c语言过程栈机制详解
Posted zkccpro
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了c语言过程栈机制详解相关的知识,希望对你有一定的参考价值。
c语言过程栈机制详解
先声明,下面的图来自于B站up主——九曲阑干 的视频课程,讲计算机组成原理十分简练通透!想学CSAPP的小伙伴可以看书+看他的视频!本文来自对视频内容的整理加上一些自己个人的逻辑和理解。
过程栈在c/c++中起着很重要的角色,为了更深入地理解一个c/c++程序是如何运作的、程序core时我们该怎么查找问题,弄清楚过程栈机制都是很有必要的!
一、 汇编语言基础
1. c程序从源文件到执行的过程
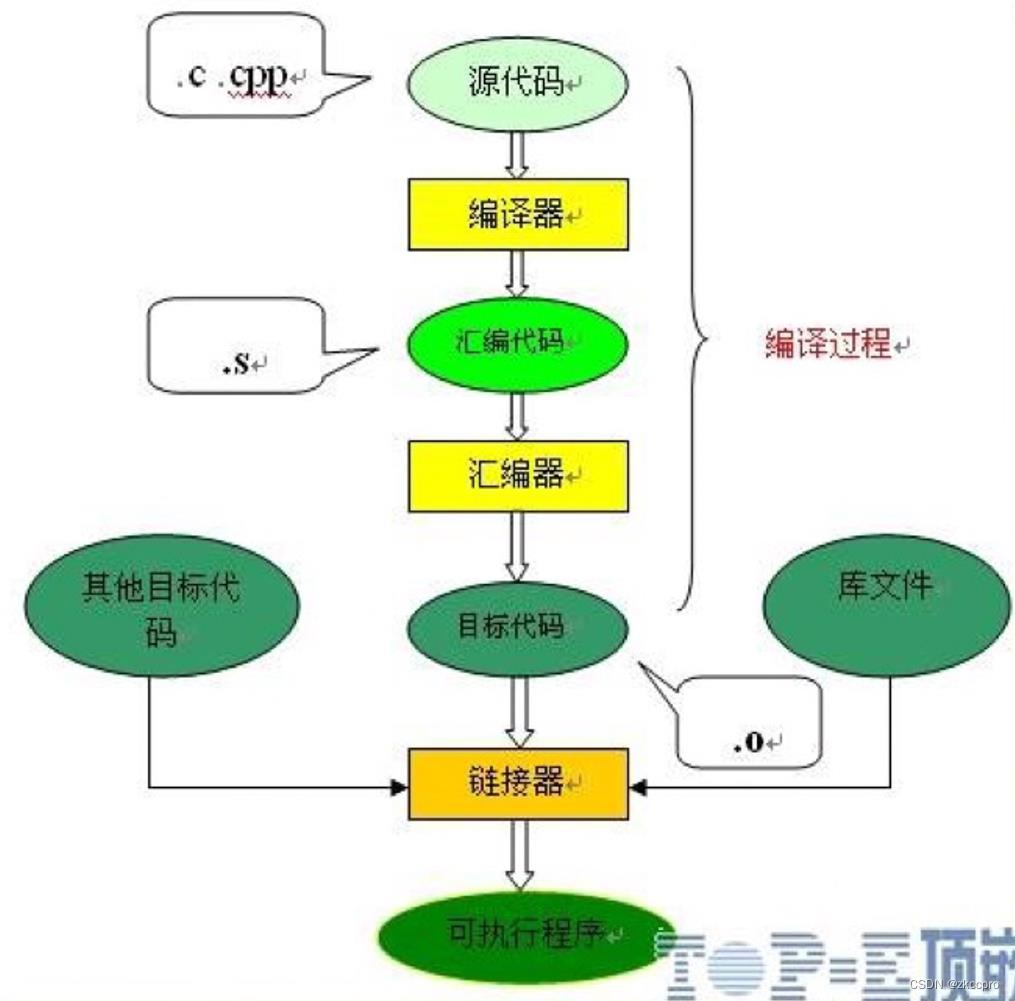
图1 c/c++程序从源文件都可执行文件的过程
记得在很久以前的笔记放过一张这个图,相信每一个c/c++程序员起码都对这张图了如指掌。今天我们讨论的话题是这个过程的第一个中间产物:汇编代码,编译器的输出结果。
2. 看懂基本的汇编语言
一条基本的汇编语言有两部分组成:操作码和操作数;而操作数又分为3种:立即数、寄存器、内存引用。
下面是一条基本的汇编指令:
mov %rdi,%rax
-
操作码
操作码代表指令的类型,常见的有:mov、add、sub、xor、push、pop、ret。。。
有些需要两个操作数,而有些只需要一个。
在实际汇编代码中经常看到操作码后面加上q、l后缀,比如
movq、movl等。这些后缀代表待操作的操作数长度:b(byte),操作数占1B;w(word),操作数占2B;l(long),操作数占4B;q,操作数占8B。 -
操作数
操作数,即指令操作的数据,分为3种:立即数,寄存器,内存引用。
立即数,比如:
$1。寄存器,比如:
%rdi。下面详细介绍64位cpu的寄存器组织。内存引用,比如:
(%rdi)。我理解 类似于c语言中的指针,括号里的寄存器存放一个内存地址,去内存中查找相应地址的内容。 -
寄存器
寄存器是汇编语言中存储变量、完成逻辑最常用的高速存储器了。不同cpu设计规范有着不同的寄存器组织。常见的64位cpu——x86-64处理器设计规范中有16个通用寄存器。其中8个在实现过程栈逻辑中常用的,了解以下这些暂时够用啦:
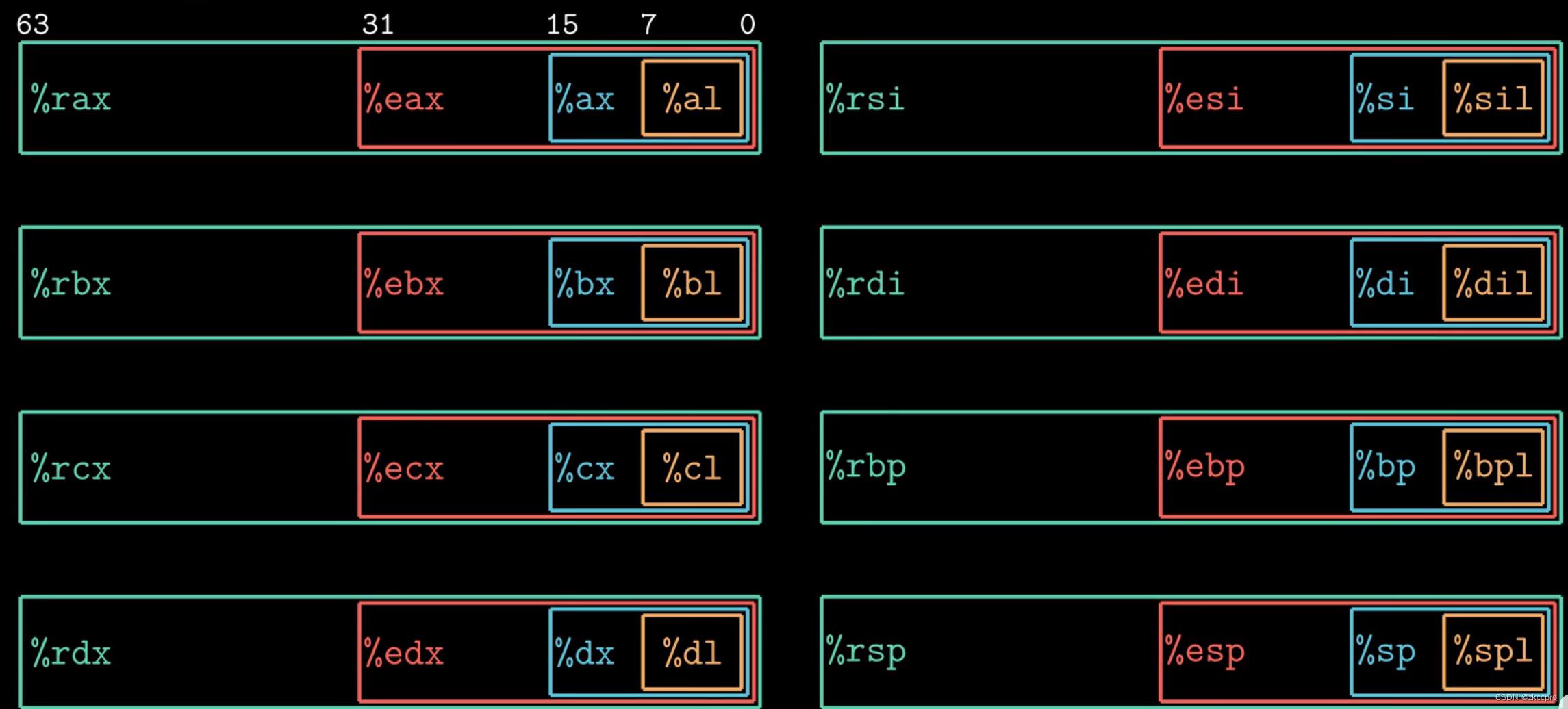
图2 cpu向汇编语言提供的寄存器组织(64位)
由上图,这些寄存器的低32位都是32位cpu的遗留,而如果想只使用高32位,需要这样表达,如:%rsi的高32位是%esx;%rdi的高32位是%edx。
二、 从汇编角度分析过程栈机制
1. 返回地址的压入与弹出(call、ret指令)
几乎所有高级语言都会有 函数 的概念,通过函数对可以复用的逻辑进行封装,可以使得程序书写更加简明规范。几乎任何程序员都知道函数调用的逻辑:当前函数调用另一函数时,当前函数将被“挂起”,转而执行被调用函数;待执行完毕后,会返回到刚刚执行的函数语句位置继续向下执行。 但这个逻辑在语言底层是怎么实现的呢?这是我们要搞懂的问题。下面以c/c++语言为例介绍一下经过编译后的汇编语言是如何实现过程调用逻辑的:
int func(int a,int b,int* c)
*c=a+b;
return *c;
int main()
int aa=1;
int bb=2;
int* pc;
int cc=func(aa,bb,pc);
写一个简单的调用,看看汇编之后的是什么样:
_Z4funciiPi:
pushq %rbp
省略一些...
popq %rbp
(执行完func函数后,ret指令即可跳转回原函数)
ret
main:
省略一些...
(这里call,即跳转到func函数)
call _Z4funciiPi
省略一些...
ret
可见,上述函数调用的逻辑是用call和ret指令实现的。下面分别剖析一下call和ret指令的具体作用:
-
call指令:
- 把被调用函数第一条指令的地址放入程序指令寄存器
%rip中,之后下一条指令将会按照%rip中地址执行。 - 把 返回地址 压入栈中。即,执行完被调用函数后接下来一条指令的地址,也就是原函数的下一条指令地址。
- 把被调用函数第一条指令的地址放入程序指令寄存器
-
ret指令:
- 将返回地址放入程序指令寄存器
%rip中,之后下一条指令将会按照%rip中地址执行。 - %rsp上移8B,将返回地址弹出。
如此就可以借助栈空间来完成函数的调用逻辑了!
- 将返回地址放入程序指令寄存器
2. 函数参数和自动变量的存储与传递
2.1函数参数和自动变量的存储
为了实现函数特定的功能,往往需要传入传出一些参数。原则上说,如果寄存器足够那么就不需要借助栈资源来存放传入参数或者自动变量,别忘了栈空间实际上是内存,所以寄存器的读写速度一定是比栈更快的。下面来看看实际情况:
-
向函数传入一个int:
movl %edi, -4(%rsp)可见在没有更高级别优化的前提下,向函数内传入一个参数也会占用栈资源。(跟用不用没关系)
-
函数内声明一个自动变量并使用它:
int func() int a; return a;//使用(返回)了为初始化的变量相关的汇编如下:
movl -4(%rsp), %eax popq %rbppop指令还没介绍,暂时可以这样理解上面的汇编:把
-4(%rsp)(当前栈指针低4B)存放的内容赋给%eax。pop会将%eax中的内容保存到当前栈帧外的寄存器%rbp中,作为返回值供上一级函数使用。可见,在没有更高级别优化的前提下,声明一个自动变量也会占用栈空间。当然了,这种写法犯了一个低级错误,返回的内容将是随机的,通过汇编代码更能理解为什么是这样了。因为我们根本没有清理-4(%rsp)位置的内容。而且没有任何机制可以自动清理栈的内容(将其置初始值什么的。。),都要依赖下次使用时自己手动初始化。可见,无论是函数参数还是自动变量,没有高级别优化的前提下都会占用栈空间。
2.2 函数参数的传递
我们看看函数参数是怎么传递的?方法也很简单,”栈是死的,寄存器是活的“——尽管栈有严格的机制保护其空间的使用,传递参数貌似很麻烦;但寄存器比栈的机制更为灵活,不受这种规则限制。因此,不论是参数的传入还是返回,都会依靠**”惯例寄存器“**先将其保存,然后再放到栈里使用。
下面是按照使用惯例常用寄存器的用途:
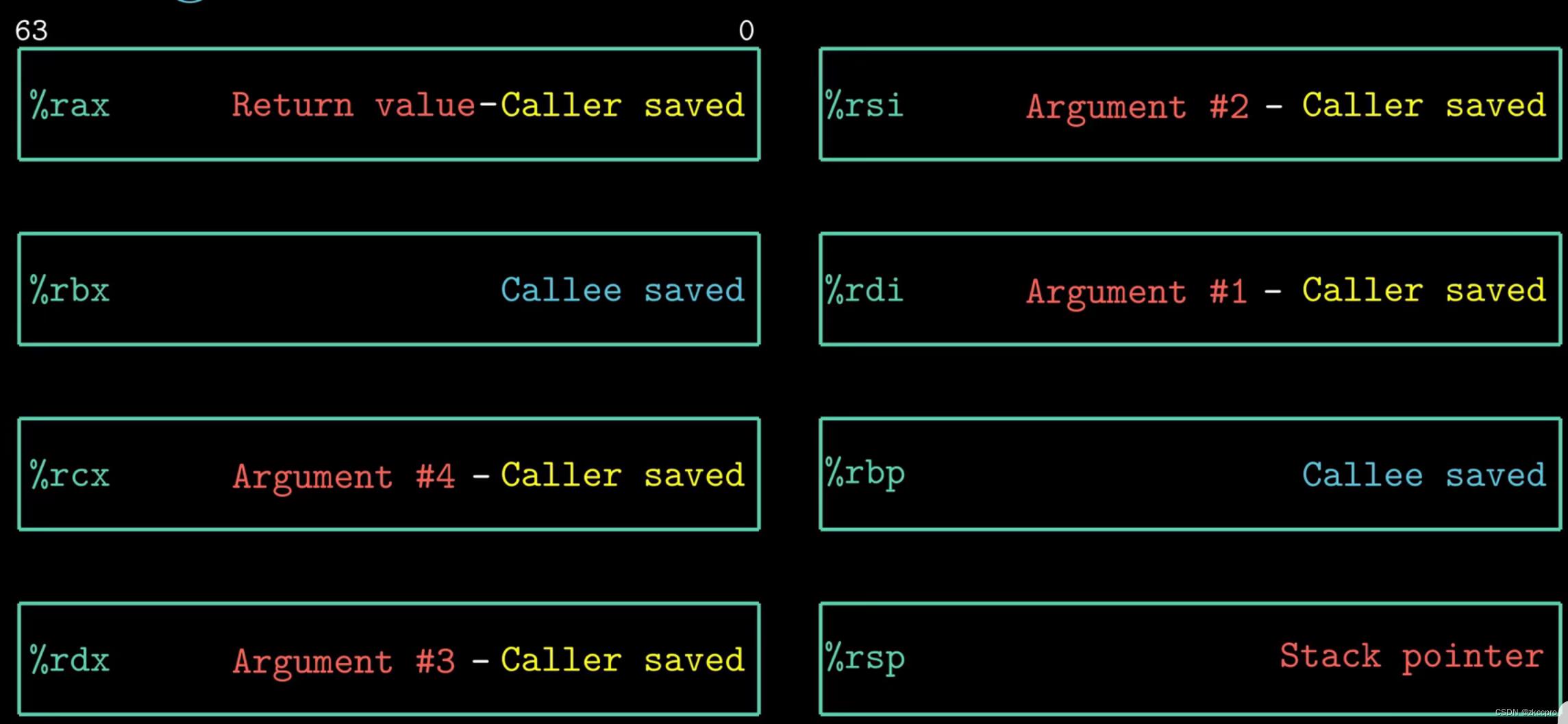
图3 部分惯例寄存器的用途
可见在使用惯例中,%rdi、%rsi、%rdx、%rcx分别用来存放传入函数的第1、2、3、4个参数。与传入类似,%rax用于返回栈内的变量。进入或返回目标函数后,接下来要做的事就是到这些惯例寄存器中取得内容,将其放到栈内,或者做其他事情即可!而%rbp和%rbx是被调用保存的寄存器,弹栈压栈操作可以借助这两个寄存器操作。
看到这里你可能会提出疑问,如果传入的参数个数不止4个怎么办?或者传入/返回的变量是一个巨大类型的拷贝,8B寄存器放不下怎么办?
对于传入参数过多的函数,就得不能依靠寄存器来作为函数之间的暂存了,只能使用栈空间来传递了。对于传入的变量过大且需要拷贝的情况,先依靠寄存器保存其地址,再将地址中的内容拷贝到栈里;而返回值就比较特殊了,还记得c++中的RVO优化吗?尽管看起来像是触发了返回值拷贝,但其实并没有真的拷贝,效率提高了不少。
3. 寄存器值的保存和恢复(push、pop指令)
了解参数是怎么在栈之间传递的,接下来就可以看看这种传递是靠什么实现的:
-
push指令:
push?顾名思义,就是把元素压栈嘛!push指令也是这样:
int func(int a) //...考虑最简单的情况,相关的汇编代码如下,
pushq %rbppushq指令做了2件事:
- 将栈指针
%rsp向低地址移动8B(因为是q嘛!) - 将寄存器
%rbp的内容存入%rsp指向的栈空间中。
也就是说,上面一条pushq指令,相当于下面2条:
subq $8,%rsp movq %rbp,(%rsp)为什么是往低地址呢?回忆一下操作系统的知识:虚拟地址空间的分布,执行过程中,栈是从高地址向低地址生长的嘛。
- 将栈指针
-
pop指令:
同样,就是把元素从栈中弹出:
int func(int a) //... return aa;返回 相关的汇编代码如下,
popq %rbx ret与pushq对应,popq指令做了2件事:
- 将栈指针
%rbp指向的内容移到%rbx寄存器中,供外层函数使用。 - 将栈指针
%rsp向高地址移动8B(因为是q嘛!)
一条popq指令,相当于下面2条:
movq (%rsp),%rbx addq $8,%rsppop之后就可以执行ret指令返回了。可见,在退栈时,真的没有任何机制把栈空间的内容复原的操作。因此,初始化内存的任务交给了下一次的栈调用。
- 将栈指针
以上是关于c语言过程栈机制详解的主要内容,如果未能解决你的问题,请参考以下文章