linux常用命令
Posted xiayutianer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux常用命令相关的知识,希望对你有一定的参考价值。
1、创建用户/设置密码/文件所属组及权限
新增用户并指定宿主目录:useradd -d /home/haorong -g informix -G root -m haorong( -d:指定用户的主目录, -m:如果存在不再创建,但是此目录并不属于新创建用户;如果主目录不存在,则强制创建; -m和-d一块使用,-g:指定所属组,-G:指定除-g指定外的另一个组)
设置密码:Passwd haorong
彻底删除用户及宿主文件:userdel -rf testtest 只删除用户去掉rf
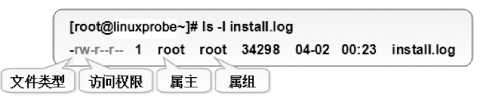

Chown informix:informix 文件名 修改属主及属组
Chmod 660 文件名 修改权限
2、清空文件的方法
:> filename
> filename
cat /dev/null > filename
上面这3种方式,能将文件清空,而且文件大小为0
而下面两种方式,导致文本都有一个"�",而是得文件大小为1
echo "" > filename
echo > filename
3、防火墙关闭和启动
Readhat6.x版本
查看防火墙状态:service iptables status
1) 重启后生效
开启: chkconfig iptables on
关闭: chkconfig iptables off
2) 即时生效,重启后失效
开启: service iptables start
关闭: service iptables stop
Readhat7.1版本
查看防火墙状态:systemctl status firewalld
临时关闭:systemctl stop firewalld
临时开启:systemctl start firewalld
永久关闭: systemctl disable firewalld
永久开启:systemctl enable firewalld
4、常用易记错命令
Cut
Cut -d “分割字符” -f fields(通常是数字)
Cut -c 字符范围 (以字符characters的单位取出固定字符区间)
举例:
Echo $PATH|cut -d “:” -f 5 取出分割完后的第5部分
Echo $PATH|cut -d “:” -f 3,,5 取出分割完后的第3、4、5部分
Echo $PATH|cut -d “:” -f 12- 取出分割完后的12及其后面所有部分
Grep
Grep [-acinv] [--color=auto] ‘查找字符串’ filename
-n:顺便输出行号
-v:反向选择,即显示出没有’查找字符串’内容的那一行
-R:一般用户filename是目录,递归对文件夹中所有文件进行搜索
以上三个常用
-a:将binary文件以text文件的方式查找数据
-c:计算找到’查找字符串’的次数
-i:忽略大小写的不同,所以大小写视为相同
--color=auto:可以将找到的关键字部分加上颜色显示
Sort
Sort -[fbMnrtuk] [file or stdin]
-r:反向排序
-u:就是uniq,相同的数据中,仅出现一行代表,去重
-t:分隔符,默认使用Tab键来分割
-k:以那个区间来进行排序的意思
-b:忽略最前面的空格符部分
-n:使用“纯数字”进行排序(默认是以文字类型来排序的)
-f:忽略大小写的差异
-M:以月份的名字来排序,例如JAN,DEC等的排序方法
Sort默认是“以第一个”数据来排序,那怎么以:来分割后以第三列来排序?
Cat /etc/passwd|sort -t ‘:’ -k 3
一般sort跟uniq一起用,举例(uniq -i:忽略大小写的不同,uniq -c进行计数):
Last|cut -d ‘ ’ -f1|sort|uniq (注意以空格分’ ’两个单引号里面得有个空格)
[[email protected] tmp]# last |cut -d ‘ ‘ -f1 |sort|uniq
reboot
root
wtmp
[[email protected] tmp]# last |cut -d ‘ ‘ -f1 |sort|uniq -c(加上-c会进行统计)
1
4 reboot
241 root
1 wtmp
sed
Sed -[nefr] 动作(动作说明:[n1],[n2] function)
Function有下面这些步骤:
a:新增,a后面可以接字符串,接的内容在当前行下一行
i:插入,同上,但是是当前行上一行
d:删除,因为是删除,所以d的后面通常不接任何参数
c:替换,c的后面可以接字符串,这些字符串可以替换n1,n2之间的行
p:打印,也就是将某个选择的数据打印出来,通常p会与参数sed -n一起运行
s:替换,可以直接进行替换的工作,通常这个s的动作可以搭配正则表达式,例 如1,20s/old/new/g
举例:
列出文件的2~5行(最常用)
[[email protected] tmp]# nl test.sh|sed -n ‘2,5p‘
2 jaogjaosgoagoag
3 set +e
4 start_time=20180401
5 end_time=20180630
删除3~5行
[[email protected] tmp]# nl test.sh |sed ‘3,5d‘
1 #!/bin/bash
2 jaogjaosgoagoag
6 datetime=${start_time}
在第二行后加上can you stop angry now?
[[email protected] tmp]# nl test.sh |sed ‘2a can you stop angry now?‘
1 #!/bin/bash
2 jaogjaosgoagoag
can you stop angry now?
3 set +e
4 start_time=20180401
5 end_time=20180630
6 datetime=${start_time}
替换3~4行为Yes,I can
[[email protected] tmp]# nl test.sh |sed ‘3,4c Yes,I can‘
1 #!/bin/bash
2 jaogjaosgoagoag
Yes,I can
5 end_time=20180630
6 datetime=${start_time}
Awk
Awk ‘条件类型{动作1} 条件类型{动作2 ..}’ filename
注意:awk处理每一行的字段内的数据,默认的字段的分隔符为空格键或Tab键
简单举例:
列出last的前三行:
[[email protected] tmp]# last -n 3
root pts/3 192.168.199.107 Sat Oct 13 19:24 still logged in
root pts/4 192.168.199.107 Sat Oct 13 18:05 still logged in
root pts/1 192.168.199.107 Thu Oct 11 22:00 - 20:03 (1+22:03)
若我想取出账号与登录者的IP,且账号与IP之间以Tab隔开:
[[email protected] tmp]# last -n 3|awk ‘{print $1 " " $3}‘
root 192.168.199.107
root 192.168.199.107
root 192.168.199.107
Awk内置变量
|
变量名称 |
代表意义 |
|
NF |
每一行{$0}拥有的字段总数 |
|
NR |
目前awk所处理的是“第几行”数据 |
|
FS |
目前的分割字符,默认是空格键 |
举例:
[[email protected] tmp]# last -n 5|awk ‘{print $1 " lines:" NR " columes:" NF }‘
root lines:1 columes:10
root lines:2 columes:10
root lines:3 columes:10
root lines:4 columes:10
root lines:5 columes:10
复杂实例:
If判断:onstat -g ntd|awk ‘{if($1=="Totals") print $3}‘
进行计算:onstat -g seg|grep Total|awk ‘{print $7/($7+$8)*100}‘
Awk -F重新定义分隔符:onstat -|awk -F "--" ‘{print $4}‘|awk ‘{print $1}‘
Begin和END:onstat -g ioq|awk ‘BEGIN{total = 0} {if($3 ~ /^[0-9]/) total = total + $3} END {print total}‘
匹配正则表达式并且加上函数substr和index:onstat -x | awk ‘if($5~ /:/) print substr($6,0,index($6,":")-1) - substr($5,0,index($5,":")-1)}‘ | sort -nr | head -n 1
index第一个参数是要求索引的整个字符串,第二个参数指定字符,结果是:在字符串$6中的索引值:
[[email protected] tmp]# last -n 1
root pts/3 192.168.199.107 Sat Oct 13 19:24 still logged in
[[email protected] tmp]# last|awk ‘{if(NR==1) print index($2,"/")}‘ NR是结果的第一行
4
Substr表示分割字符串,第一个参数是要被分割的字符串,第二个是开始索引,第三个是结束索引:
[[email protected] tmp]# last|awk ‘{if(NR==1) print substr($3,0,4)}‘
192.
Split
Split -[bl] 要分割的file [prefix]
-l:以行数来进行切割
-b:后面可接欲切割成的文件大小,可加单位,例如b,k,m等
Prefix:分割后产生的文件前缀
Xargs
onstat -g ras|grep -i rhead_t|awk ‘{print $2}‘|xargs -I {} onstat -g dmp {} rhead_t|grep sh_cpchk|awk ‘{print $3}
这里xargs -I的意思是将前面onstat -g ras|grep -i rhead_t|awk ‘{print $2}‘得到的结果传入给后面,假如前面的结果是0x000000004767f800,后面相等于是执行onstat -g dmp 0x000000004767f800 rhead_t|grep sh_cpchk|awk ‘{print $3}
xargs cmd 将标准输入输入的每一项作为参数执行一次cmd,
因此find . -name "*.c" | xargs grep main就是将find找到的每一个文件的名字用 grep main 来执行一下
5、文件系统,扩容
lvcreate –help
lvs
vgs
lvcreate -n datalv01 -L 2.45t datavg01
lvdisplay
mkfs.ext4 /dev/datavg01/datalv01
mkdir /data
mount /dev/datavg01/datalv01 /data
以上是关于linux常用命令的主要内容,如果未能解决你的问题,请参考以下文章