Tasks: 7 Memory: 48.7M CGroup: /system.slice/etcd.service └─114077 /usr/bin/etcd --name=etcd01 --data-dir=/var/lib/etcd/default.etcd --listen-client-urls=http://0.0.0.0:2379 Jan 08 20:00:08 master etcd[114077]: 4c5d727d37966a87 became candidate at term 16 Jan 08 20:00:08 master etcd[114077]: 4c5d727d37966a87 received MsgVoteResp from 4c5d727d37966a87 at term 16 Jan 08 20:00:08 master etcd[114077]: 4c5d727d37966a87 [logterm: 11, index: 44] sent MsgVote request to 315fd62e577c4037 at term 16 Jan 08 20:00:08 master etcd[114077]: 4c5d727d37966a87 [logterm: 11, index: 44] sent MsgVote request to f617da66fb9b90ad at term 16 Jan 08 20:00:08 master etcd[114077]: 4c5d727d37966a87 received MsgVoteResp from f617da66fb9b90ad at term 16 Jan 08 20:00:08 master etcd[114077]: 4c5d727d37966a87 [quorum:2] has received 2 MsgVoteResp votes and 0 vote rejections Jan 08 20:00:08 master etcd[114077]: 4c5d727d37966a87 became leader at term 16 Jan 08 20:00:08 master etcd[114077]: raft.node: 4c5d727d37966a87 elected leader 4c5d727d37966a87 at term 16 Jan 08 20:00:09 master etcd[114077]: the clock difference against peer 315fd62e577c4037 is too high [4.285950016s > 1s] Jan 08 20:00:09 master etcd[114077]: the clock difference against peer f617da66fb9b90ad is too high [4.120954945s > 1s]
[root@master etcd]# netstat -tunlp|grep etcd tcp 0 0 192.168.10.5:2380 0.0.0.0:* LISTEN 114077/etcd tcp6 0 0 :::2379 :::* LISTEN 114077/etcd
3、etc集群测试
集群数据操作命令:
查看集群节点
[root@node1 etcd]# etcdctl member list 315fd62e577c4037: name=etcd03 peerURLs=http://192.168.10.7:2380 clientURLs=http://0.0.0.0:2379 isLeader=false 4c5d727d37966a87: name=etcd01 peerURLs=http://192.168.10.5:2380 clientURLs=http://0.0.0.0:2379 isLeader=true f617da66fb9b90ad: name=etcd02 peerURLs=http://192.168.10.6:2380 clientURLs=http://0.0.0.0:2379 isLeader=false
查看集群健康状态:
[root@master etcd]# etcdctl cluster-health
member 315fd62e577c4037 is healthy: got healthy result from http://0.0.0.0:2379
member 4c5d727d37966a87 is healthy: got healthy result from http://0.0.0.0:2379
member f617da66fb9b90ad is healthy: got healthy result from http://0.0.0.0:2379
cluster is healthy
设置键值:
在一个节点设置值
[root@master etcd]# etcdctl set /test/key "test kubernetes" test kubernetes
在另一个节点获取值
[root@node1 etcd]# etcdctl get /test/key
test kubernetes
- key存在的方式和zookeeper类似,为
/路径/key - 设置完之后,其他集群也可以查询到该值
- 如果
dir和key不存在,该命令会创建对应的项
更新键值:
[root@master etcd]# etcdctl update /test/key "test kubernetes cluster" test kubernetes cluster
[root@node1 etcd]# etcdctl get /test/key test kubernetes cluster
删除键值:
[root@master etcd]# etcdctl rm /test/key PrevNode.Value: test kubernetes cluster
当键不存在时,会报错 [root@node1 etcd]# etcdctl get /test/key Error: 100: Key not found (/test/key) [15]
etcd帮助:
[root@master etcd]# etcdctl help NAME: etcdctl - A simple command line client for etcd. WARNING: Environment variable ETCDCTL_API is not set; defaults to etcdctl v2. Set environment variable ETCDCTL_API=3 to use v3 API or ETCDCTL_API=2 to use v2 API. USAGE: etcdctl [global options] command [command options] [arguments...] VERSION: 3.2.22 COMMANDS: backup backup an etcd directory cluster-health check the health of the etcd cluster mk make a new key with a given value mkdir make a new directory rm remove a key or a directory rmdir removes the key if it is an empty directory or a key-value pair get retrieve the value of a key ls retrieve a directory set set the value of a key setdir create a new directory or update an existing directory TTL update update an existing key with a given value updatedir update an existing directory watch watch a key for changes exec-watch watch a key for changes and exec an executable member member add, remove and list subcommands user user add, grant and revoke subcommands role role add, grant and revoke subcommands auth overall auth controls help, h Shows a list of commands or help for one command
参考文档:
https://github.com/etcd-io/etcd
https://yq.aliyun.com/articles/623228
https://blog.csdn.net/hxpjava1/article/details/78275995
以上是关于etcd集群搭建(高可用)的主要内容,如果未能解决你的问题,请参考以下文章