Linux配置Spark
Posted sunyanqinyin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux配置Spark相关的知识,希望对你有一定的参考价值。
下载预构建好的Spark压缩包
进入Spark官网下载页面下载你需要的安装包,这里我选择预构建好的、现在最新的压缩包-Download Spark: spark-2.3.2-bin-hadoop2.7.tgz
下载:wget https://www.apache.org/dyn/closer.lua/spark/spark-2.3.2/spark-2.3.2-bin-hadoop2.7.tgz
解压: tar zxvf spark-2.3.2-bin-hadoop2.7.tgz
添加环境变量
export PATH=$PATH:home/sy/spark-2.3.2-bin-hadoop2.7/bin
可以先进入解压后的目录,然后输入pwd获取当前目录
如果需要永久开机配置,在用户名目录下输入ls -a,有一个.bashrc文件,使用vi打开,添加环境变量如下:
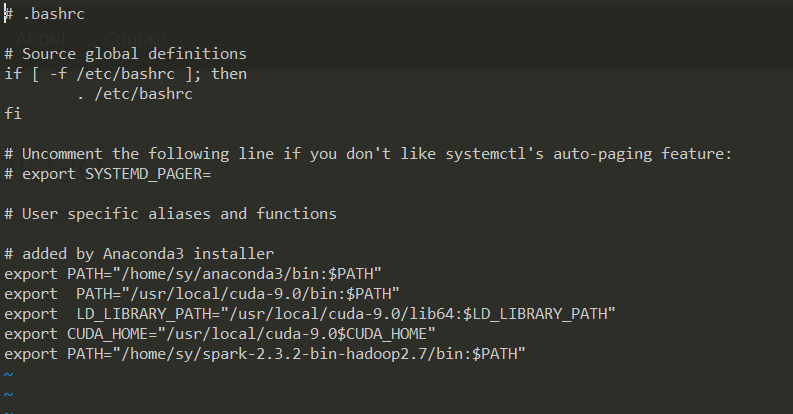
保存后,source .bashrc,使得环境变量立即生效。
Java环境
输入java -version,显示:
openjdk version "1.8.0_161"
OpenJDK Runtime Environment (build 1.8.0_161-b14)
OpenJDK 64-Bit Server VM (build 25.161-b14, mixed mode)说明java环境已经配置成功,如果没有的话,可能需要配置一下。
检查配置是否成功
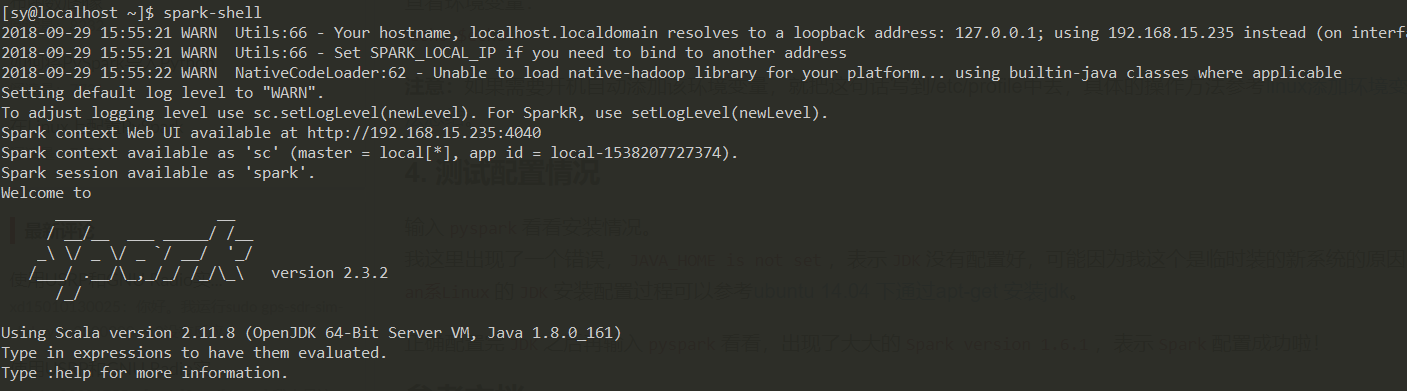
输入spark-shell,显示下面信息说明配置成功
安装pyspark
pip install pyspark
测试
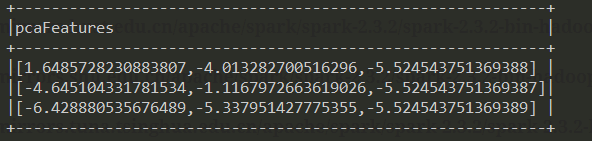
我们测试这个链接中的例子:https://github.com/apache/spark/blob/master/examples/src/main/python/ml/pca_example.py
新建pca.py文件,输入代码后执行python pca.py即可,输出如下:
以上是关于Linux配置Spark的主要内容,如果未能解决你的问题,请参考以下文章