hue的使用
Posted 捡黄金的少年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hue的使用相关的知识,希望对你有一定的参考价值。
Hue是一个开源的Apache Hadoop UI系统,由Cloudera Desktop演化而来,最后Cloudera公司将其贡献给Apache基金会的Hadoop社区,它是基于Python Web框架Django实现的。
通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job,执行Hive的SQL语句,浏览HBase数据库等等。
1、hue介绍
· Site: Hue - The open source SQL Assistant for Data Warehouses
· Github: GitHub - cloudera/hue: Open source SQL Query Assistant service for Databases/Warehouses
· Reviews: https://review.cloudera.org
SQL编辑器,支持Hive, Impala, mysql, Oracle, PostgreSQL, SparkSQL, Solr SQL, Phoenix…
· 搜索引擎Solr的各种图表
· Spark和Hadoop的友好界面支持
· 支持调度系统Apache Oozie,可进行workflow的编辑、查看
HUE提供的这些功能相比Hadoop生态各组件提供的界面更加友好,但是一些需要debug的场景可能还是需要使用原生系统才能更加深入的找到错误的原因。
HUE中查看Oozie workflow时,也可以很方便的看到整个workflow的DAG图,不过在最新版本中已经将DAG图去掉了,只能看到workflow中的action列表和他们之间的跳转关系,想要看DAG图的仍然可以使用oozie原生的界面系统查看。
1,访问HDFS和文件浏览
2,通过web调试和开发hive以及数据结果展示
3,查询solr和结果展示,报表生成
4,通过web调试和开发impala交互式SQL Query
5,spark调试和开发
7,oozie任务的开发,监控,和工作流协调调度
8,Hbase数据查询和修改,数据展示
9,Hive的元数据(metastore)查询
10,MapReduce任务进度查看,日志追踪
11,创建和提交MapReduce,Streaming,Java job任务
12,Sqoop2的开发和调试
13,Zookeeper的浏览和编辑
14,数据库(MySQL,PostGres,SQlite,Oracle)的查询和展示
一句话总结:Hue是一个友好的界面集成框架,可以集成我们各种学习过的以及将要学习的框架,一个界面就可以做到查看以及执行所有的框架
2、hue安装
Hue的压缩包的下载地址:
http://archive.cloudera.com/cdh5/cdh/5/
我们这里使用的是CDH5.14.2这个对应的版本,具体下载地址为
http://archive.cloudera.com/cdh5/cdh/5/hue-3.9.0-cdh5.14.2.tar.gz
1、下载然后上传到node03服务器的/kkb/soft路径下
cd /kkb/soft
tar -zxvf hue-3.9.0-cdh5.14.2.tar.gz -C /kkb/install
2、联网安装各种必须的依赖包
sudo yum install ant asciidoc cyrus-sasl-devel cyrus-sasl-gssapi cyrus-sasl-plain gcc gcc-c++ krb5-devel libffi-devel libxml2-devel libxslt-devel make mysql mysql-devel openldap-devel python-devel sqlite-devel gmp-devel libffi gcc gcc-c++ kernel-devel openssl-devel gmp-devel openldap-devel
3、配置 hue.ini
cd /kkb/install/hue-3.9.0-cdh5.14.2/desktop/conf
vim hue.ini
#通用配置[desktop]
secret_key=jFE93j;2[290-eiw.KEiwN2s3['d;/.q[eIW^y#e=+Iei*@Mn<qW5o
http_host=node03
is_hue_4=true
time_zone=Asia/Shanghai
server_user=hadoop
server_group=hadoop
default_user=hadoop
default_hdfs_superuser=hadoop#配置使用mysql作为hue的存储数据库,大概在hue.ini的587行左右
[[database]]
engine=mysql
host=node03
port=3306
user=root
password=123456
name=hue
4、创建MySQL数据库
创建hue数据库
create database hue default character set utf8 default collate utf8_general_ci;
注意:实际工作中,还需要为hue这个数据库创建对应的用户,并分配权限,我这就不创建了,所以下面这一步不用执行了
grant all on hue.* to 'hue'@'%' identified by 'hue';
5、node03服务器执行以下命令准备进行编译
cd /kkb/install/hue-3.9.0-cdh5.14.2
sudo make apps
6、linux系统添加普通用户hue
sudo useradd hue
sudo passwd hue
7、启动hue
node03执行以下命令启动hue
cd /kkb/install/hue-3.9.0-cdh5.14.2
sudo build/env/bin/supervisor
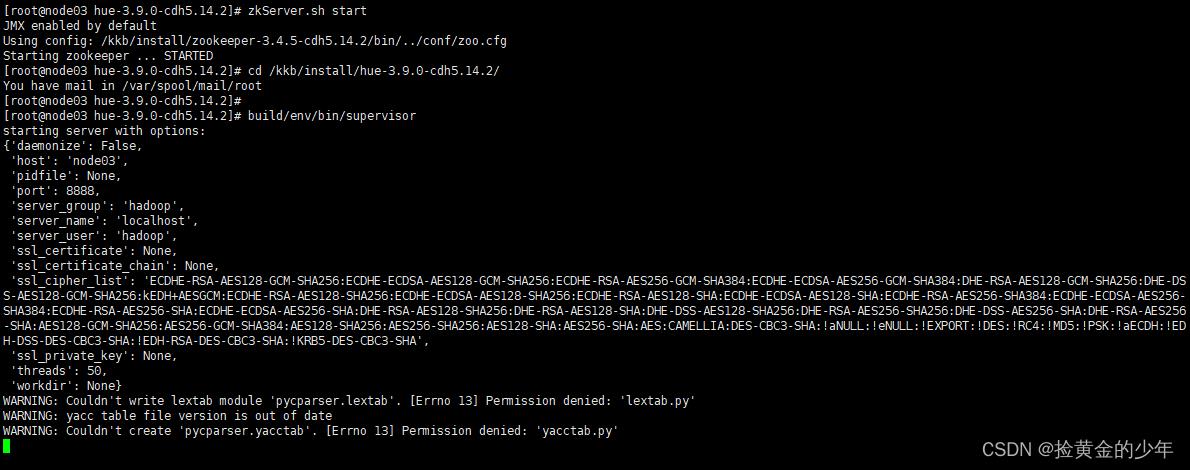
第一次访问的时候,需要设置管理员用户和密码
我们这里的管理员的用户名与密码尽量保持与我们安装hadoop的用户名和密码一致,
我们安装hadoop的用户名与密码分别是hadoop 123456
初次登录使用hadoop,密码为123456
进入之后发现我们的hue页面报错了,这个错误主要是因为hive的原因,因为我们的hue与hive集成的时候出错了,所以我们需要配置我们的hue与hive进行集成,接下里就看看我们的hue与hive以及hadoop如何进行集成
1、hue集成HDFS
记得更改完core-site.xml之后一定要重启hdfs与yarn集群
1、集群机器更改core-site.xml
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property><property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
使用scp -r 拷贝到其他集群上去
scp -r /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/core-site.xml node02: /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/
2、更改所有hadoop节点的hdfs-site.xml
所有服务器更改hdfs-site.xml添加以下配置
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
3、重启HDFS
cd /kkb/install/hadoop-2.6.0-cdh5.14.2
sbin/stop-dfs.sh
sbin/start-dfs.sh
sbin/stop-yarn.sh
sbin/start-yarn.sh
4、停止hue的服务,并继续配置hue.ini
停止hue的服务,然后进入到以下路径,重新配置hue.ini这个配置文件
cd /kkb/install/hue-3.9.0-cdh5.14.2/desktop/conf
vim hue.ini
#配置我们的hue与hdfs集成]]
[[hdfs_clusters]]
[[[default]]]
fs_defaultfs=hdfs://node01:8020
webhdfs_url=http://node01:50070/webhdfs/v1
hadoop_hdfs_home=/kkb/install/hadoop-2.6.0-cdh5.14.2
hadoop_bin=/kkb/install/hadoop-2.6.0-cdh5.14.2/bin
hadoop_conf_dir=/kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop#配置我们的hue与yarn集成
[[yarn_clusters]]
[[[default]]]
resourcemanager_host=node01
resourcemanager_port=8032
submit_to=True
resourcemanager_api_url=http://node01:8088
history_server_api_url=http://node01:19888
5、配置完成之后重新启动hue的服务
node03执行以下命令进行重新启动hue的服务
cd /kkb/install/hue-3.9.0-cdh5.14.2/
build/env/bin/supervisor

这样就可以对HDFS 的数据进行查看修改。
2、配置hue与hive集成
如果需要配置hue与hive的集成,我们需要启动hive的metastore服务以及hiveserver2服务(impala需要hive的metastore服务,hue需要hvie的hiveserver2服务)
1、修改hue.ini
cd /kkb/install/hue-3.9.0-cdh5.14.2/desktop/conf
vim hue.ini[beeswax]
hive_server_host=node03
hive_server_port=10000
hive_conf_dir=/kkb/install/hive-1.1.0-cdh5.14.2/conf
server_conn_timeout=120
auth_username=hadoop
auth_password=123456
[metastore]#允许使用hive创建数据库表等操作
enable_new_create_table=true
2、启动hive的metastore服务
去node03机器上启动hive的metastore以及hiveserver2服务
nohup hive --service metastore &
nohup hive --service hiveserver2 &
重新启动hue,然后就可以通过浏览器页面操作hive了
node03执行以下命令进行重新启动hue的服务
cd /kkb/install/hue-3.9.0-cdh5.14.2/
build/env/bin/supervisor
3、hue与mysql的集成
1、停止hue的服务,然后修改hue.ini
cd /kkb/install/hue-3.9.0-cdh5.14.2/desktop/conf
vim hue.ini[[[mysql]]]
nice_name="My SQL DB"
engine=mysql
host=node03.kaikeba.com
port=3306
user=root
password=123456
2、重新启动hue的服务
cd /kkb/install/hue-3.9.0-cdh5.14.2/
build/env/bin/supervisor
4、hue与hbas的集成
1、停止hue的服务,然后修改hue.ini
cd /kkb/install/hue-3.9.0-cdh5.14.2/desktop/conf
vim hue.ini
[hbase]
hbase_clusters=(Cluster|node01:9090)
hbase_conf_dir=/kkb/install/hbase-1.2.0-cdh5.14.2/conf
2:启动hbase的thrift server服务
start-hbase.sh
hbase-daemon.sh start thrift
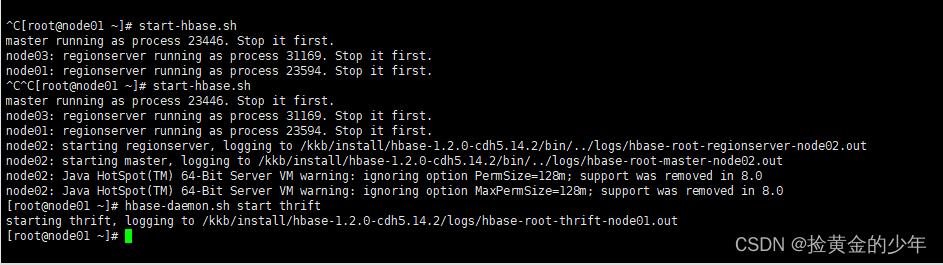
3、重新启动hue的服务
cd /kkb/install/hue-3.9.0-cdh5.14.2/
build/env/bin/supervisor
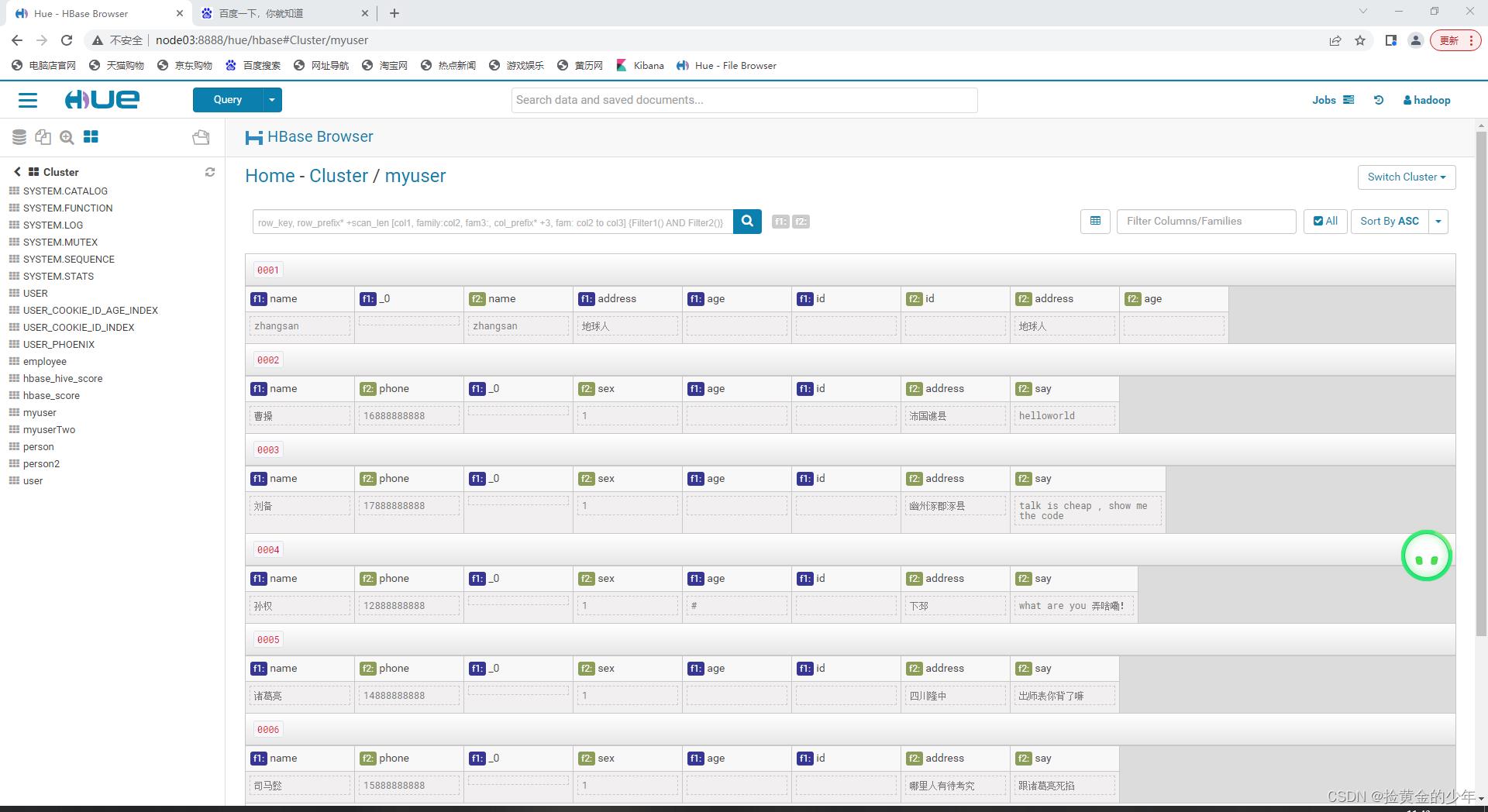
以上是关于hue的使用的主要内容,如果未能解决你的问题,请参考以下文章