hadoop后端——使用java数据流配置
Posted 一 研 为定
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop后端——使用java数据流配置相关的知识,希望对你有一定的参考价值。
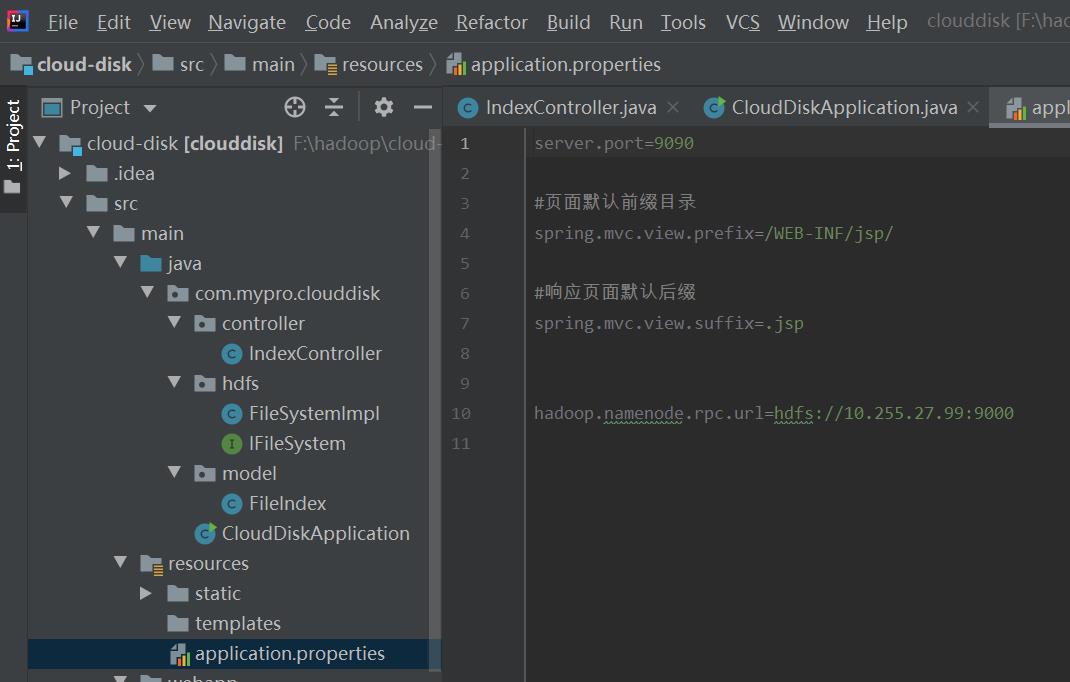
在做之前需要在application.properties写上自己虚拟机的ip号和端口号,并配置上如下代码,将上传文件的大小控制在500MB以内
spring.servlet.multipart.max-file-size=500MB
spring.servlet.multipart.max-request-size=500MB
1、mkdir创建文件夹
首先需要定义抽象类,然后配置namenode的地址,然后指定用户名,获取FileSystem对象,注意用户名一定要改成自己虚拟机的用户名,否则就不能成功。然后新建路径,起名为filePath,使用mkdir创建路径。
@Override
public void mkdir(String dir) throws Exception
Configuration conf=new Configuration();
//配置NameNode地址
URI uri=new URI(namenodeRpcUrl);
//指定用户名,获取FileSystem对象
FileSystem fs=FileSystem.get(uri,conf,"lu");
Path filePath = new Path(dir);
fs.mkdirs(filePath);
System.out.println("mkdir " + dir + " Successfully!");
2、upload上传(将本地文件上传到hdfs)
因为这次是将本地文件上传到hdfs,所以我们需要在hdfs上创建一个文件,将本地文件中的数据作为输入流上传到hdfs中。所以定义new_file文件,作为hdfs中的文件,定义一个FSDataOutputStream类,使用create函数创建一个空文件,复制流使用copyBytes,将本地文件中的数据复制到hdfs中创建的空文件中,最后使用closeSteam关闭数据流。
@Override
public void upload(InputStream is, String dstHDFSFile) throws Exception
//请实现本地文件上传到hdfs
Configuration conf=new Configuration();
//配置NameNode地址
URI uri=new URI(namenodeRpcUrl);
//指定用户名,获取FileSystem对象
FileSystem fs=FileSystem.get(uri,conf,"lu");
//Path,指定待操作的文件或路径
Path new_file = new Path(dstHDFSFile);
//创建hdfs上的文件
FSDataOutputStream dataOutputStream = fs.create(new_file,true);
//复制流
IOUtils.copyBytes(is,dataOutputStream,conf);
//关闭流
IOUtils.closeStream(dataOutputStream);
System.out.println( "Upload Successfully!" );
3、download下载(将hdfs中的文件下载到本地)
为实现hdfs中的文件下载到本地,首先应创建一个文件new_file,打开指定的文件,即打开new_file文件,然后使用copyBytes读文件,将数据读取到本地,最后关闭数据流。
@Override
public void download(String file, OutputStream os) throws Exception
//请实现,把读出来的数据流写在本地
Configuration conf=new Configuration();
//配置NameNode地址
URI uri=new URI(namenodeRpcUrl);
//指定用户名,获取FileSystem对象
FileSystem fs=FileSystem.get(uri,conf,"lu");
//Path,指定待操作的文件或路径
Path new_file = new Path(file);
//打开指定的文件,读文件
FSDataInputStream open = fs.open(new_file);
//读文件
IOUtils.copyBytes(open,os,conf);
IOUtils.closeStream(open);
System.out.println( "Download Successfully!" );
以上是关于hadoop后端——使用java数据流配置的主要内容,如果未能解决你的问题,请参考以下文章